VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training

0
🔗
Sign in to get full access
Overview
- Humans excel at navigating through crowds without collisions by focusing on specific visual regions relevant to navigation.
- Most robotic visual navigation methods use deep learning models pre-trained on vision tasks, which prioritize salient objects rather than navigation-relevant features.
- Specialized navigation models trained from scratch require significant computation.
- Self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored.
Plain English Explanation
The paper explores a self-supervised approach to visual navigation pre-training, called VANP, which learns to focus on the specific visual regions that are relevant for navigation tasks, rather than relying on salient objects that may be misleading.
Humans are incredibly skilled at navigating through crowded environments without bumping into obstacles. They do this by focusing on the specific visual cues that are most relevant for safe navigation, rather than getting distracted by other salient objects. In contrast, most robotic navigation systems use deep learning models that are pre-trained on general vision tasks, which often prioritize detecting salient objects - not necessarily the ones that are most useful for navigation.
An alternative approach is to train specialized navigation models from scratch, but this requires a lot of computational power and resources. The researchers behind this paper were inspired by the recent advancements in self-supervised learning for computer vision and natural language processing, and wanted to explore how this technique could be applied to the problem of robotic visual navigation.
Technical Explanation
The key idea behind the VANP (Self-Supervised Vision-Action Model for Visual Navigation Pre-Training) approach is to learn to focus on the specific visual regions that are relevant for navigation, rather than relying on salient objects that may be misleading.
To achieve this, the VANP model uses a self-supervised learning approach, which means it learns from its own experience without the need for labeled data. The model takes in a sequence of visual observations, the actions the agent took, and a goal image, and uses this information to learn embeddings that maximize the mutual information between the visual observations and the future actions.
This self-supervised learning process allows the model to identify the visual features that are most predictive of the agent's future actions, which are likely to be the ones that are most relevant for navigation. The researchers show that the features learned by VANP match well with human intuition about which visual regions are most important for navigation.
Compared to end-to-end trained models or models pre-trained on large datasets like ImageNet, VANP achieves comparable performance while requiring only a fraction of the training data and time.
Critical Analysis
The paper presents a compelling approach to self-supervised visual navigation pre-training, but there are a few potential limitations and areas for further research:
- The experiments are conducted in simulated environments, and it's unclear how well the approach would generalize to real-world scenarios with more complex and dynamic environments.
- The paper does not explore the performance of VANP in more challenging navigation tasks, such as those with long-range planning or exploration requirements.
- The self-supervised learning process relies on having access to future actions, which may not always be available in real-world applications. Exploring alternative self-supervision signals could be an area for further research.
Overall, the VANP approach is a promising step towards more efficient and effective robotic visual navigation, and the paper provides valuable insights into the importance of focusing on task-relevant visual features for this problem.
Conclusion
This paper presents a self-supervised approach to visual navigation pre-training called VANP, which learns to focus on the specific visual regions that are relevant for navigation tasks, rather than relying on salient objects that may be misleading.
The key innovation of VANP is its use of self-supervised learning to identify the visual features that are most predictive of an agent's future actions, which are likely to be the ones that are most relevant for navigation. This allows the model to achieve comparable performance to end-to-end trained models or those pre-trained on large datasets, but with significantly less training data and time.
While the paper demonstrates the promise of this approach in simulated environments, further research is needed to explore its generalization to more complex real-world scenarios and alternative self-supervision signals. Nevertheless, the insights provided by this work could help pave the way for more efficient and effective robotic visual navigation systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training
Mohammad Nazeri, Junzhe Wang, Amirreza Payandeh, Xuesu Xiao
Humans excel at efficiently navigating through crowds without collision by focusing on specific visual regions relevant to navigation. However, most robotic visual navigation methods rely on deep learning models pre-trained on vision tasks, which prioritize salient objects -- not necessarily relevant to navigation and potentially misleading. Alternative approaches train specialized navigation models from scratch, requiring significant computation. On the other hand, self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored due to the difficulty of defining effective self-supervision signals. Motivated by these observations, in this work, we propose a Self-Supervised Vision-Action Model for Visual Navigation Pre-Training (VANP). Instead of detecting salient objects that are beneficial for tasks such as classification or detection, VANP learns to focus only on specific visual regions that are relevant to the navigation task. To achieve this, VANP uses a history of visual observations, future actions, and a goal image for self-supervision, and embeds them using two small Transformer Encoders. Then, VANP maximizes the information between the embeddings by using a mutual information maximization objective function. We demonstrate that most VANP-extracted features match with human navigation intuition. VANP achieves comparable performance as models learned end-to-end with half the training time and models trained on a large-scale, fully supervised dataset, i.e., ImageNet, with only 0.08% data.
Read more9/6/2024
📉
0
Wild Visual Navigation: Fast Traversability Learning via Pre-Trained Models and Online Self-Supervision
Mat'ias Mattamala, Jonas Frey, Piotr Libera, Nived Chebrolu, Georg Martius, Cesar Cadena, Marco Hutter, Maurice Fallon
Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we present Wild Visual Navigation (WVN), an online self-supervised learning system for visual traversability estimation. The system is able to continuously adapt from a short human demonstration in the field, only using onboard sensing and computing. One of the key ideas to achieve this is the use of high-dimensional features from pre-trained self-supervised models, which implicitly encode semantic information that massively simplifies the learning task. Further, the development of an online scheme for supervision generator enables concurrent training and inference of the learned model in the wild. We demonstrate our approach through diverse real-world deployments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex, previously unseen outdoor terrains. Code: https://bit.ly/498b0CV - Project page:https://bit.ly/3M6nMHH
Read more4/11/2024
0
Narrowing the Gap between Vision and Action in Navigation
Yue Zhang, Parisa Kordjamshidi
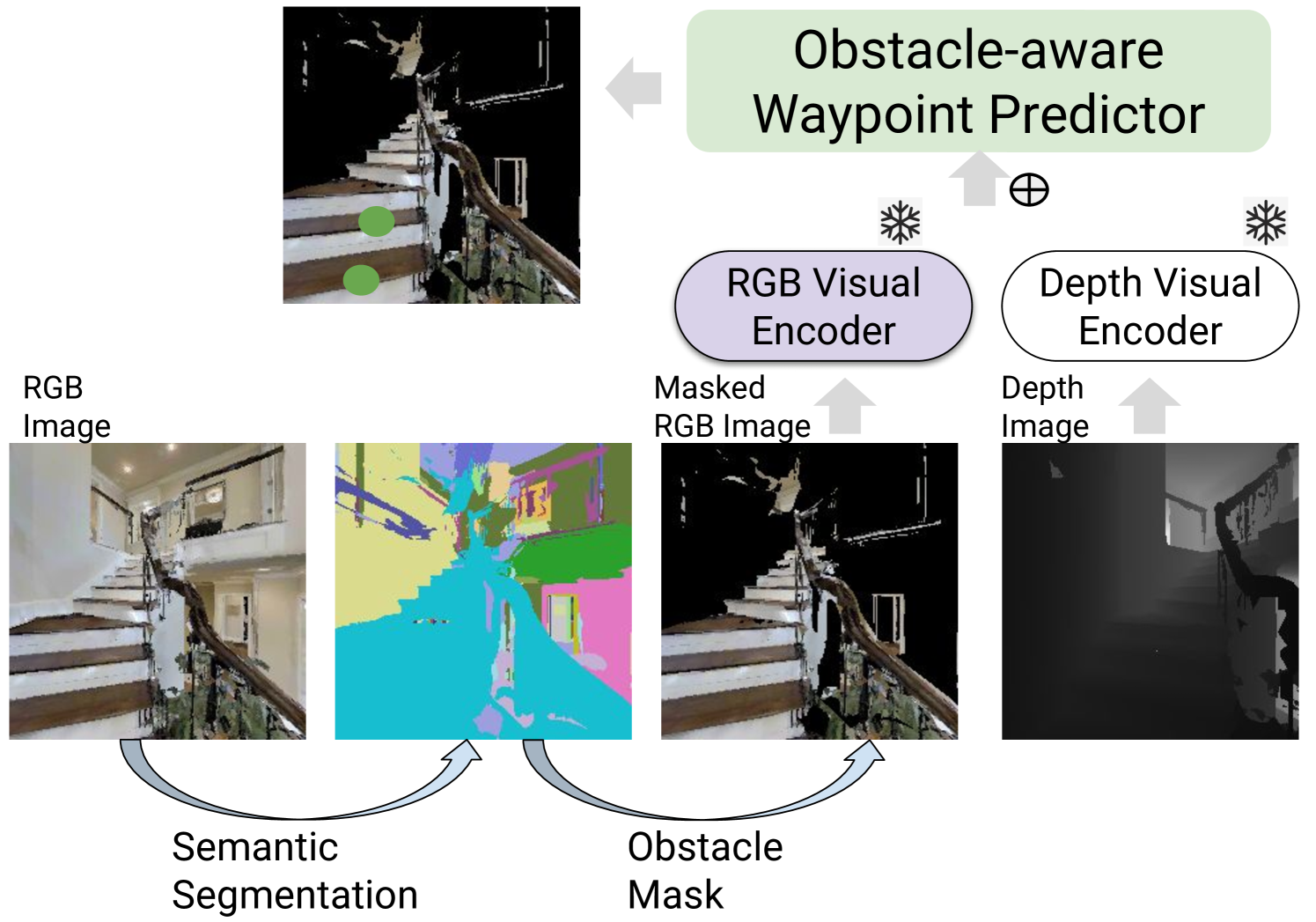
The existing methods for Vision and Language Navigation in the Continuous Environment (VLN-CE) commonly incorporate a waypoint predictor to discretize the environment. This simplifies the navigation actions into a view selection task and improves navigation performance significantly compared to direct training using low-level actions. However, the VLN-CE agents are still far from the real robots since there are gaps between their visual perception and executed actions. First, VLN-CE agents that discretize the visual environment are primarily trained with high-level view selection, which causes them to ignore crucial spatial reasoning within the low-level action movements. Second, in these models, the existing waypoint predictors neglect object semantics and their attributes related to passibility, which can be informative in indicating the feasibility of actions. To address these two issues, we introduce a low-level action decoder jointly trained with high-level action prediction, enabling the current VLN agent to learn and ground the selected visual view to the low-level controls. Moreover, we enhance the current waypoint predictor by utilizing visual representations containing rich semantic information and explicitly masking obstacles based on humans' prior knowledge about the feasibility of actions. Empirically, our agent can improve navigation performance metrics compared to the strong baselines on both high-level and low-level actions.
Read more8/21/2024

0
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Read more5/28/2024