Direct Preference Optimization for Suppressing Hallucinated Prior Exams in Radiology Report Generation

0

Sign in to get full access
Overview
- This paper presents a new approach called "Direct Preference Optimization" (DPO) to suppress the generation of "hallucinated" prior exam information in radiology report generation.
- Hallucination refers to the model producing incorrect or fabricated information that is not supported by the input data.
- The authors show that DPO can effectively reduce the occurrence of hallucinated prior exams compared to standard language modeling approaches.
Plain English Explanation
Radiology reports are an important part of medical care, as they summarize the findings from medical imaging tests like X-rays and MRIs. However, sometimes the AI models used to generate these reports can "hallucinate" or make up information that isn't actually present in the scan. This can be problematic, as it could lead to incorrect diagnoses or treatment decisions.
The researchers in this paper developed a new technique called "Direct Preference Optimization" (DPO) to address this issue. DPO works by training the AI model to directly optimize for generating reports that are preferred by human radiologists, rather than just trying to predict the next word in the report. This helps the model learn to suppress the generation of hallucinated information about prior medical exams that may not be relevant or accurate.
Through their experiments, the researchers showed that reports generated using DPO had significantly fewer instances of hallucinated prior exams compared to reports generated using standard language modeling approaches. This is an important step towards making AI-generated radiology reports more reliable and trustworthy for use in clinical settings.
Technical Explanation
The paper proposes a new approach called "Direct Preference Optimization (DPO)" to address the problem of hallucinated prior exam information in radiology report generation.
Hallucination refers to the AI model producing incorrect or fabricated information that is not supported by the input data. This is a significant issue in radiology report generation, as including inaccurate information about a patient's prior medical history could lead to incorrect diagnoses or treatment decisions.
To mitigate this, the authors leverage a "direct preference optimization" training objective, where the model is optimized to generate reports that are preferred by human radiologists, rather than simply trying to predict the next word in the report. This helps the model learn to suppress the generation of hallucinated prior exam information.
The authors evaluate their approach on a large-scale radiology report dataset and show that DPO-trained models generate significantly fewer instances of hallucinated prior exams compared to standard language modeling approaches. This demonstrates the effectiveness of their technique in improving the reliability and trustworthiness of AI-generated radiology reports.
Critical Analysis
The paper presents a novel and promising approach to addressing the important problem of hallucination in radiology report generation. By optimizing the model to directly generate preferred reports, rather than just predict the next word, the authors are able to effectively suppress the production of irrelevant or inaccurate information about prior medical exams.
However, the paper does not extensively discuss potential limitations or caveats of the DPO approach. For example, it's unclear how the model would perform on less common or more complex medical cases, where the hallucination of prior exam information may be more difficult to detect and suppress.
Additionally, the paper does not provide much insight into the decision-making process or reasoning behind the model's generated reports. Increased transparency and explainability of the AI system's outputs could be an important area for future research, to build trust and ensure the safety of these models in clinical settings.
Overall, the "Direct Preference Optimization" technique presented in this paper represents a valuable contribution to the field of hallucination mitigation in large language models. Further research and development in this area could lead to significant improvements in the reliability and trustworthiness of AI-generated medical reports.
Conclusion
This paper introduces a novel "Direct Preference Optimization" (DPO) approach to suppress the generation of hallucinated prior exam information in radiology report generation. By optimizing the model to directly produce reports preferred by human radiologists, rather than just predicting the next word, the authors are able to significantly reduce the occurrence of inaccurate or irrelevant information in the generated reports.
This is an important step towards improving the reliability and trustworthiness of AI-generated medical reports, which could have significant implications for patient care and clinical decision-making. While the paper does not address all potential limitations, the DPO technique represents a valuable contribution to the broader effort to mitigate hallucinations in large vision-language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Direct Preference Optimization for Suppressing Hallucinated Prior Exams in Radiology Report Generation
Oishi Banerjee, Hong-Yu Zhou, Subathra Adithan, Stephen Kwak, Kay Wu, Pranav Rajpurkar
Recent advances in generative vision-language models (VLMs) have exciting potential implications for AI in radiology, yet VLMs are also known to produce hallucinations, nonsensical text, and other unwanted behaviors that can waste clinicians' time and cause patient harm. Drawing on recent work on direct preference optimization (DPO), we propose a simple method for modifying the behavior of pretrained VLMs performing radiology report generation by suppressing unwanted types of generations. We apply our method to the prevention of hallucinations of prior exams, addressing a long-established problem behavior in models performing chest X-ray report generation. Across our experiments, we find that DPO fine-tuning achieves a 3.2-4.8x reduction in lines hallucinating prior exams while maintaining model performance on clinical accuracy metrics. Our work is, to the best of our knowledge, the first work to apply DPO to medical VLMs, providing a data- and compute- efficient way to suppress problem behaviors while maintaining overall clinical accuracy.
Read more6/18/2024

0
CLIP-DPO: Vision-Language Models as a Source of Preference for Fixing Hallucinations in LVLMs
Yassine Ouali, Adrian Bulat, Brais Martinez, Georgios Tzimiropoulos
Despite recent successes, LVLMs or Large Vision Language Models are prone to hallucinating details like objects and their properties or relations, limiting their real-world deployment. To address this and improve their robustness, we present CLIP-DPO, a preference optimization method that leverages contrastively pre-trained Vision-Language (VL) embedding models, such as CLIP, for DPO-based optimization of LVLMs. Unlike prior works tackling LVLM hallucinations, our method does not rely on paid-for APIs, and does not require additional training data or the deployment of other external LVLMs. Instead, starting from the initial pool of supervised fine-tuning data, we generate a diverse set of predictions, which are ranked based on their CLIP image-text similarities, and then filtered using a robust rule-based approach to obtain a set of positive and negative pairs for DPO-based training. We applied CLIP-DPO fine-tuning to the MobileVLM-v2 family of models and to LlaVA-1.5, in all cases observing significant improvements in terms of hallucination reduction over baseline models. We also observe better performance for zero-shot classification, suggesting improved grounding capabilities, and verify that the original performance on standard LVLM benchmarks is overall preserved.
Read more8/21/2024

0
Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
Yida Mu, Peizhen Bai, Kalina Bontcheva, Xingyi Song
Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.
Read more5/2/2024
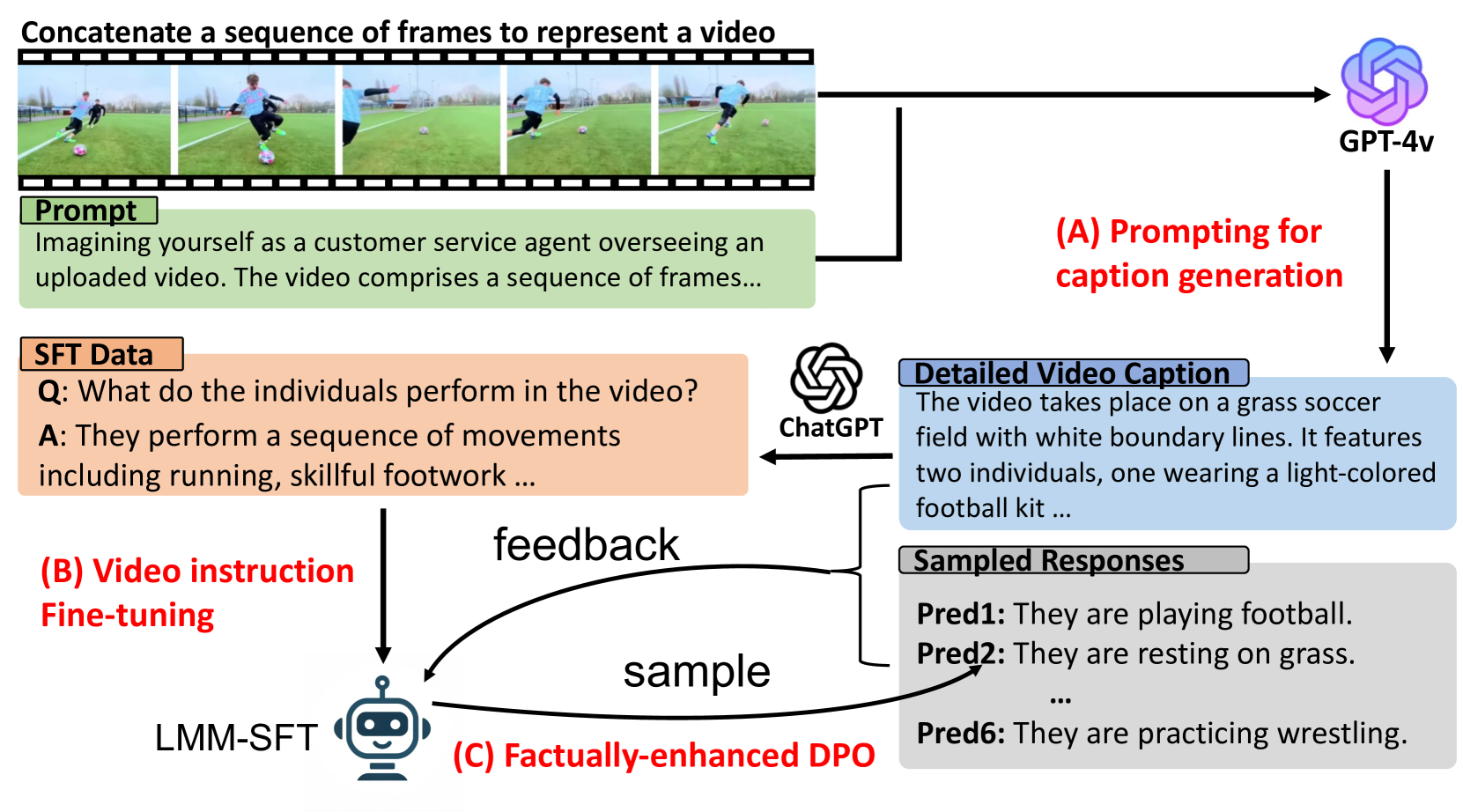
0
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander Hauptmann, Yonatan Bisk, Yiming Yang
Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Read more4/3/2024