Augmented Commonsense Knowledge for Remote Object Grounding

0
Sign in to get full access
Overview
- This paper presents a method for augmenting commonsense knowledge to improve the ability of AI systems to ground and reason about remote objects in visual scenes.
- The authors leverage large language models trained on online text data to extract relevant commonsense knowledge and integrate it into a vision-language model for improved object grounding.
- Experiments show that this approach outperforms prior methods on benchmarks for remote object grounding, demonstrating the value of incorporating commonsense knowledge to address challenges in visual perception and reasoning.
Plain English Explanation
The paper focuses on a common problem in computer vision and AI - the ability to identify and understand objects in images, even when those objects are not directly visible or are located far away from the camera. This is known as "remote object grounding," and it's a challenging task that requires sophisticated reasoning about the visual scene and the relationships between different elements.
To address this challenge, the researchers developed a method that taps into the wealth of commonsense knowledge contained in large language models, such as GPT-3. By extracting relevant commonsense information and integrating it into a vision-language model, the system can better understand the context and relationships in a visual scene, and more accurately identify and reason about remote objects.
For example, if an image shows a kitchen with a stove, the commonsense knowledge that stoves are typically used for cooking could help the system infer the likely presence of other kitchen appliances or utensils, even if they are not directly visible in the scene. This type of contextual reasoning is essential for accurately understanding complex visual environments.
The researchers demonstrate the effectiveness of their approach through experiments on benchmark datasets for remote object grounding, showing that their method outperforms previous state-of-the-art techniques. This suggests that incorporating commonsense knowledge is a promising avenue for improving the capabilities of AI systems in visual perception and reasoning tasks.
Technical Explanation
The key innovation in this paper is the authors' approach to augmenting the commonsense knowledge used by a vision-language model for remote object grounding. They leverage large language models, such as BERT or GPT-3, which have been pre-trained on vast amounts of online text data and can capture rich commonsense knowledge about the world.
The authors extract relevant commonsense concepts and relationships from these language models and integrate them into a vision-language model, which is then trained on datasets of images and associated captions or descriptions. This allows the model to ground the visual elements in the scene not only based on the direct visual features, but also by leveraging the broader commonsense context.
For example, if the model encounters a scene with a stove, it can use its commonsense knowledge about stoves being used for cooking, and infer the likely presence of other kitchen-related objects, even if they are not directly visible. This type of contextual reasoning is critical for accurately identifying and understanding remote objects in complex visual environments.
The authors evaluate their approach on benchmark datasets for remote object grounding, such as the CLEVR-Ref+ and CAMO datasets. The results demonstrate that their commonsense-augmented vision-language model outperforms prior state-of-the-art methods, highlighting the value of incorporating broader commonsense knowledge to address the challenges of remote object grounding.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their work. One key limitation is the reliance on the specific commonsense knowledge extracted from pre-trained language models, which may not always be comprehensive or perfectly aligned with the needs of the remote object grounding task.
Additionally, the authors note that their approach, while effective, is still constrained by the inherent biases and limitations of the underlying language models. As with many AI systems that rely on large-scale training data, there is a risk of perpetuating or amplifying societal biases present in the original data sources.
Further research could explore ways to more dynamically or flexibly incorporate commonsense knowledge, perhaps by leveraging knowledge graph reasoning or other techniques for knowledge representation and reasoning. Integrating the commonsense knowledge extraction and model training into a more holistic and end-to-end framework could also be a valuable direction for future work.
Despite these limitations, the authors' approach represents an important step forward in addressing the challenges of remote object grounding and the broader problem of grounding AI systems' understanding of the world in commonsense knowledge. As AI systems become increasingly capable of perceiving and reasoning about complex visual environments, the ability to leverage relevant commonsense information will be crucial for developing robust and reliable computer vision and reasoning capabilities.
Conclusion
This paper presents a novel method for augmenting commonsense knowledge in a vision-language model to improve its ability to ground and reason about remote objects in visual scenes. By extracting relevant commonsense concepts and relationships from large language models and integrating them into the vision-language model, the authors demonstrate significant improvements in remote object grounding benchmarks.
The findings highlight the importance of commonsense reasoning for addressing the challenges of visual perception and understanding, and suggest that continued research in this direction could lead to important breakthroughs in AI's ability to comprehend and interact with the world around it. As the field of computer vision and AI continues to advance, incorporating commonsense knowledge will likely be a key factor in developing systems that can truly understand and reason about the rich, complex, and contextual nature of visual environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Augmented Commonsense Knowledge for Remote Object Grounding
Bahram Mohammadi, Yicong Hong, Yuankai Qi, Qi Wu, Shirui Pan, Javen Qinfeng Shi
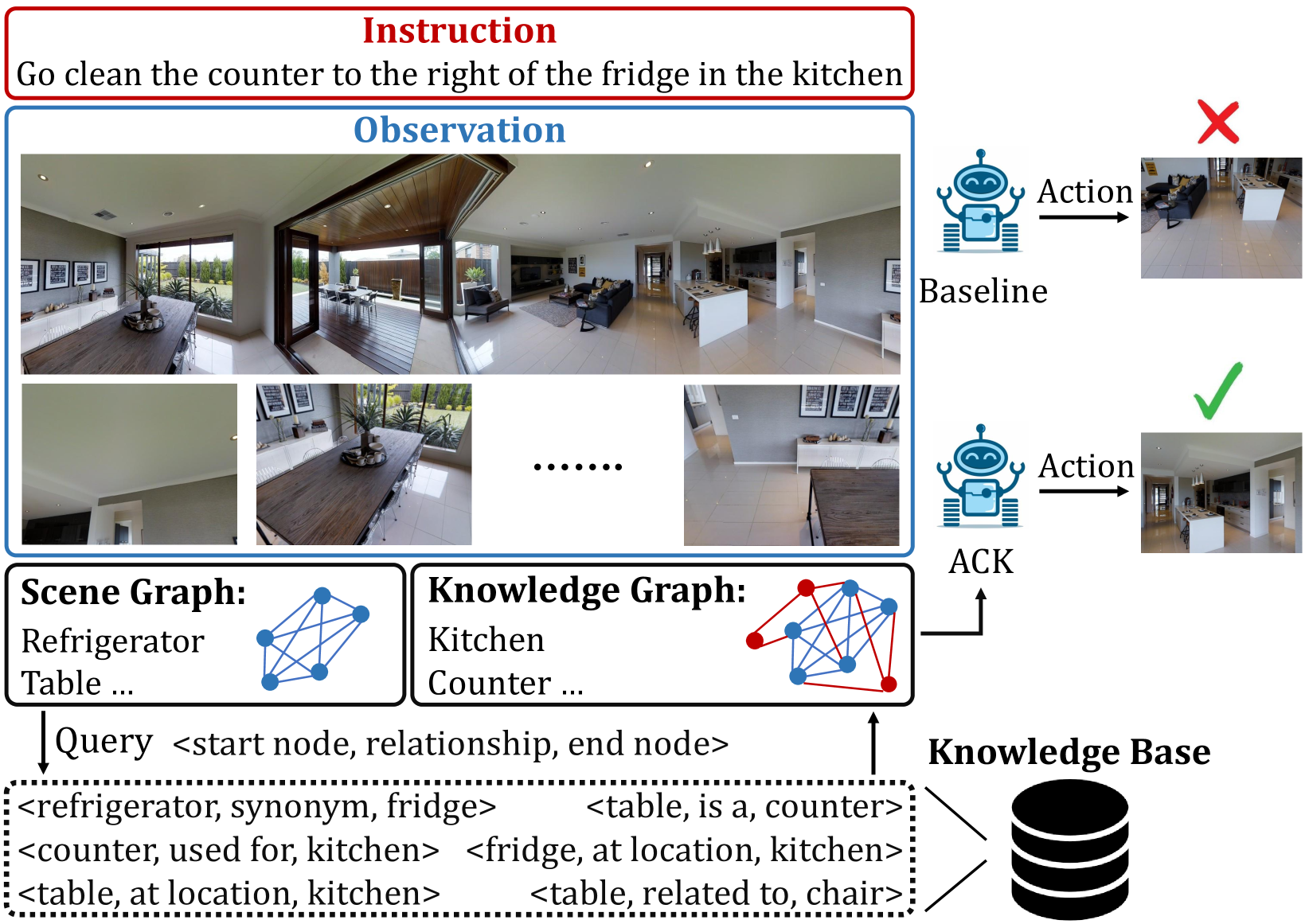
The vision-and-language navigation (VLN) task necessitates an agent to perceive the surroundings, follow natural language instructions, and act in photo-realistic unseen environments. Most of the existing methods employ the entire image or object features to represent navigable viewpoints. However, these representations are insufficient for proper action prediction, especially for the REVERIE task, which uses concise high-level instructions, such as ''Bring me the blue cushion in the master bedroom''. To address enhancing representation, we propose an augmented commonsense knowledge model (ACK) to leverage commonsense information as a spatio-temporal knowledge graph for improving agent navigation. Specifically, the proposed approach involves constructing a knowledge base by retrieving commonsense information from ConceptNet, followed by a refinement module to remove noisy and irrelevant knowledge. We further present ACK which consists of knowledge graph-aware cross-modal and concept aggregation modules to enhance visual representation and visual-textual data alignment by integrating visible objects, commonsense knowledge, and concept history, which includes object and knowledge temporal information. Moreover, we add a new pipeline for the commonsense-based decision-making process which leads to more accurate local action prediction. Experimental results demonstrate our proposed model noticeably outperforms the baseline and archives the state-of-the-art on the REVERIE benchmark.
Read more6/4/2024

0
Aligning Knowledge Graph with Visual Perception for Object-goal Navigation
Nuo Xu, Wen Wang, Rong Yang, Mengjie Qin, Zheyuan Lin, Wei Song, Chunlong Zhang, Jason Gu, Chao Li
Object-goal navigation is a challenging task that requires guiding an agent to specific objects based on first-person visual observations. The ability of agent to comprehend its surroundings plays a crucial role in achieving successful object finding. However, existing knowledge-graph-based navigators often rely on discrete categorical one-hot vectors and vote counting strategy to construct graph representation of the scenes, which results in misalignment with visual images. To provide more accurate and coherent scene descriptions and address this misalignment issue, we propose the Aligning Knowledge Graph with Visual Perception (AKGVP) method for object-goal navigation. Technically, our approach introduces continuous modeling of the hierarchical scene architecture and leverages visual-language pre-training to align natural language description with visual perception. The integration of a continuous knowledge graph architecture and multimodal feature alignment empowers the navigator with a remarkable zero-shot navigation capability. We extensively evaluate our method using the AI2-THOR simulator and conduct a series of experiments to demonstrate the effectiveness and efficiency of our navigator. Code available: https://github.com/nuoxu/AKGVP.
Read more4/29/2024

0
CON: Continual Object Navigation via Data-Free Inter-Agent Knowledge Transfer in Unseen and Unfamiliar Places
Kouki Terashima, Daiki Iwata, Kanji Tanaka
This work explores the potential of brief inter-agent knowledge transfer (KT) to enhance the robotic object goal navigation (ON) in unseen and unfamiliar environments. Drawing on the analogy of human travelers acquiring local knowledge, we propose a framework in which a traveler robot (student) communicates with local robots (teachers) to obtain ON knowledge through minimal interactions. We frame this process as a data-free continual learning (CL) challenge, aiming to transfer knowledge from a black-box model (teacher) to a new model (student). In contrast to approaches like zero-shot ON using large language models (LLMs), which utilize inherently communication-friendly natural language for knowledge representation, the other two major ON approaches -- frontier-driven methods using object feature maps and learning-based ON using neural state-action maps -- present complex challenges where data-free KT remains largely uncharted. To address this gap, we propose a lightweight, plug-and-play KT module targeting non-cooperative black-box teachers in open-world settings. Using the universal assumption that every teacher robot has vision and mobility capabilities, we define state-action history as the primary knowledge base. Our formulation leads to the development of a query-based occupancy map that dynamically represents target object locations, serving as an effective and communication-friendly knowledge representation. We validate the effectiveness of our method through experiments conducted in the Habitat environment.
Read more9/24/2024
0
Narrowing the Gap between Vision and Action in Navigation
Yue Zhang, Parisa Kordjamshidi
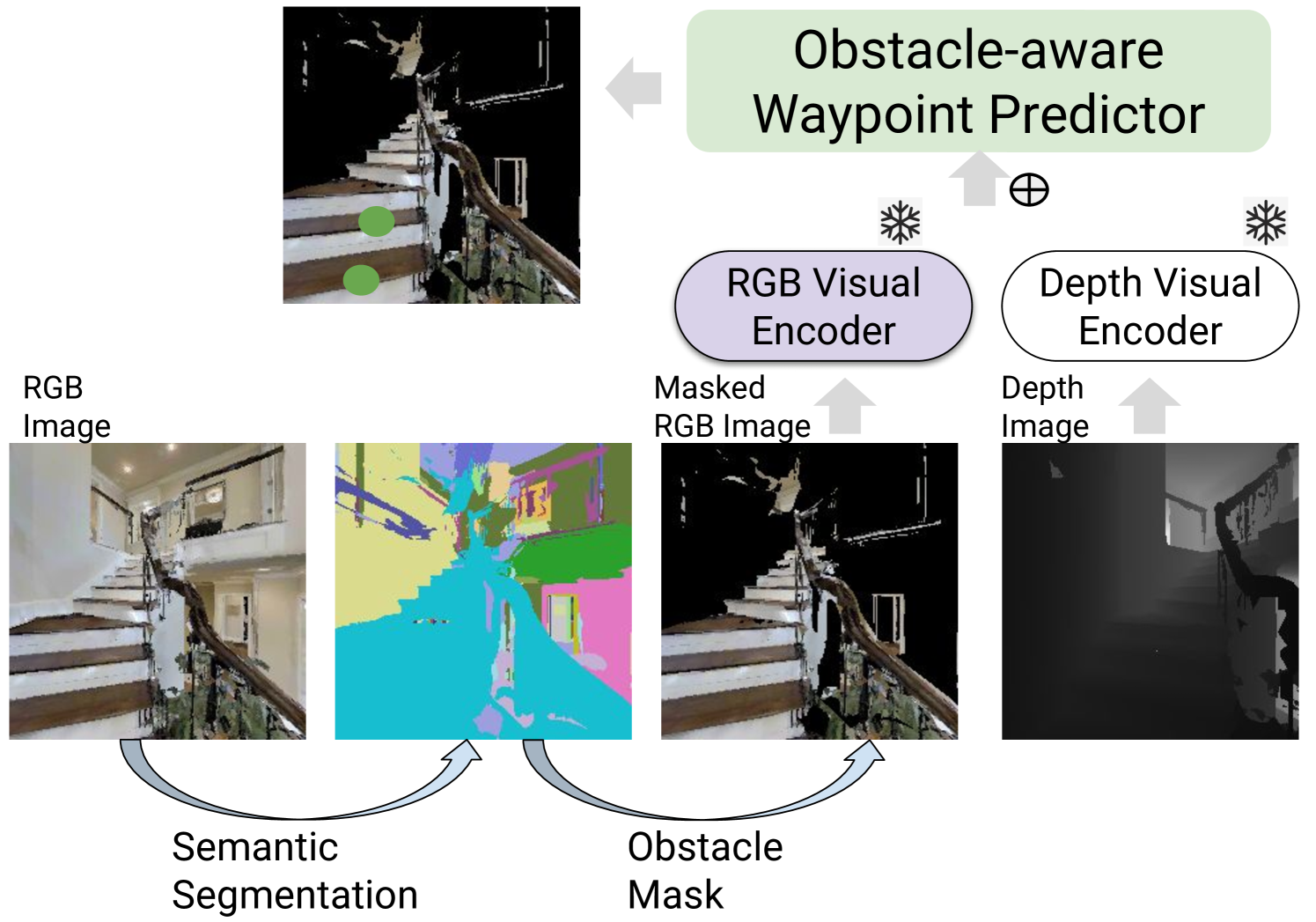
The existing methods for Vision and Language Navigation in the Continuous Environment (VLN-CE) commonly incorporate a waypoint predictor to discretize the environment. This simplifies the navigation actions into a view selection task and improves navigation performance significantly compared to direct training using low-level actions. However, the VLN-CE agents are still far from the real robots since there are gaps between their visual perception and executed actions. First, VLN-CE agents that discretize the visual environment are primarily trained with high-level view selection, which causes them to ignore crucial spatial reasoning within the low-level action movements. Second, in these models, the existing waypoint predictors neglect object semantics and their attributes related to passibility, which can be informative in indicating the feasibility of actions. To address these two issues, we introduce a low-level action decoder jointly trained with high-level action prediction, enabling the current VLN agent to learn and ground the selected visual view to the low-level controls. Moreover, we enhance the current waypoint predictor by utilizing visual representations containing rich semantic information and explicitly masking obstacles based on humans' prior knowledge about the feasibility of actions. Empirically, our agent can improve navigation performance metrics compared to the strong baselines on both high-level and low-level actions.
Read more8/21/2024