Discovering Mixtures of Structural Causal Models from Time Series Data

0
Sign in to get full access
Overview
- This paper presents a method for discovering mixtures of structural causal models from time series data.
- The proposed approach can identify multiple causal structures that may be present in a dataset, rather than assuming a single underlying causal model.
- The method can be useful for analyzing complex real-world systems that exhibit different causal behaviors over time or across different contexts.
Plain English Explanation
The paper discusses a way to uncover multiple causal relationships that may exist in a dataset, rather than assuming there is only one underlying causal structure. Real-world systems can be complex, with different causal patterns emerging at different times or in different situations. The proposed method aims to identify these distinct causal models within a single dataset.
For example, imagine studying the factors that influence employee productivity in a company. The causal relationships could vary depending on whether the company is in a growth phase or a cost-cutting phase. This paper's method could help discover these different causal models, rather than trying to fit a single one-size-fits-all model to the data.
Technical Explanation
The key elements of the paper's methodology are:
-
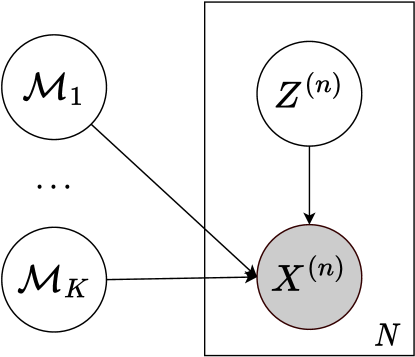
Mixture Causal Model: The authors propose a model that represents the data as a mixture of multiple structural causal models, each with its own set of causal relationships between variables.
-
Time Series Data: The method is designed to work with time series data, which can capture the dynamic nature of causal processes over time. This is relevant to applications like understanding how causal factors evolve in complex systems.
-
Causal Discovery: The paper introduces an algorithm to discover the underlying causal structure of each mixture component from the observed time series data. This builds on techniques like structural causal model learning and Bayesian model selection.
-
Mixture Estimation: The method also includes a procedure to estimate the mixing weights of the different causal models, indicating the relative prevalence of each causal structure in the data. This can provide insights into how causal factors change over time or across contexts.
Critical Analysis
The authors acknowledge several limitations of their approach. For instance, the method assumes the number of mixture components is known a priori, which may not always be the case in practice. Additionally, the causal discovery process relies on certain assumptions, such as the causal models being linear and the noise terms being Gaussian.
Further research could explore ways to relax these assumptions, as well as investigate the robustness of the method to violations of the underlying assumptions. Applying the technique to a broader range of real-world datasets would also help validate its practical applicability and identify any additional challenges that may arise.
Conclusion
This paper presents a novel approach for discovering mixtures of structural causal models from time series data. By allowing for multiple causal structures within a dataset, the method can provide a more nuanced understanding of complex systems that exhibit different causal behaviors over time or across contexts. The technique has the potential to yield useful insights in a variety of application domains, such as economics, healthcare, and social science, where causal relationships may be dynamic and context-dependent.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Discovering Mixtures of Structural Causal Models from Time Series Data
Sumanth Varambally, Yi-An Ma, Rose Yu
Discovering causal relationships from time series data is significant in fields such as finance, climate science, and neuroscience. However, contemporary techniques rely on the simplifying assumption that data originates from the same causal model, while in practice, data is heterogeneous and can stem from different causal models. In this work, we relax this assumption and perform causal discovery from time series data originating from a mixture of causal models. We propose a general variational inference-based framework called MCD to infer the underlying causal models as well as the mixing probability of each sample. Our approach employs an end-to-end training process that maximizes an evidence-lower bound for the data likelihood. We present two variants: MCD-Linear for linear relationships and independent noise, and MCD-Nonlinear for nonlinear causal relationships and history-dependent noise. We demonstrate that our method surpasses state-of-the-art benchmarks in causal discovery tasks through extensive experimentation on synthetic and real-world datasets, particularly when the data emanates from diverse underlying causal graphs. Theoretically, we prove the identifiability of such a model under some mild assumptions.
Read more6/26/2024
🤷
0
Sample, estimate, aggregate: A recipe for causal discovery foundation models
Menghua Wu, Yujia Bao, Regina Barzilay, Tommi Jaakkola
Causal discovery, the task of inferring causal structure from data, promises to accelerate scientific research, inform policy making, and more. However, causal discovery algorithms over larger sets of variables tend to be brittle against misspecification or when data are limited. To mitigate these challenges, we train a supervised model that learns to predict a larger causal graph from the outputs of classical causal discovery algorithms run over subsets of variables, along with other statistical hints like inverse covariance. Our approach is enabled by the observation that typical errors in the outputs of classical methods remain comparable across datasets. Theoretically, we show that this model is well-specified, in the sense that it can recover a causal graph consistent with graphs over subsets. Empirically, we train the model to be robust to erroneous estimates using diverse synthetic data. Experiments on real and synthetic data demonstrate that this model maintains high accuracy in the face of misspecification or distribution shift, and can be adapted at low cost to different discovery algorithms or choice of statistics.
Read more5/24/2024

0
Causal Discovery of Linear Non-Gaussian Causal Models with Unobserved Confounding
Daniela Schkoda, Elina Robeva, Mathias Drton
We consider linear non-Gaussian structural equation models that involve latent confounding. In this setting, the causal structure is identifiable, but, in general, it is not possible to identify the specific causal effects. Instead, a finite number of different causal effects result in the same observational distribution. Most existing algorithms for identifying these causal effects use overcomplete independent component analysis (ICA), which often suffers from convergence to local optima. Furthermore, the number of latent variables must be known a priori. To address these issues, we propose an algorithm that operates recursively rather than using overcomplete ICA. The algorithm first infers a source, estimates the effect of the source and its latent parents on their descendants, and then eliminates their influence from the data. For both source identification and effect size estimation, we use rank conditions on matrices formed from higher-order cumulants. We prove asymptotic correctness under the mild assumption that locally, the number of latent variables never exceeds the number of observed variables. Simulation studies demonstrate that our method achieves comparable performance to overcomplete ICA even though it does not know the number of latents in advance.
Read more8/12/2024

0
Causal Discovery in Semi-Stationary Time Series
Shanyun Gao, Raghavendra Addanki, Tong Yu, Ryan A. Rossi, Murat Kocaoglu
Discovering causal relations from observational time series without making the stationary assumption is a significant challenge. In practice, this challenge is common in many areas, such as retail sales, transportation systems, and medical science. Here, we consider this problem for a class of non-stationary time series. The structural causal model (SCM) of this type of time series, called the semi-stationary time series, exhibits that a finite number of different causal mechanisms occur sequentially and periodically across time. This model holds considerable practical utility because it can represent periodicity, including common occurrences such as seasonality and diurnal variation. We propose a constraint-based, non-parametric algorithm for discovering causal relations in this setting. The resulting algorithm, PCMCI$_{Omega}$, can capture the alternating and recurring changes in the causal mechanisms and then identify the underlying causal graph with conditional independence (CI) tests. We show that this algorithm is sound in identifying causal relations on discrete time series. We validate the algorithm with extensive experiments on continuous and discrete simulated data. We also apply our algorithm to a real-world climate dataset.
Read more7/11/2024