ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition

0

Sign in to get full access
Overview
- This paper introduces ALGO, a novel framework for object-grounded visual commonsense reasoning in open-world egocentric action recognition.
- The key idea is to leverage object-level information and commonsense knowledge to improve the accuracy of egocentric action recognition, which is an important task for applications like assistive robotics and augmented reality.
- The paper presents a detailed technical approach and extensive experiments demonstrating the effectiveness of the ALGO framework.
Plain English Explanation
ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition is a research paper that describes a new way to recognize actions in videos taken from a person's point of view, also known as egocentric videos.
The main challenge in egocentric action recognition is that the world is "open-ended" - there are many possible actions a person can perform, often involving everyday objects in their surroundings. To address this, the researchers developed a framework called ALGO that leverages information about the objects in the scene and common sense knowledge about how those objects are typically used.
For example, if the video shows a person's hand reaching for a cup, ALGO would use its understanding that cups are typically used for drinking to help recognize the action as "drinking" rather than some other action involving a cup. By grounding the action recognition in the specific objects present, ALGO can more accurately identify a wide range of actions in egocentric videos.
The paper describes the technical details of how ALGO works, including how it models object-action relationships and integrates this with visual understanding. The researchers also present extensive experiments showing that ALGO outperforms previous state-of-the-art methods for egocentric action recognition.
Overall, this research advances our ability to build AI systems that can understand and interpret complex human behaviors in realistic, open-ended environments. This has important applications in areas like robotics, virtual/augmented reality, and assistive technologies.
Technical Explanation
The ALGO framework aims to leverage object-level information and commonsense knowledge to improve the accuracy of open-world egocentric action recognition. It does this through several key technical components:
-
Object-Grounded Visual Representation: ALGO first extracts visual features from the egocentric video frames, but instead of just using a generic visual representation, it grounds these features in the specific objects detected in the scene. This object-grounded representation helps the model reason about how the actions relate to the surrounding objects.
-
Commonsense Reasoning Module: In parallel, ALGO uses a commonsense reasoning module to draw inferences about the likely actions based on the detected objects and their typical affordances (ways they can be used). This commonsense knowledge is obtained from large-scale knowledge bases like ConceptNet.
-
Cross-Modal Fusion: Finally, ALGO fuses the object-grounded visual representation with the commonsense reasoning module to arrive at a final action prediction. This allows it to combine visual observation with broader contextual understanding.
The researchers evaluate ALGO on several egocentric action recognition benchmarks, including EPIC-KITCHENS and EGTEA Gaze+. They show that ALGO outperforms previous state-of-the-art methods, demonstrating the value of its object-grounded and commonsense-infused approach to this challenging task.
Critical Analysis
The ALGO framework represents an innovative and promising direction for improving egocentric action recognition. By explicitly modeling the relationships between objects, actions, and commonsense knowledge, ALGO is able to achieve higher accuracy compared to more generic visual recognition approaches.
However, the paper does not fully address some potential limitations and areas for future research:
-
Scalability and Generalization: While ALGO demonstrates strong performance on the evaluated benchmarks, it's unclear how well the framework would scale to even richer and more diverse real-world environments. Expanding the commonsense knowledge base and object detection capabilities may be necessary for true open-world generalization.
-
Temporal Dynamics: The current ALGO framework operates on individual video frames, without explicitly modeling the temporal dynamics of the actions. Incorporating recurrent or spatio-temporal modeling could further improve action recognition, especially for more complex, multi-step activities.
-
Interpretability and Explainability: As a relatively complex model, it may be challenging to fully understand how ALGO arrives at its action predictions. Providing more interpretable and explainable mechanisms could increase trust and transparency in the system's decision-making.
-
Real-Time Performance: For many practical applications like robotics and augmented reality, real-time action recognition is crucial. The computational complexity of ALGO's cross-modal fusion approach may need to be optimized for efficient deployment in such scenarios.
Overall, the ALGO framework represents an important step forward in egocentric action recognition, but continued research is needed to address these remaining challenges and further advance the state of the art.
Conclusion
ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition presents a novel framework that leverages object-level information and commonsense knowledge to significantly improve the accuracy of open-world egocentric action recognition. By grounding the visual understanding in the specific objects present and reasoning about their typical affordances, ALGO can more effectively interpret complex human behaviors in realistic, everyday settings.
The technical innovations and strong experimental results demonstrated in this paper represent an important advancement in the field of egocentric vision and commonsense reasoning. These capabilities have far-reaching applications in areas like assistive robotics, virtual/augmented reality, and smart home technologies, where the ability to accurately understand and interpret human actions is crucial.
While the paper identifies some potential areas for future research, the ALGO framework stands as a significant contribution to the ongoing efforts to build AI systems that can truly comprehend and reason about the world in human-like ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition
Sanjoy Kundu, Shubham Trehan, Sathyanarayanan N. Aakur
Learning to infer labels in an open world, i.e., in an environment where the target labels are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world, this target search space can be unknown or exceptionally large, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision using two steps. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus) demonstrate its performance on open-world activity inference.
Read more6/11/2024
👁️
0
Discovering Novel Actions from Open World Egocentric Videos with Object-Grounded Visual Commonsense Reasoning
Sanjoy Kundu, Shubham Trehan, Sathyanarayanan N. Aakur
Learning to infer labels in an open world, i.e., in an environment where the target ``labels'' are unknown, is an important characteristic for achieving autonomy. Foundation models, pre-trained on enormous amounts of data, have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space, i.e., candidate labels provided in the prompt. This target search space can be unknown or exceptionally large in an open world, severely restricting their performance. To tackle this challenging problem, we propose a two-step, neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus, and Charades-Ego) demonstrate its performance on open-world activity inference. We also show that ALGO can be extended to zero-shot inference and demonstrate its competitive performance on the Charades-Ego dataset.
Read more5/6/2024

0
Towards Open-World Grasping with Large Vision-Language Models
Georgios Tziafas, Hamidreza Kasaei
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Read more7/16/2024
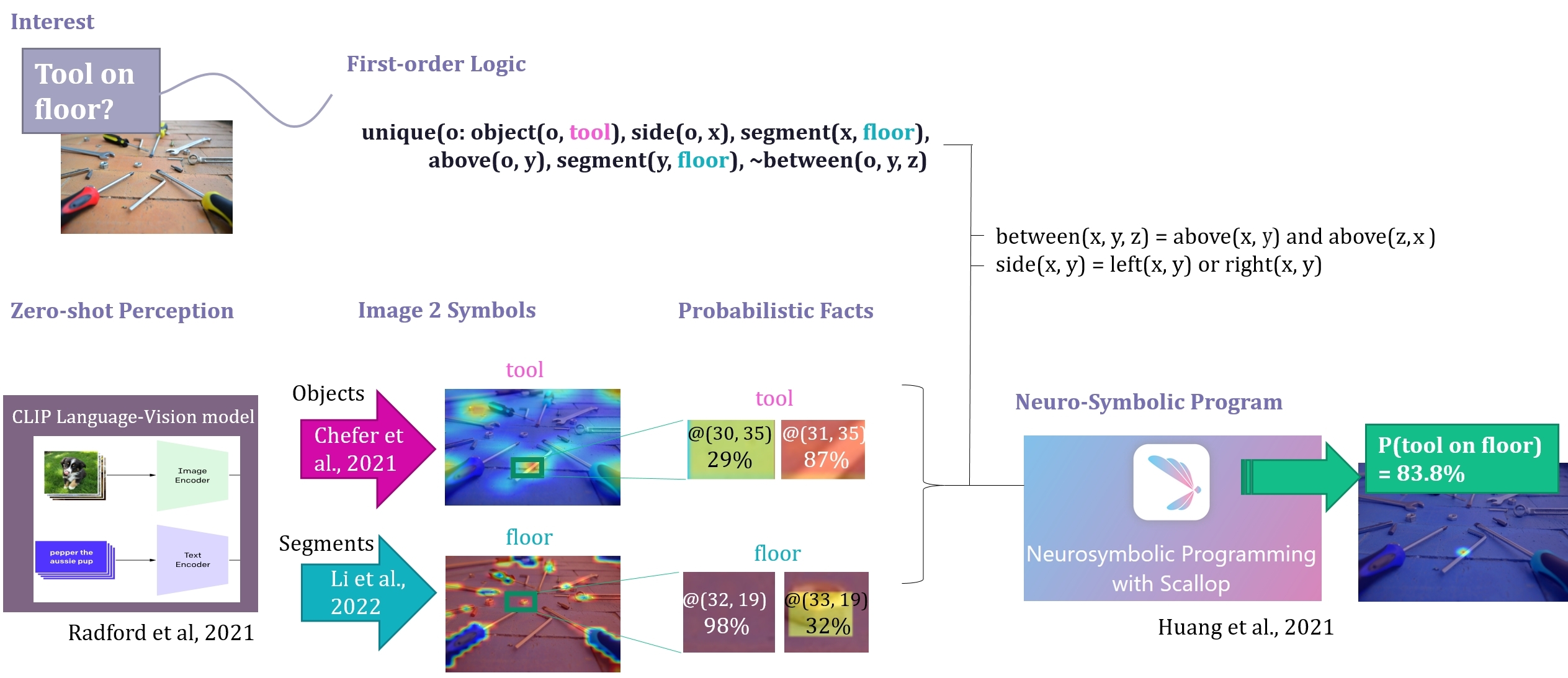
0
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Gertjan Burghouts, Fieke Hillerstrom, Erwin Walraven, Michael van Bekkum, Frank Ruis, Joris Sijs, Jelle van Mil, Judith Dijk
We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
Read more7/19/2024