Differentially Private Synthetic Data via Foundation Model APIs 2: Text

0

Sign in to get full access
Overview
- The provided paper explores the use of foundation model APIs to generate differentially private synthetic text data.
- Differentially private synthetic data aims to preserve the statistical properties of the original data while protecting individual privacy.
- The paper demonstrates how foundation models can be leveraged to generate high-quality synthetic text that satisfies differential privacy guarantees.
Plain English Explanation
Differentially private synthetic data is a technique that allows you to create new data that looks and behaves similarly to the original data, but without revealing any sensitive information about the individuals in the original data.
The key idea is to use powerful language models (called "foundation models") to generate this synthetic data. These models have been trained on massive amounts of text data, so they can produce new text that seems realistic and coherent.
By carefully controlling how the model is used, the researchers were able to ensure that the synthetic data satisfies differential privacy - a strong privacy guarantee that limits what an adversary can learn about the original data. This makes the synthetic data safe to use in situations where the original data might be sensitive or confidential.
The paper demonstrates that this approach can generate high-quality synthetic text data that preserves many of the statistical properties of the original data, while providing strong privacy protections. This could be useful in a wide range of applications, such as privacy-preserving data sharing or training machine learning models without exposing sensitive information.
Technical Explanation
The paper presents a method for generating differentially private synthetic text data using foundation model APIs. The key steps are:
-
Obtain a pre-trained language model: The researchers use a large, general-purpose language model (such as GPT-3) that has been trained on a vast corpus of text data.
-
Fine-tune the model on the target dataset: The pre-trained model is further fine-tuned on the specific dataset that the researchers want to generate synthetic data for. This ensures the synthetic data will have similar statistical properties to the original data.
-
Inject differential privacy: The fine-tuned model is then modified to satisfy differential privacy. This is done by carefully calibrating the model's parameters and the sampling process to introduce controlled amounts of noise, which limits what an adversary can infer about the original data.
-
Generate synthetic text: The differentially private model is then used to generate new text samples, which serve as the synthetic data. These samples preserve many of the linguistic and statistical properties of the original data, while providing strong privacy guarantees.
The paper evaluates this approach on several real-world text datasets, measuring the quality of the synthetic data in terms of its utility for downstream tasks as well as its privacy properties. The results demonstrate that the method can generate high-quality synthetic text that satisfies differential privacy.
Critical Analysis
The paper makes a strong case for the utility of differentially private synthetic data generation using foundation model APIs. The approach is well-designed and the experimental results are promising.
However, it's important to note that the method relies on the availability of a high-quality pre-trained language model, which may not be readily accessible for all use cases. Additionally, the fine-tuning and differential privacy injection processes can be computationally intensive, which could limit the scalability of the approach.
It would also be valuable to see further analysis of the potential biases or artifacts that may be introduced into the synthetic data, and how these might impact its usefulness in different application scenarios. The paper briefly mentions these considerations, but more in-depth exploration could be beneficial.
Overall, the research presented in this paper represents an important step forward in the field of privacy-preserving data synthesis. The use of foundation models provides a powerful tool for generating realistic synthetic data, and the differential privacy guarantees help to address critical privacy concerns. As the techniques continue to evolve, they could have significant implications for a wide range of data-driven applications.
Conclusion
This paper demonstrates a novel approach for generating differentially private synthetic text data using foundation model APIs. By leveraging the powerful language modeling capabilities of large pre-trained models and carefully injecting differential privacy, the researchers were able to create high-quality synthetic data that preserves the statistical properties of the original data while providing strong privacy guarantees.
The work has important implications for a range of applications, including privacy-preserving data sharing, machine learning model training, and other scenarios where sensitive data needs to be used or shared. As the field of differential privacy and synthetic data generation continues to evolve, techniques like the one presented in this paper could become increasingly valuable tools for balancing data utility and individual privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Chulin Xie, Zinan Lin, Arturs Backurs, Sivakanth Gopi, Da Yu, Huseyin A Inan, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, Bo Li, Sergey Yekhanin
Text data has become extremely valuable due to the emergence of machine learning algorithms that learn from it. A lot of high-quality text data generated in the real world is private and therefore cannot be shared or used freely due to privacy concerns. Generating synthetic replicas of private text data with a formal privacy guarantee, i.e., differential privacy (DP), offers a promising and scalable solution. However, existing methods necessitate DP finetuning of large language models (LLMs) on private data to generate DP synthetic data. This approach is not viable for proprietary LLMs (e.g., GPT-3.5) and also demands considerable computational resources for open-source LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE) algorithm to generate DP synthetic images with only API access to diffusion models. In this work, we propose an augmented PE algorithm, named Aug-PE, that applies to the complex setting of text. We use API access to an LLM and generate DP synthetic text without any model training. We conduct comprehensive experiments on three benchmark datasets. Our results demonstrate that Aug-PE produces DP synthetic text that yields competitive utility with the SOTA DP finetuning baselines. This underscores the feasibility of relying solely on API access of LLMs to produce high-quality DP synthetic texts, thereby facilitating more accessible routes to privacy-preserving LLM applications. Our code and data are available at https://github.com/AI-secure/aug-pe.
Read more7/25/2024

0
PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
Charlie Hou, Akshat Shrivastava, Hongyuan Zhan, Rylan Conway, Trang Le, Adithya Sagar, Giulia Fanti, Daniel Lazar
On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($epsilon=1.29$, $epsilon=7.58$). We achieve these results while using 9$times$ fewer rounds, 6$times$ less client computation per round, and 100$times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.
Read more7/19/2024

0
Private prediction for large-scale synthetic text generation
Kareem Amin, Alex Bie, Weiwei Kong, Alexey Kurakin, Natalia Ponomareva, Umar Syed, Andreas Terzis, Sergei Vassilvitskii
We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
Read more7/18/2024
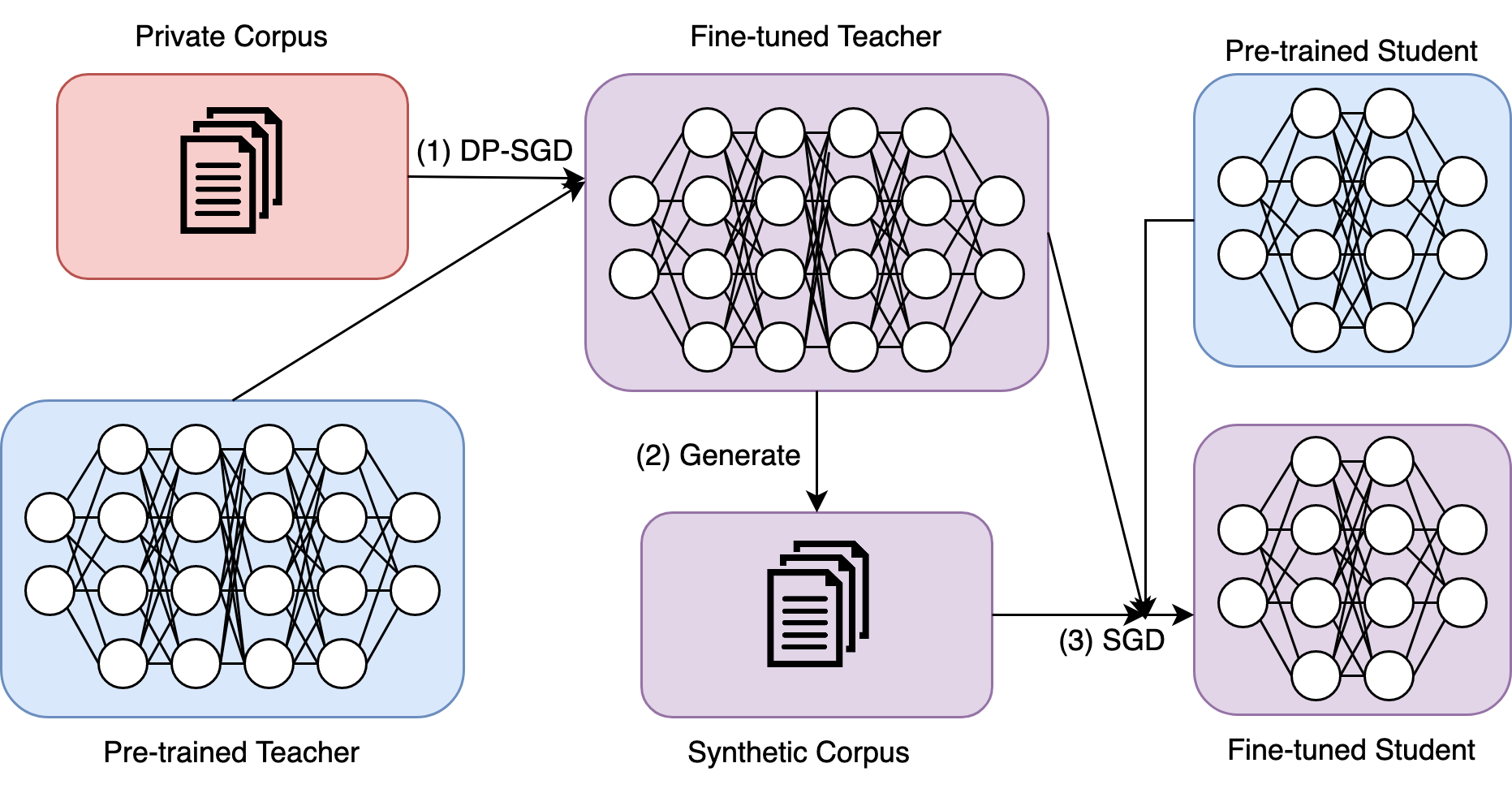
0
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
Read more6/6/2024