DiJiang: Efficient Large Language Models through Compact Kernelization
2403.19928
0
0
Abstract
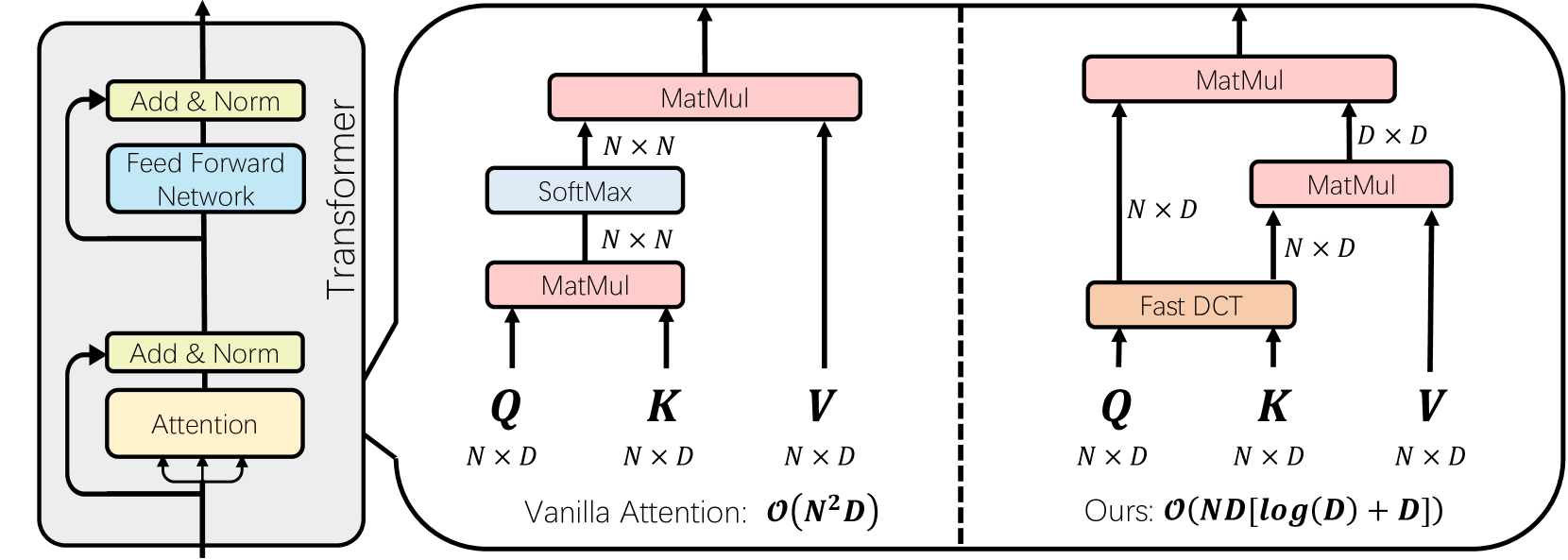
In an effort to reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically necessitate extensive retraining, which is impractical for large language models with a vast array of parameters. In this paper, we present DiJiang, a novel Frequency Domain Kernelization approach that enables the transformation of a pre-trained vanilla Transformer into a linear complexity model with little training costs. By employing a weighted Quasi-Monte Carlo method for sampling, the proposed approach theoretically offers superior approximation efficiency. To further reduce the training computational complexity, our kernelization is based on Discrete Cosine Transform (DCT) operations. Extensive experiments demonstrate that the proposed method achieves comparable performance to the original Transformer, but with significantly reduced training costs and much faster inference speeds. Our DiJiang-7B achieves comparable performance with LLaMA2-7B on various benchmark while requires only about 1/50 training cost. Code is available at https://github.com/YuchuanTian/DiJiang.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The research paper presents a novel language model called DiJiang that uses a compact kernelization technique to achieve efficient performance compared to large language models.
- The key idea is to compress the model parameters while preserving the expressive power, resulting in a smaller and faster model without significant loss in accuracy.
- The paper demonstrates the effectiveness of DiJiang on various natural language processing tasks, showing improvements in inference speed and memory usage over state-of-the-art large language models.
Plain English Explanation
Large language models have become powerful tools for a wide range of natural language processing tasks, from language generation to question answering. However, these models can be computationally expensive, requiring significant resources to train and run. This can limit their practical deployment, especially in resource-constrained environments.
The researchers behind DiJiang propose a solution to this problem. They developed a technique called "compact kernelization" that allows them to compress the model parameters while maintaining the model's expressive power. The key idea is to identify and retain the most important parts of the model, effectively creating a smaller and faster version without losing significant accuracy.
Imagine a large library with many books on various topics. Instead of keeping the entire library, the researchers carefully select the most essential books that cover the core information. This condensed library is more efficient to store and navigate, yet still provides the necessary knowledge.
Similarly, DiJiang compresses the large language model by identifying the most crucial components and retaining only those. This results in a model that is smaller in size, requires less memory, and can be processed more quickly, without sacrificing too much of the original model's capabilities.
Technical Explanation
The paper proposes a novel language model called DiJiang, which utilizes a compact kernelization technique to achieve efficient performance compared to large language models. The core idea is to compress the model parameters while preserving the model's expressive power, leading to a smaller and faster model without significant loss in accuracy.
The researchers achieve this by first identifying the most important parameters in the original language model, based on their contribution to the model's overall performance. They then use a kernelization process to extract these critical parameters and construct a compact version of the model, which retains the essential functionality while reducing the overall size and computational requirements.
The compact kernelization process involves several key steps:
- Parameter Importance Estimation: The researchers develop a method to quantify the importance of each parameter in the original model, taking into account its contribution to the model's performance.
- Kernel Construction: Using the parameter importance estimates, the researchers construct a compact "kernel" that captures the most essential components of the original model.
- Model Compression: The compact kernel is then used to replace the original model, resulting in a significantly smaller and more efficient language model.
The researchers evaluate the performance of DiJiang on various natural language processing tasks, such as text classification, question answering, and language generation. The results demonstrate that DiJiang outperforms state-of-the-art large language models in terms of inference speed and memory usage, while maintaining competitive accuracy on the evaluated tasks.
Critical Analysis
The paper presents a compelling approach to addressing the computational challenges associated with large language models. The compact kernelization technique appears to be an effective way to compress the model parameters without compromising the model's performance, which could have significant practical implications.
However, the paper does not delve into the potential limitations or caveats of the proposed method. For example, it would be useful to understand how the parameter importance estimation and kernel construction processes might be affected by the specific architecture or training data of the original language model. Additionally, the paper could have explored the trade-offs between the degree of compression and the resulting model accuracy, as well as the generalizability of the approach to different types of language models or tasks.
Furthermore, the paper could have addressed potential concerns regarding the interpretability and explainability of the compact kernelization process. Providing more insights into how the method selects and retains the critical components of the original model could help users understand the reasoning behind the model's behavior and build trust in its application.
Conclusion
The DiJiang language model presented in this paper offers a promising solution to the efficiency challenges of large language models. By employing a compact kernelization technique, the researchers have developed a way to compress model parameters while preserving the model's expressive power, resulting in a smaller and faster model without significant loss in accuracy.
The demonstrated performance improvements in inference speed and memory usage could have significant implications for the practical deployment of language models, especially in resource-constrained environments. This research contributes to the ongoing efforts to make large language models more accessible and scalable, paving the way for their wider adoption and integration into real-world applications.
While the paper presents a compelling approach, further exploration of the method's limitations and potential areas for improvement could strengthen the overall understanding and impact of this work. Nonetheless, the DiJiang model represents an important step forward in the quest for efficient and effective large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
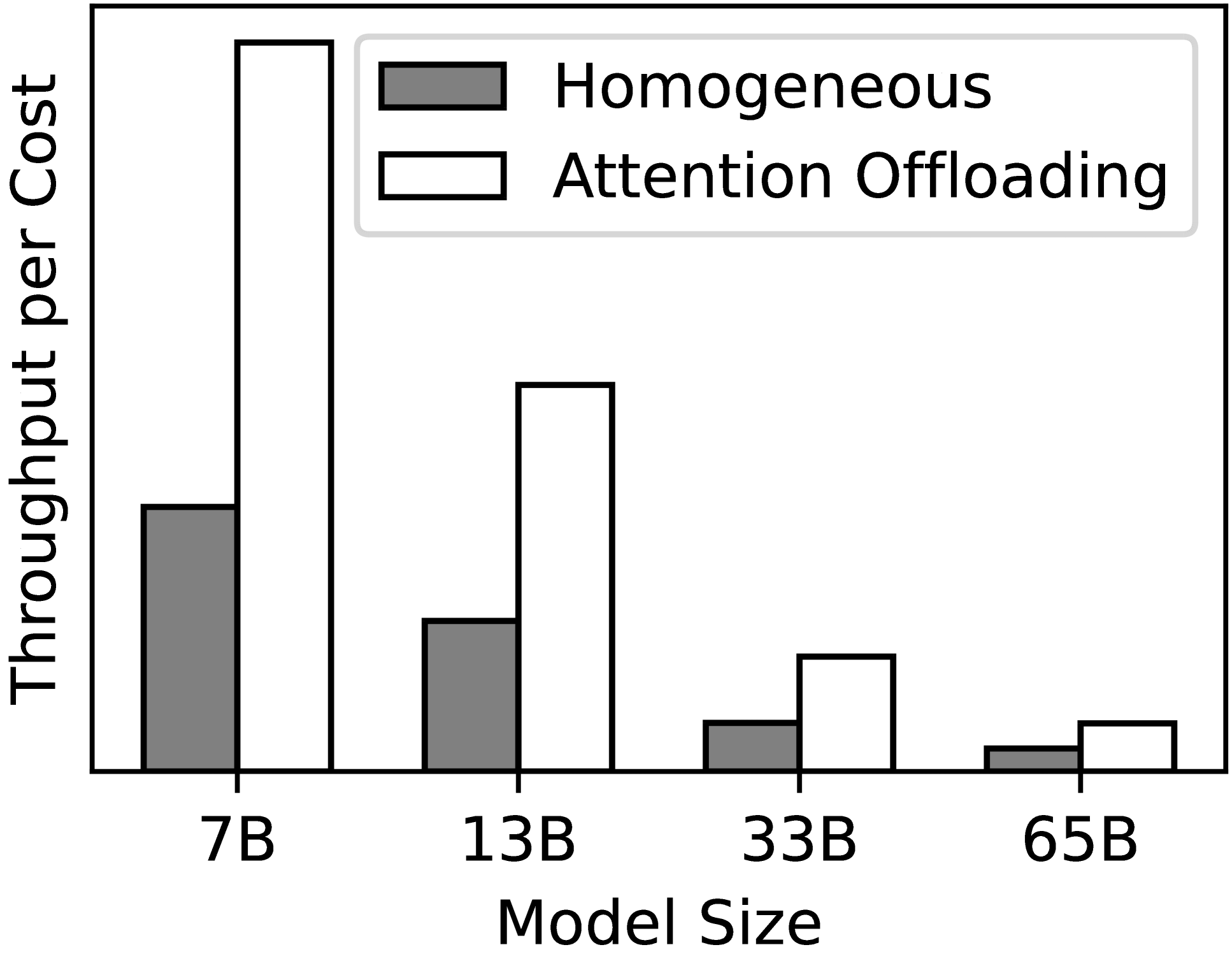
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
A Multi-Level Framework for Accelerating Training Transformer Models
Longwei Zou, Han Zhang, Yangdong Deng
0
0
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
4/15/2024
🛠️
New!Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Xinyuan Zhang, Jiang Liu, Zehui Xiong, Yudong Huang, Gaochang Xie, Ran Zhang
0
0
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
5/14/2024
Linearizing Large Language Models
Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, Thomas Kollar
0
0
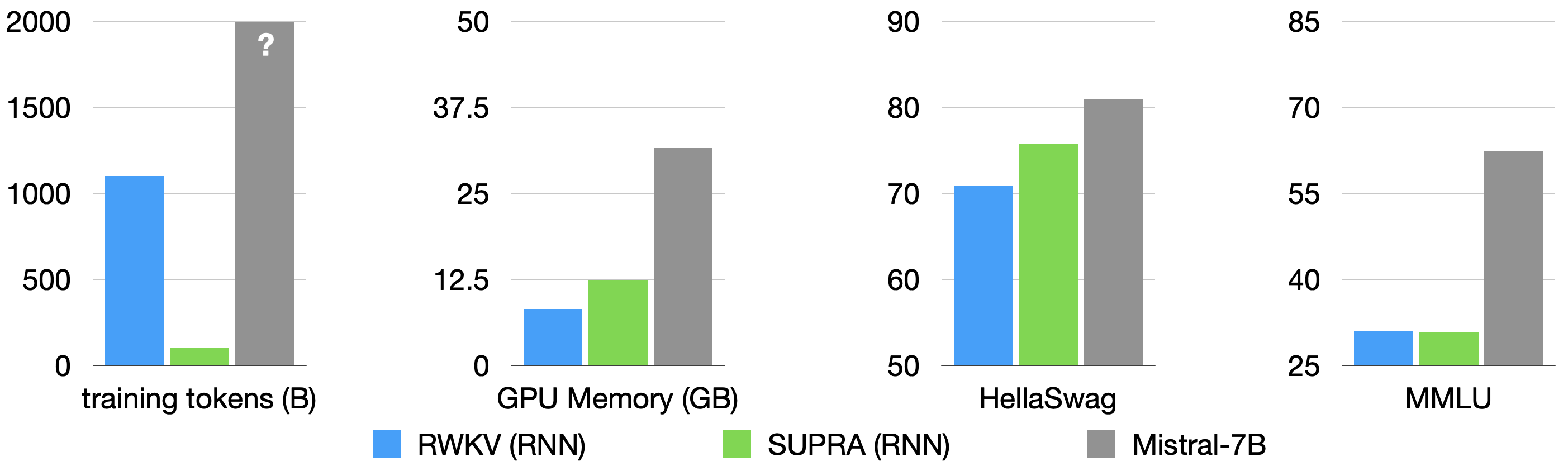
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
5/13/2024