DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
2405.18428
0
0

Abstract
Diffusion models with large-scale pre-training have achieved significant success in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, DiT models have faced challenges with scalability and quadratic complexity efficiency. In this paper, we aim to leverage the long sequence modeling capability of Gated Linear Attention (GLA) Transformers, expanding its applicability to diffusion models. We introduce Diffusion Gated Linear Attention Transformers (DiG), a simple, adoptable solution with minimal parameter overhead, following the DiT design, but offering superior efficiency and effectiveness. In addition to better performance than DiT, DiG-S/2 exhibits $2.5times$ higher training speed than DiT-S/2 and saves $75.7%$ GPU memory at a resolution of $1792 times 1792$. Moreover, we analyze the scalability of DiG across a variety of computational complexity. DiG models, with increased depth/width or augmentation of input tokens, consistently exhibit decreasing FID. We further compare DiG with other subquadratic-time diffusion models. With the same model size, DiG-XL/2 is $4.2times$ faster than the recent Mamba-based diffusion model at a $1024$ resolution, and is $1.8times$ faster than DiT with CUDA-optimized FlashAttention-2 under the $2048$ resolution. All these results demonstrate its superior efficiency among the latest diffusion models. Code is released at https://github.com/hustvl/DiG.
Create account to get full access
Overview
- The paper "DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention" proposes a new diffusion model architecture called DiG that aims to improve the scalability and efficiency of diffusion models for image generation.
- The key innovations of DiG include the use of gated linear attention (GLA) modules, which enable efficient long-range interactions, and a scalable design that allows the model to handle high-resolution images.
- The authors demonstrate that DiG outperforms existing diffusion models in terms of sample quality and computational efficiency on various image generation benchmarks.
Plain English Explanation
The paper discusses a new type of machine learning model called a "diffusion model" that can be used to generate images. Diffusion models work by taking a random noise image and gradually transforming it into a realistic-looking image through a series of steps. The researchers behind this paper have developed a new version of a diffusion model called "DiG" that has some key improvements.
First, DiG uses a special type of attention mechanism called "gated linear attention" that allows the model to efficiently capture long-range relationships between different parts of the image. This helps the model generate more coherent and realistic-looking images.
Second, DiG has been designed in a way that makes it scalable to high-resolution images. Many existing diffusion models struggle to work with large, high-quality images, but the researchers have found a way to make DiG work well even with very detailed and complex images.
The results show that DiG outperforms other state-of-the-art diffusion models in terms of the quality of the images it can generate, as well as how efficiently it can do so. This suggests that DiG could be a valuable tool for applications like photo editing, computer-generated art, and even video game development, where high-quality image generation is important.
Technical Explanation
The paper introduces a new diffusion model architecture called "DiG" that aims to address the scalability and efficiency limitations of existing diffusion models. The key innovations of DiG include:
-
Gated Linear Attention (GLA): DiG uses a novel attention mechanism called GLA, which the authors show is more computationally efficient than standard attention while maintaining the ability to capture long-range dependencies in the image. This helps DiG generate higher-quality images compared to prior work.
-
Scalable Design: The researchers have designed DiG in a way that allows it to handle high-resolution images, unlike many existing diffusion models that struggle with large, detailed images. This is achieved through a hierarchical structure and other architectural choices.
The authors evaluate DiG on several image generation benchmarks, including CIFAR-10, ImageNet, and LSUN. They show that DiG outperforms other state-of-the-art diffusion models in terms of sample quality and computational efficiency. Additionally, the authors provide an extensive ablation study to analyze the contributions of different components of the DiG architecture.
Critical Analysis
The paper provides a thorough evaluation of the DiG model and its performance compared to other diffusion models. However, the authors do not discuss any significant limitations or caveats of their approach. For example, it would be interesting to understand how DiG performs on more challenging or diverse image datasets, or how it compares to other generative modeling approaches beyond diffusion models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs).
Additionally, the paper does not explore the potential biases or fairness implications of the DiG model, which is an important consideration for any generative modeling system. Further research could investigate these aspects to better understand the broader implications of the proposed approach.
Conclusion
The "DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention" paper presents a novel diffusion model architecture that addresses key limitations of existing approaches. By incorporating gated linear attention and a scalable design, the authors demonstrate that DiG can generate high-quality images more efficiently than prior diffusion models.
The improvements in sample quality and computational efficiency shown by DiG suggest that it could be a valuable tool for a wide range of image-related applications, from photo editing to computer-generated art. As the field of generative modeling continues to advance, research like this can help push the boundaries of what is possible and unlock new creative and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
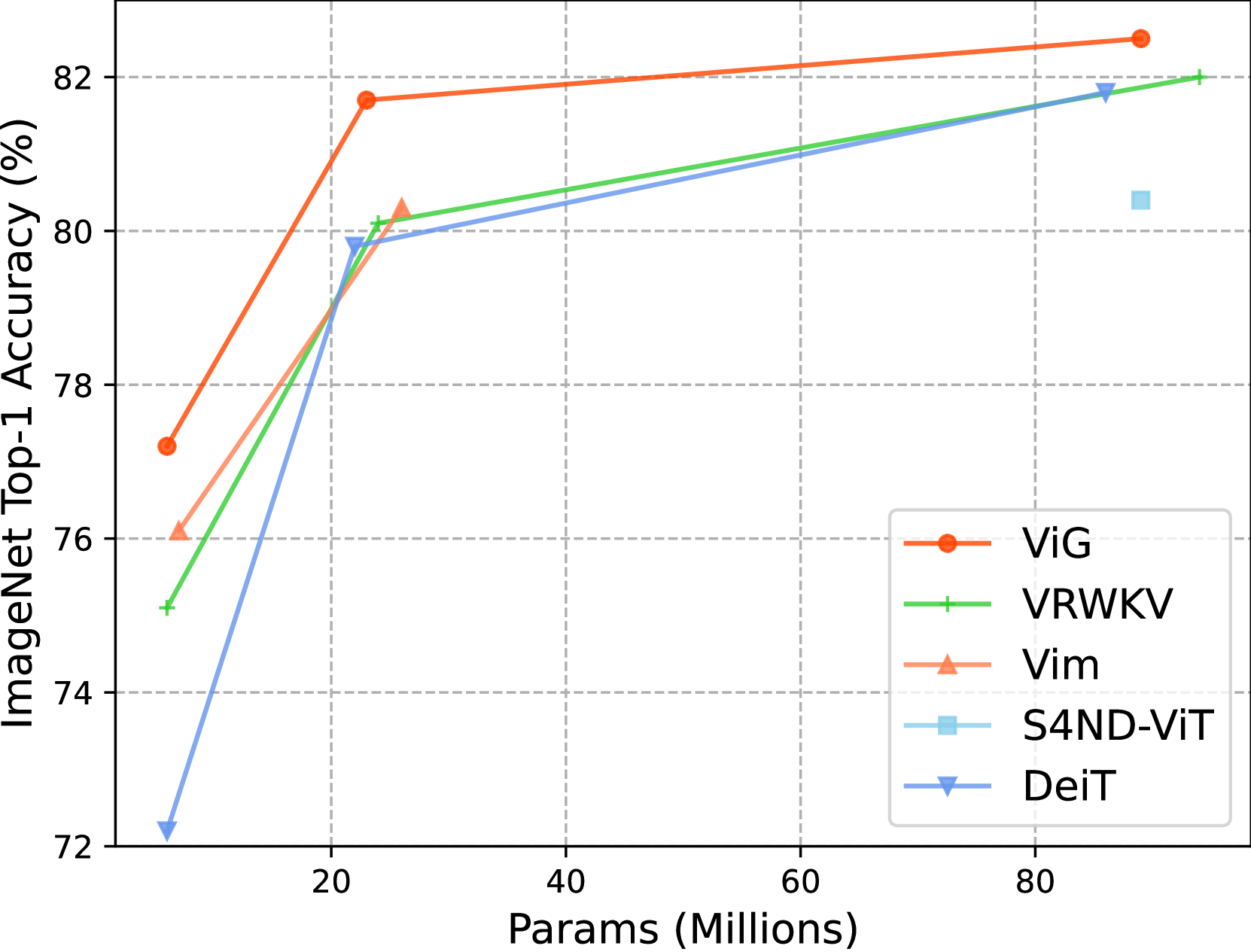
ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
Bencheng Liao, Xinggang Wang, Lianghui Zhu, Qian Zhang, Chang Huang
0
0
Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$times$ faster on $224times224$ images. At $1024times1024$ resolution, ViG-T uses 5.2$times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at url{https://github.com/hustvl/ViG}.
5/30/2024
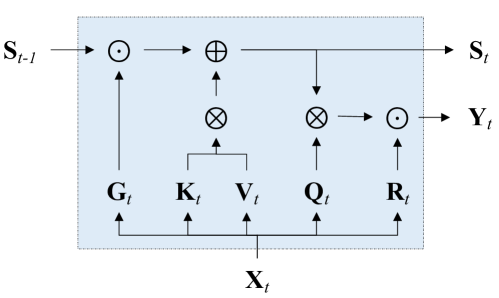
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024
🌐
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
0
0
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
5/24/2024

DiTFastAttn: Attention Compression for Diffusion Transformer Models
Zhihang Yuan, Pu Lu, Hanling Zhang, Xuefei Ning, Linfeng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, Yu Wang
0
0
Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.
6/14/2024