DiffNorm: Self-Supervised Normalization for Non-autoregressive Speech-to-speech Translation

0
🏋️
Sign in to get full access
Overview
- Non-autoregressive Transformers (NATs) are a type of machine learning model that can translate speech directly between languages without the need for intermediate text data.
- While NATs can generate high-quality outputs and perform faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to the complex data distribution in speech.
- This paper introduces DiffNorm, a diffusion-based normalization strategy, and classifier-free guidance to address these issues and improve the performance of NAT models for speech-to-speech translation.
Plain English Explanation
Non-autoregressive Transformers (NATs) are a type of machine learning model that can directly translate speech from one language to another without going through written text as an intermediate step. This is a useful capability, as it allows for faster and more efficient speech-to-speech translation.
However, the complex nature of speech data, which can vary widely in terms of acoustic properties and linguistic features, can cause issues for NAT models. They tend to produce translations that are incoherent and repetitive, due to the difficulty in learning the underlying patterns in the data.
To address these challenges, the researchers in this paper propose two key strategies:
-
DiffNorm: This is a technique that uses diffusion models to "normalize" the speech data, making it easier for the NAT model to learn. By applying a process of synthetic corruption and denoising, the data is transformed into a simpler, more uniform format that the model can better understand.
-
Classifier-free Guidance: This is a way of regularizing the NAT model during training, to make it more robust and produce higher-quality translations. The model is trained to generate translations without having full access to the source speech, forcing it to learn more generalizable patterns.
By incorporating these techniques, the researchers were able to significantly improve the performance of NAT models on speech-to-speech translation tasks, achieving notable gains in translation quality while also attaining much faster inference speeds compared to traditional autoregressive models.
Technical Explanation
The key technical aspects of this paper are as follows:
-
DiffNorm: The researchers use a diffusion-based normalization strategy to simplify the complex data distribution in speech. They train a self-supervised noise estimation model to learn how to denoise synthetically corrupted speech features, effectively constructing normalized target data for the NAT model to learn from. This helps the NAT model better capture the underlying patterns in the speech data.
-
Classifier-free Guidance: To further improve the robustness and translation quality of the NAT model, the researchers propose a regularization technique called classifier-free guidance. During training, the model is randomly given incomplete source information, forcing it to learn more generalizable representations that can handle missing or corrupted input data.
-
Experiments and Results: The researchers evaluated their proposed strategies on the CVSS benchmark for English-Spanish and English-French speech-to-speech translation tasks. Their approach resulted in a notable improvement of about +7 ASR-BLEU for English-Spanish and +2 ASR-BLEU for English-French translations, while also achieving over 14x and 5x speedup, respectively, compared to autoregressive baselines.
Critical Analysis
The researchers have addressed a significant challenge in the field of speech-to-speech translation by proposing effective strategies to improve the performance of Non-autoregressive Transformers (NATs). The use of DiffNorm and classifier-free guidance is a novel and promising approach, as it helps the model better handle the complex data distribution in speech.
However, the paper could have delved deeper into the limitations and potential drawbacks of their approach. For example, it's unclear how the proposed techniques would scale to larger and more diverse speech datasets, or how they would perform in real-world scenarios with noisy or low-quality input speech. Additionally, the paper could have discussed the potential computational and memory overhead associated with the diffusion-based normalization process.
Furthermore, the researchers could have compared their approach to other recent advancements in speech recognition and speech-to-speech translation, to better situate their work within the broader context of the field.
Overall, the researchers have made a valuable contribution by addressing a critical challenge in speech-to-speech translation using innovative techniques. However, further investigation into the limitations and potential areas for improvement would strengthen the impact of this work.
Conclusion
This paper introduces a novel approach to improving the performance of Non-autoregressive Transformers (NATs) for speech-to-speech translation tasks. By incorporating DiffNorm, a diffusion-based normalization strategy, and classifier-free guidance, the researchers were able to significantly enhance the coherence and quality of the translations produced by NAT models, while also attaining much faster inference speeds compared to traditional autoregressive models.
These advancements have important implications for the development of efficient and robust speech-to-speech translation systems, which can be crucial in a wide range of applications, from language learning to real-time communication and collaboration across linguistic barriers. By addressing the complex data distribution challenges inherent in speech, the researchers have paved the way for further progress in this important field of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
DiffNorm: Self-Supervised Normalization for Non-autoregressive Speech-to-speech Translation
Weiting Tan, Jingyu Zhang, Lingfeng Shen, Daniel Khashabi, Philipp Koehn
Non-autoregressive Transformers (NATs) are recently applied in direct speech-to-speech translation systems, which convert speech across different languages without intermediate text data. Although NATs generate high-quality outputs and offer faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to complex data distribution (e.g., acoustic and linguistic variations in speech). In this work, we introduce DiffNorm, a diffusion-based normalization strategy that simplifies data distributions for training NAT models. After training with a self-supervised noise estimation objective, DiffNorm constructs normalized target data by denoising synthetically corrupted speech features. Additionally, we propose to regularize NATs with classifier-free guidance, improving model robustness and translation quality by randomly dropping out source information during training. Our strategies result in a notable improvement of about +7 ASR-BLEU for English-Spanish (En-Es) and +2 ASR-BLEU for English-French (En-Fr) translations on the CVSS benchmark, while attaining over 14x speedup for En-Es and 5x speedup for En-Fr translations compared to autoregressive baselines.
Read more5/24/2024

0
Revisiting Non-Autoregressive Transformers for Efficient Image Synthesis
Zanlin Ni, Yulin Wang, Renping Zhou, Jiayi Guo, Jinyi Hu, Zhiyuan Liu, Shiji Song, Yuan Yao, Gao Huang
The field of image synthesis is currently flourishing due to the advancements in diffusion models. While diffusion models have been successful, their computational intensity has prompted the pursuit of more efficient alternatives. As a representative work, non-autoregressive Transformers (NATs) have been recognized for their rapid generation. However, a major drawback of these models is their inferior performance compared to diffusion models. In this paper, we aim to re-evaluate the full potential of NATs by revisiting the design of their training and inference strategies. Specifically, we identify the complexities in properly configuring these strategies and indicate the possible sub-optimality in existing heuristic-driven designs. Recognizing this, we propose to go beyond existing methods by directly solving the optimal strategies in an automatic framework. The resulting method, named AutoNAT, advances the performance boundaries of NATs notably, and is able to perform comparably with the latest diffusion models at a significantly reduced inference cost. The effectiveness of AutoNAT is validated on four benchmark datasets, i.e., ImageNet-256 & 512, MS-COCO, and CC3M. Our code is available at https://github.com/LeapLabTHU/ImprovedNAT.
Read more6/11/2024
🌀
0
What Have We Achieved on Non-autoregressive Translation?
Yafu Li, Huajian Zhang, Jianhao Yan, Yongjing Yin, Yue Zhang
Recent advances have made non-autoregressive (NAT) translation comparable to autoregressive methods (AT). However, their evaluation using BLEU has been shown to weakly correlate with human annotations. Limited research compares non-autoregressive translation and autoregressive translation comprehensively, leaving uncertainty about the true proximity of NAT to AT. To address this gap, we systematically evaluate four representative NAT methods across various dimensions, including human evaluation. Our empirical results demonstrate that despite narrowing the performance gap, state-of-the-art NAT still underperforms AT under more reliable evaluation metrics. Furthermore, we discover that explicitly modeling dependencies is crucial for generating natural language and generalizing to out-of-distribution sequences.
Read more5/22/2024
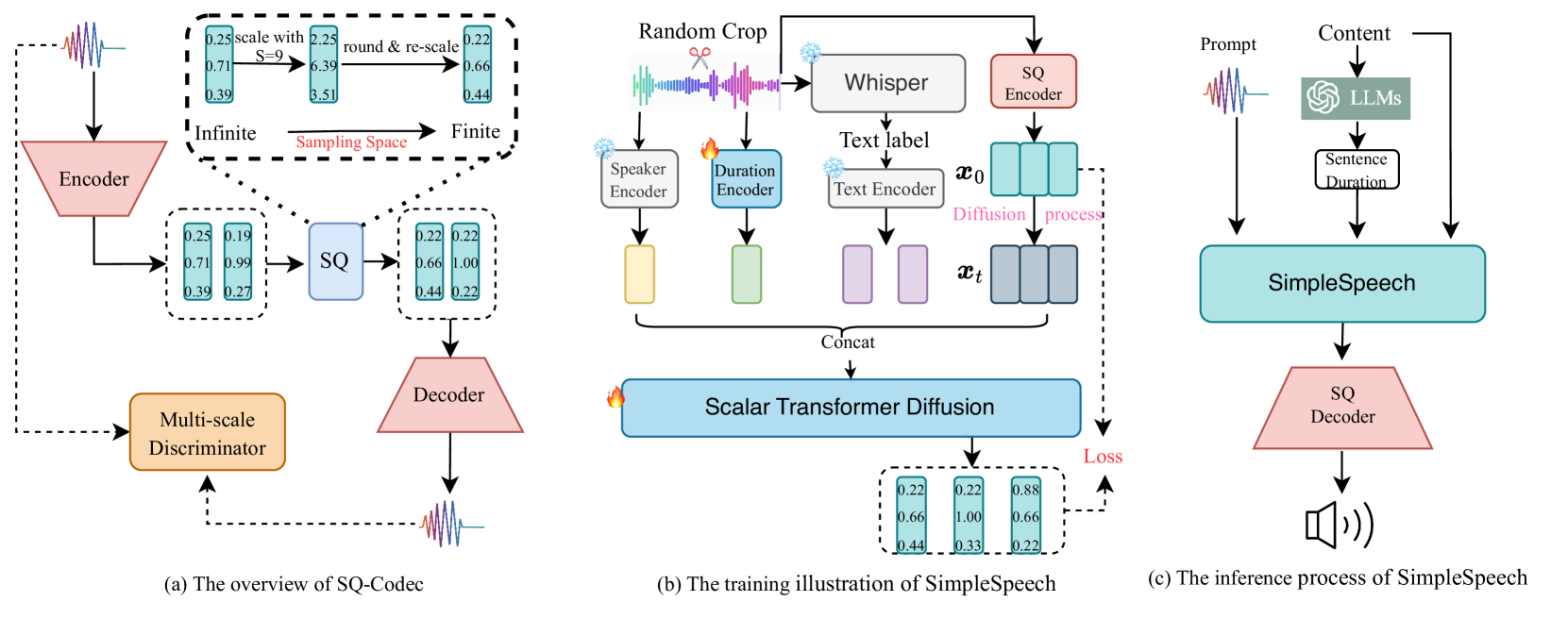
0
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
Read more6/17/2024