Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs
2402.11199
0
0

Abstract
Large language models (LLMs) demonstrate strong reasoning abilities when prompted to generate chain-of-thought (CoT) explanations alongside answers. However, previous research on evaluating LLMs has solely focused on answer accuracy, neglecting the correctness of the generated CoT. In this paper, we delve deeper into the CoT reasoning capabilities of LLMs in multi-hop question answering by utilizing knowledge graphs (KGs). We propose a novel discriminative and generative CoT evaluation paradigm to assess LLMs' knowledge of reasoning and the accuracy of the generated CoT. Through experiments conducted on 5 different families of LLMs across 2 multi-hop question-answering datasets, we find that LLMs possess sufficient knowledge to perform reasoning. However, there exists a significant disparity between answer accuracy and faithfulness of the CoT reasoning generated by LLMs, indicating that they often arrive at correct answers through incorrect reasoning.
Create account to get full access
Overview
• This research paper explores a novel approach called Chain-of-Thought (CoT) Reasoning for improving the reasoning capabilities of large language models when working with knowledge graphs.
• The paper proposes a direct evaluation method to assess the quality of the chain-of-thought reasoning process, rather than just the final answer.
• Key ideas include using knowledge graph guides to structure the reasoning process, and prompting techniques to elicit and evaluate the step-by-step reasoning.
Plain English Explanation
Large language models have become incredibly capable at tasks like question answering and natural language generation. However, their reasoning process is often opaque, making it difficult to understand how they arrive at their answers.
This research tackles that issue by proposing a way to directly evaluate the chain-of-thought reasoning used by language models when answering multi-step questions that require traversing a knowledge graph.
The key idea is to guide the language model's reasoning by providing it with a knowledge graph, and then prompting it to explicitly articulate its step-by-step thought process for reaching the final answer. This allows the researchers to assess the quality and coherence of the model's reasoning, rather than just the accuracy of the output.
The knowledge graph serves as a roadmap for the model, helping it navigate the relevant information to piece together the answer. The prompting technique encourages the model to explain its reasoning out loud, almost like a human would when solving a complex problem.
By directly evaluating the chain-of-thought process, the researchers hope to gain insights into how language models can be improved to reason more transparently and reliably, especially when tackling multi-step problems that require traversing large amounts of information.
Technical Explanation
The paper proposes a direct evaluation method for assessing the quality of Chain-of-Thought (CoT) reasoning in large language models when answering multi-hop questions over knowledge graphs.
The core idea is to provide the language model with a knowledge graph, and then prompt it to generate a step-by-step explanation of its reasoning process for arriving at the final answer. This allows the researchers to evaluate the coherence and plausibility of the model's reasoning, rather than just the correctness of the output.
The authors introduce several prompting techniques to elicit the CoT reasoning, including:
- Logic-based prompting, where the model is asked to generate a sequence of logical steps.
- Multimodal CoT prompting, which combines text and visual cues from the knowledge graph.
The researchers then develop evaluation metrics to assess the quality of the generated CoT, looking at factors like coherence, faithfulness to the knowledge graph, and alignment with human-annotated reasoning.
Experiments on benchmark datasets show that the proposed CoT evaluation method provides insights into the reasoning capabilities of language models that are not captured by traditional end-task performance metrics. The results suggest that directly assessing the reasoning process can uncover weaknesses and guide future improvements to make language models more transparent and reliable, especially for complex, multi-step problems.
Critical Analysis
The paper makes a compelling case for the importance of directly evaluating the reasoning process of language models, rather than solely focusing on end-task performance. By prompting models to articulate their step-by-step reasoning, the researchers are able to gain valuable insights that would otherwise be obscured.
However, the paper acknowledges several limitations and avenues for future work. For example, the prompting techniques used may not fully capture the natural reasoning process of language models, which could be more fluid and less explicitly step-by-step. Additionally, the evaluation metrics, while innovative, may not fully capture all the nuances of high-quality reasoning.
Further research is needed to explore alternative prompting methods and evaluation frameworks that can more accurately reflect the true reasoning capabilities of language models. Connecting the CoT reasoning to the internal representations and decision-making processes of the models could also yield important insights.
Moreover, the paper focuses on knowledge graph-based reasoning, but language models are increasingly being used for reasoning in other domains, such as common sense and causal inference. Expanding the CoT evaluation approach to these areas could further strengthen its applicability and impact.
Overall, this research represents an important step towards making language models' reasoning more transparent and accountable, which is crucial as these models become more ubiquitous and influential in our daily lives.
Conclusion
This paper presents a novel approach for directly evaluating the chain-of-thought reasoning process used by large language models when answering multi-hop questions over knowledge graphs. By prompting models to explicitly articulate their step-by-step reasoning, the researchers are able to gain valuable insights into the models' reasoning capabilities that go beyond just the correctness of the final answer.
The proposed evaluation method has the potential to significantly improve the transparency and reliability of language models, especially when it comes to complex, multi-step problems that require traversing large amounts of information. As language models continue to grow in power and influence, this type of direct assessment of their reasoning process will become increasingly important for ensuring they are behaving in a safe and trustworthy manner.
While the current research has some limitations, it represents an important step forward in the field of explainable AI. By shedding light on the inner workings of language models, this work can inform future efforts to make these powerful systems more interpretable, accountable, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Suhang Wang, Yu Meng, Jiawei Han
0
0
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
4/11/2024
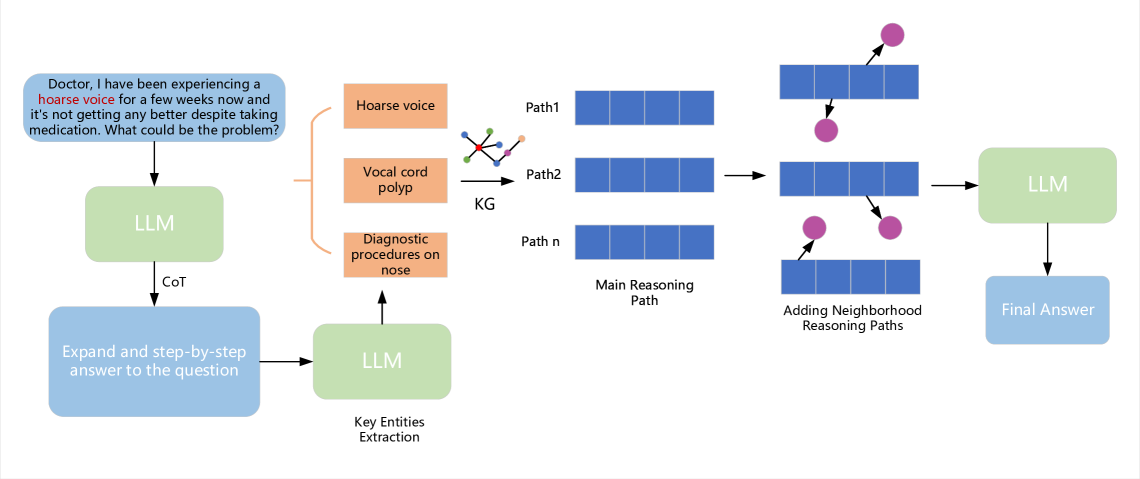
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting
Jianing Wang, Qiushi Sun, Xiang Li, Ming Gao
0
0
Recently, Chain-of-Thought (CoT) prompting has delivered success on complex reasoning tasks, which aims at designing a simple prompt like ``Let's think step by step'' or multiple in-context exemplars with well-designed rationales to elicit Large Language Models (LLMs) to generate intermediate reasoning steps. However, the generated rationales often come with mistakes, making unfactual and unfaithful reasoning chains. To mitigate this brittleness, we propose a novel Chain-of-Knowledge (CoK) prompting, where we aim at eliciting LLMs to generate explicit pieces of knowledge evidence in the form of structure triple. This is inspired by our human behaviors, i.e., we can draw a mind map or knowledge map as the reasoning evidence in the brain before answering a complex question. Benefiting from CoK, we additionally introduce a F^2-Verification method to estimate the reliability of the reasoning chains in terms of factuality and faithfulness. For the unreliable response, the wrong evidence can be indicated to prompt the LLM to rethink. Extensive experiments demonstrate that our method can further improve the performance of commonsense, factual, symbolic, and arithmetic reasoning tasks.
6/4/2024
💬
Logic Query of Thoughts: Guiding Large Language Models to Answer Complex Logic Queries with Knowledge Graphs
Lihui Liu, Zihao Wang, Ruizhong Qiu, Yikun Ban, Eunice Chan, Yangqiu Song, Jingrui He, Hanghang Tong
0
0
Despite the superb performance in many tasks, large language models (LLMs) bear the risk of generating hallucination or even wrong answers when confronted with tasks that demand the accuracy of knowledge. The issue becomes even more noticeable when addressing logic queries that require multiple logic reasoning steps. On the other hand, knowledge graph (KG) based question answering methods are capable of accurately identifying the correct answers with the help of knowledge graph, yet its accuracy could quickly deteriorate when the knowledge graph itself is sparse and incomplete. It remains a critical challenge on how to integrate knowledge graph reasoning with LLMs in a mutually beneficial way so as to mitigate both the hallucination problem of LLMs as well as the incompleteness issue of knowledge graphs. In this paper, we propose 'Logic-Query-of-Thoughts' (LGOT) which is the first of its kind to combine LLMs with knowledge graph based logic query reasoning. LGOT seamlessly combines knowledge graph reasoning and LLMs, effectively breaking down complex logic queries into easy to answer subquestions. Through the utilization of both knowledge graph reasoning and LLMs, it successfully derives answers for each subquestion. By aggregating these results and selecting the highest quality candidate answers for each step, LGOT achieves accurate results to complex questions. Our experimental findings demonstrate substantial performance enhancements, with up to 20% improvement over ChatGPT.
4/16/2024