A Diffusion Model Framework for Unsupervised Neural Combinatorial Optimization
2406.01661
0
0
Abstract
Learning to sample from intractable distributions over discrete sets without relying on corresponding training data is a central problem in a wide range of fields, including Combinatorial Optimization. Currently, popular deep learning-based approaches rely primarily on generative models that yield exact sample likelihoods. This work introduces a method that lifts this restriction and opens the possibility to employ highly expressive latent variable models like diffusion models. Our approach is conceptually based on a loss that upper bounds the reverse Kullback-Leibler divergence and evades the requirement of exact sample likelihoods. We experimentally validate our approach in data-free Combinatorial Optimization and demonstrate that our method achieves a new state-of-the-art on a wide range of benchmark problems.
Create account to get full access
Overview
- This paper introduces a diffusion model framework for unsupervised neural combinatorial optimization.
- Diffusion models are a type of generative model that learn to transform simple distributions into more complex ones through a gradual diffusion process.
- The authors apply this approach to combinatorial optimization problems, which involve finding the best solution from a discrete set of possibilities.
- The proposed framework can be used to solve a variety of combinatorial optimization tasks in an unsupervised manner, without requiring labeled training data.
Plain English Explanation
Combinatorial optimization problems are challenging tasks that involve finding the best solution from a large number of possible choices. These problems arise in many real-world situations, such as scheduling, routing, and network design. Traditional methods for solving these problems often rely on hand-crafted algorithms that can be complex and time-consuming to develop.
In this paper, the authors propose using a diffusion model framework to tackle combinatorial optimization problems in an unsupervised way. Diffusion models work by gradually transforming a simple distribution, like a Gaussian, into a more complex one that resembles the desired solution. By learning this transformation, the model can then be used to generate high-quality solutions to the optimization problem.
The key advantage of this approach is that it doesn't require any labeled training data, which can be difficult to obtain for many real-world combinatorial optimization tasks. Instead, the model can be trained solely on the problem definition, without needing to know the optimal solutions ahead of time. This makes the method more flexible and easier to apply to a wider range of problems.
Technical Explanation
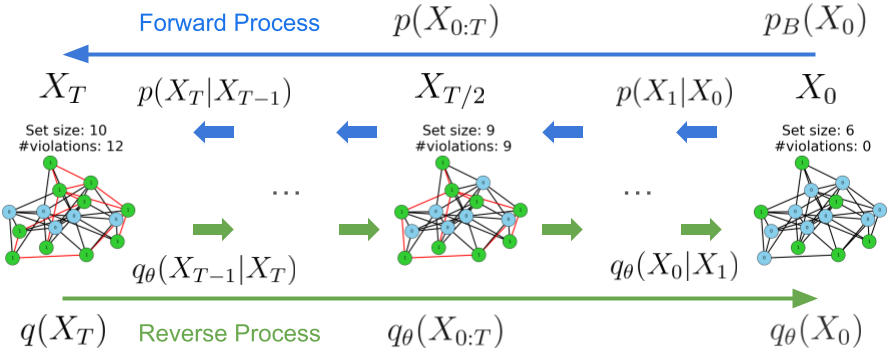
The authors propose a diffusion model framework for unsupervised neural combinatorial optimization. Diffusion models learn to transform a simple distribution, like a Gaussian, into a more complex distribution that matches the desired data distribution. In this case, the goal is to transform the simple distribution into one that corresponds to high-quality solutions to the combinatorial optimization problem.
The key components of the framework are:
- Diffusion Process: The diffusion process gradually adds noise to the initial simple distribution, transforming it into a more complex one over multiple steps.
- Inference Model: This neural network learns to reverse the diffusion process, gradually removing the noise to generate high-quality solutions.
- Loss Function: The model is trained to minimize the difference between the generated solutions and the true optimal solutions, even though the latter are not directly observed during training.
The authors demonstrate the effectiveness of this approach on several combinatorial optimization tasks, including the Traveling Salesman Problem and the Maximum Cut problem. They show that the diffusion model framework can achieve state-of-the-art performance on these problems in an unsupervised manner, without requiring any labeled training data.
Critical Analysis
The diffusion model framework presented in this paper is a promising approach for tackling combinatorial optimization problems in an unsupervised way. By leveraging the flexibility of diffusion models, the method can be applied to a wide range of optimization tasks without the need for labeled training data, which is a significant advantage over many existing techniques.
However, the paper does not address some potential limitations of the approach. For example, the authors do not discuss the computational complexity of the diffusion process or the inference model, which could be a bottleneck for larger-scale problems. Additionally, the paper does not explore the robustness of the method to noise or perturbations in the problem definition, which is an important consideration for real-world applications.
Furthermore, the authors could have provided a more in-depth analysis of the strengths and weaknesses of the diffusion model framework compared to other unsupervised optimization techniques, such as reinforcement learning or evolutionary algorithms. This would help readers better understand the unique advantages and potential limitations of the proposed approach.
Conclusion
This paper introduces a diffusion model framework for unsupervised neural combinatorial optimization, which represents a promising new direction for tackling challenging optimization problems. By learning to transform simple distributions into complex ones that correspond to high-quality solutions, the method can generate solutions without requiring any labeled training data.
The authors demonstrate the effectiveness of this approach on several benchmark combinatorial optimization tasks, achieving state-of-the-art performance in an unsupervised manner. While the paper does not address all potential limitations of the method, it provides a solid foundation for further research and development in this area. As diffusion models continue to advance, the application of these techniques to combinatorial optimization could lead to significant breakthroughs in solving real-world problems more efficiently and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Diffusion Models as Constrained Samplers for Optimization with Unknown Constraints
Lingkai Kong, Yuanqi Du, Wenhao Mu, Kirill Neklyudov, Valentin De Bortoli, Haorui Wang, Dongxia Wu, Aaron Ferber, Yi-An Ma, Carla P. Gomes, Chao Zhang
0
0
Addressing real-world optimization problems becomes particularly challenging when analytic objective functions or constraints are unavailable. While numerous studies have addressed the issue of unknown objectives, limited research has focused on scenarios where feasibility constraints are not given explicitly. Overlooking these constraints can lead to spurious solutions that are unrealistic in practice. To deal with such unknown constraints, we propose to perform optimization within the data manifold using diffusion models. To constrain the optimization process to the data manifold, we reformulate the original optimization problem as a sampling problem from the product of the Boltzmann distribution defined by the objective function and the data distribution learned by the diffusion model. To enhance sampling efficiency, we propose a two-stage framework that begins with a guided diffusion process for warm-up, followed by a Langevin dynamics stage for further correction. Theoretical analysis shows that the initial stage results in a distribution focused on feasible solutions, thereby providing a better initialization for the later stage. Comprehensive experiments on a synthetic dataset, six real-world black-box optimization datasets, and a multi-objective optimization dataset show that our method achieves better or comparable performance with previous state-of-the-art baselines.
5/1/2024
Improved sampling via learned diffusions
Lorenz Richter, Julius Berner
0
0
Recently, a series of papers proposed deep learning-based approaches to sample from target distributions using controlled diffusion processes, being trained only on the unnormalized target densities without access to samples. Building on previous work, we identify these approaches as special cases of a generalized Schrodinger bridge problem, seeking a stochastic evolution between a given prior distribution and the specified target. We further generalize this framework by introducing a variational formulation based on divergences between path space measures of time-reversed diffusion processes. This abstract perspective leads to practical losses that can be optimized by gradient-based algorithms and includes previous objectives as special cases. At the same time, it allows us to consider divergences other than the reverse Kullback-Leibler divergence that is known to suffer from mode collapse. In particular, we propose the so-called log-variance loss, which exhibits favorable numerical properties and leads to significantly improved performance across all considered approaches.
5/24/2024
✅
Physics-Informed Diffusion Models
Jan-Hendrik Bastek, WaiChing Sun, Dennis M. Kochmann
0
0
Generative models such as denoising diffusion models are quickly advancing their ability to approximate highly complex data distributions. They are also increasingly leveraged in scientific machine learning, where samples from the implied data distribution are expected to adhere to specific governing equations. We present a framework to inform denoising diffusion models of underlying constraints on such generated samples during model training. Our approach improves the alignment of the generated samples with the imposed constraints and significantly outperforms existing methods without affecting inference speed. Additionally, our findings suggest that incorporating such constraints during training provides a natural regularization against overfitting. Our framework is easy to implement and versatile in its applicability for imposing equality and inequality constraints as well as auxiliary optimization objectives.
5/24/2024
🧠
Neural Diffusion Models
Grigory Bartosh, Dmitry Vetrov, Christian A. Naesseth
0
0
Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
6/4/2024