Discrete Prompt Compression with Reinforcement Learning
2308.08758
0
0
🏅
Abstract
Compressed prompts aid instruction-tuned language models (LMs) in overcoming context window limitations and reducing computational costs. Existing methods, which primarily based on training embeddings, face various challenges associated with interpretability, the fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), which is a discrete prompt compression method that addresses these issues. The proposed PCRL method utilizes a computationally efficient policy network that edits prompts directly. The training approach employed in the proposed PCRLs can be applied flexibly to various types of LMs, including both decoder-only and encoder-decoder architecture and it can be trained without gradient access to the LMs or labeled data. The proposed PCRL achieves an average reduction of 24.6% in terms of the token count across various instruction prompts while maintaining sufficient performance. In addition, we demonstrate that the learned policy can be transferred to larger LMs, and through a comprehensive analysis, we explore the token importance within the prompts. Our code is accessible at https://github.com/nenomigami/PromptCompressor.
Create account to get full access
Overview
- This paper proposes a method called Prompt Compression with Reinforcement Learning (PCRL) to reduce the length of prompts used to instruct large language models (LLMs).
- Existing methods for prompt compression, which focus on training embeddings, face challenges like interpretability, fixed embedding size, and applicability across different LLMs.
- PCRL is a discrete prompt compression technique that addresses these issues by using a policy network to directly edit prompts.
- The PCRL approach can be applied flexibly to various types of LLMs and trained without access to the LLM's gradients or labeled data.
- The proposed PCRL method achieves an average 24.6% reduction in token count while maintaining performance, and the learned policy can be transferred to larger LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a wide variety of natural language tasks. However, these models have a limited "context window" - they can only process a certain number of words or tokens at a time. This can be a problem when using LLMs for instruction-following tasks, as the prompts needed to guide the model may be too long to fit within the context window.
To address this, the researchers developed a method called Prompt Compression with Reinforcement Learning (PCRL). PCRL uses a neural network policy to automatically shorten prompts while preserving their essential meaning and the model's performance on the task. This is more flexible and effective than previous techniques, which often relied on training fixed-size embeddings.
The key idea behind PCRL is to train the policy network to edit the prompts in a way that reduces their length without significantly degrading the model's outputs. The policy network learns through trial-and-error, with the goal of minimizing the prompt length while maximizing the model's performance on the given task.
One of the advantages of PCRL is that it can be applied to a variety of different LLMs, including both decoder-only and encoder-decoder architectures. Additionally, the PCRL approach can be trained without direct access to the LLM's gradients or labeled data, making it more broadly applicable.
The researchers found that PCRL was able to achieve an average 24.6% reduction in the number of tokens in the prompts, while still maintaining the model's performance on the target tasks. They also showed that the learned PCRL policy could be successfully transferred to larger LLMs, demonstrating the flexibility and generalizability of the approach.
Technical Explanation
The paper presents a novel method called Prompt Compression with Reinforcement Learning (PCRL) for compressing instruction prompts used to guide large language models (LLMs). Existing prompt compression techniques, which typically focus on training fixed-size embeddings, face challenges related to interpretability, the rigid number of embedding tokens, reusability across different LLMs, and incompatibility with black-box API interactions.
To address these limitations, the researchers developed PCRL, a discrete prompt compression method that utilizes a computationally efficient policy network to directly edit the prompts. The policy network is trained using reinforcement learning, with the goal of minimizing the prompt length while maintaining the model's performance on the target task.
The key advantages of the PCRL approach are:
- Flexibility: The PCRL training process can be applied to a variety of LLM architectures, including both decoder-only and encoder-decoder models.
- Independence from LLM gradients: PCRL can be trained without direct access to the LLM's gradients or labeled data, making it more widely applicable.
- Interpretability: The discrete prompt editing performed by the PCRL policy network is more interpretable than techniques based on fixed-size embeddings.
- Transferability: The learned PCRL policy can be successfully transferred to larger LLMs, demonstrating the approach's generalizability.
In their experiments, the researchers show that PCRL achieves an average 24.6% reduction in token count across various instruction prompts, while maintaining the LLM's performance. They also conduct a comprehensive analysis to explore the importance of different tokens within the prompts, providing insights into the compression process.
Critical Analysis
The PCRL method proposed in this paper represents a promising approach to addressing the challenge of prompt length limitations in large language models. By using a reinforcement learning-based policy network to directly edit prompts, the researchers have developed a more flexible and interpretable compression technique compared to previous embedding-based methods.
One potential limitation of the PCRL approach is that it may not be as effective for highly specialized or domain-specific prompts, where the contextual meaning of the words is more critical. The researchers acknowledge this and suggest that a hybrid approach combining PCRL with other prompt compression techniques, such as prompt exploration and regression, could be an area for future research.
Additionally, while the researchers demonstrate that the PCRL policy can be transferred to larger LLMs, it would be valuable to investigate the limits of this transferability, particularly as model size and complexity increase. Further research could explore the ability of PCRL to maintain performance across a wider range of LLM architectures and scales.
Another area for further study is the potential for PCRL to be used in conjunction with other techniques for improving LLM efficiency, such as self-compressing prompts. By combining multiple optimization approaches, it may be possible to achieve even greater reductions in computational cost and memory usage without sacrificing model performance.
Overall, the PCRL method proposed in this paper represents a significant advancement in the field of prompt compression for large language models. The researchers have demonstrated a novel and flexible approach that addresses several limitations of existing techniques, and their findings open up new avenues for further exploration and innovation in this important area of AI research.
Conclusion
The paper presents a novel method called Prompt Compression with Reinforcement Learning (PCRL) that addresses the challenge of reducing the length of prompts used to instruct large language models (LLMs). PCRL uses a policy network trained via reinforcement learning to directly edit and compress prompts, overcoming the limitations of previous embedding-based techniques.
The key advantages of PCRL are its flexibility, independence from LLM gradients, interpretability, and the ability to transfer the learned policy to larger LLMs. The researchers demonstrate that PCRL can achieve an average 24.6% reduction in token count while maintaining the LLM's performance, and they provide a comprehensive analysis of the token importance within the prompts.
This research represents a significant step forward in the field of prompt compression for LLMs, enabling more efficient context processing and reduced computational costs. The PCRL approach opens up new possibilities for optimizing the use of large language models in a wide range of applications, from natural language processing to task-oriented dialogue systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
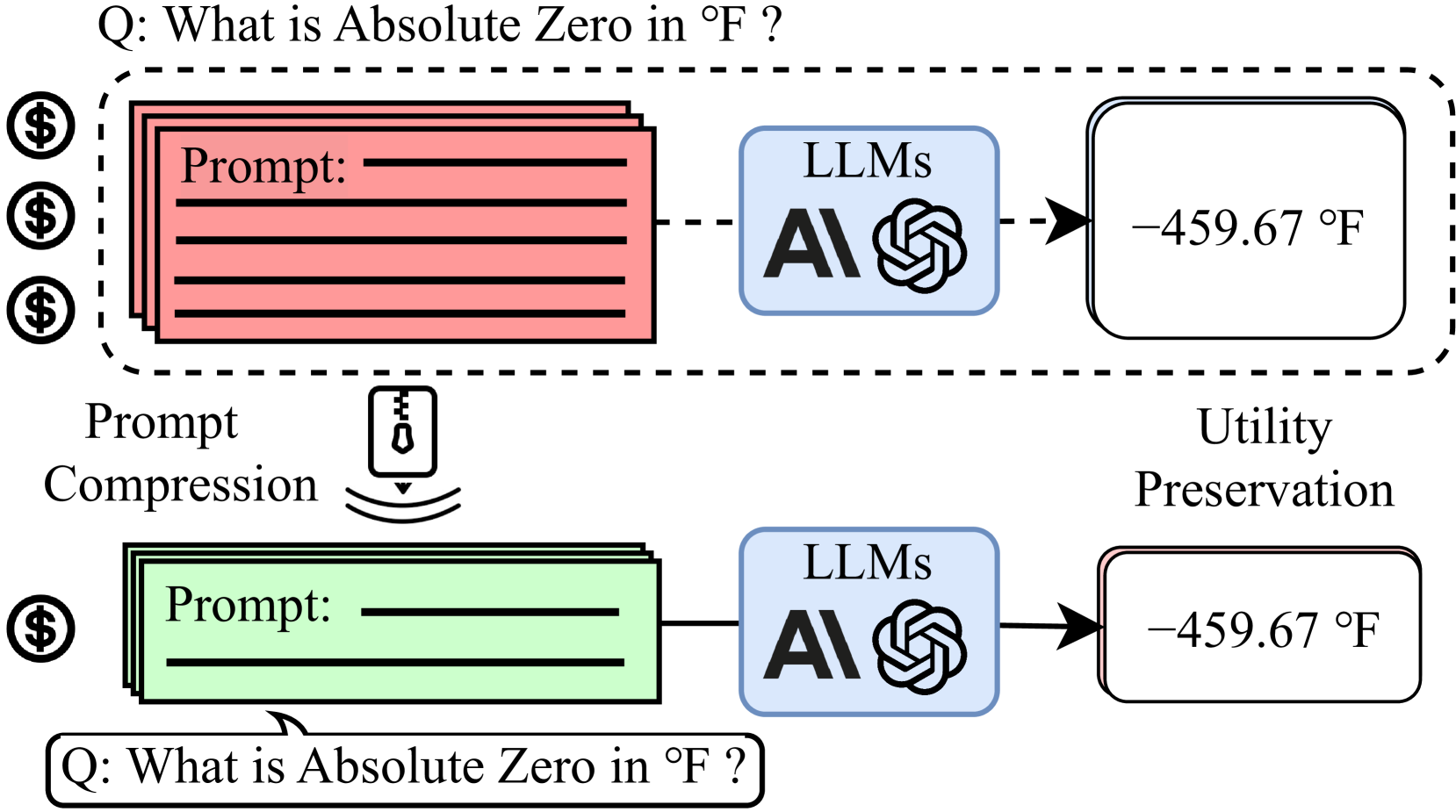
Learning to Compress Prompt in Natural Language Formats
Yu-Neng Chuang, Tianwei Xing, Chia-Yuan Chang, Zirui Liu, Xun Chen, Xia Hu
0
0
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
4/3/2024
🏅
PRewrite: Prompt Rewriting with Reinforcement Learning
Weize Kong, Spurthi Amba Hombaiah, Mingyang Zhang, Qiaozhu Mei, Michael Bendersky
0
0
Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a trial and error fashion that can be time consuming, ineffective, and sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these problems, we investigate automated prompt engineering in this paper. Specifically, we propose PRewrite, an automated method to rewrite an under-optimized prompt to a more effective prompt. We instantiate the prompt rewriter using a LLM. The rewriter LLM is trained using reinforcement learning to optimize the performance on a given downstream task. We conduct experiments on diverse benchmark datasets, which demonstrates the effectiveness of PRewrite.
6/11/2024
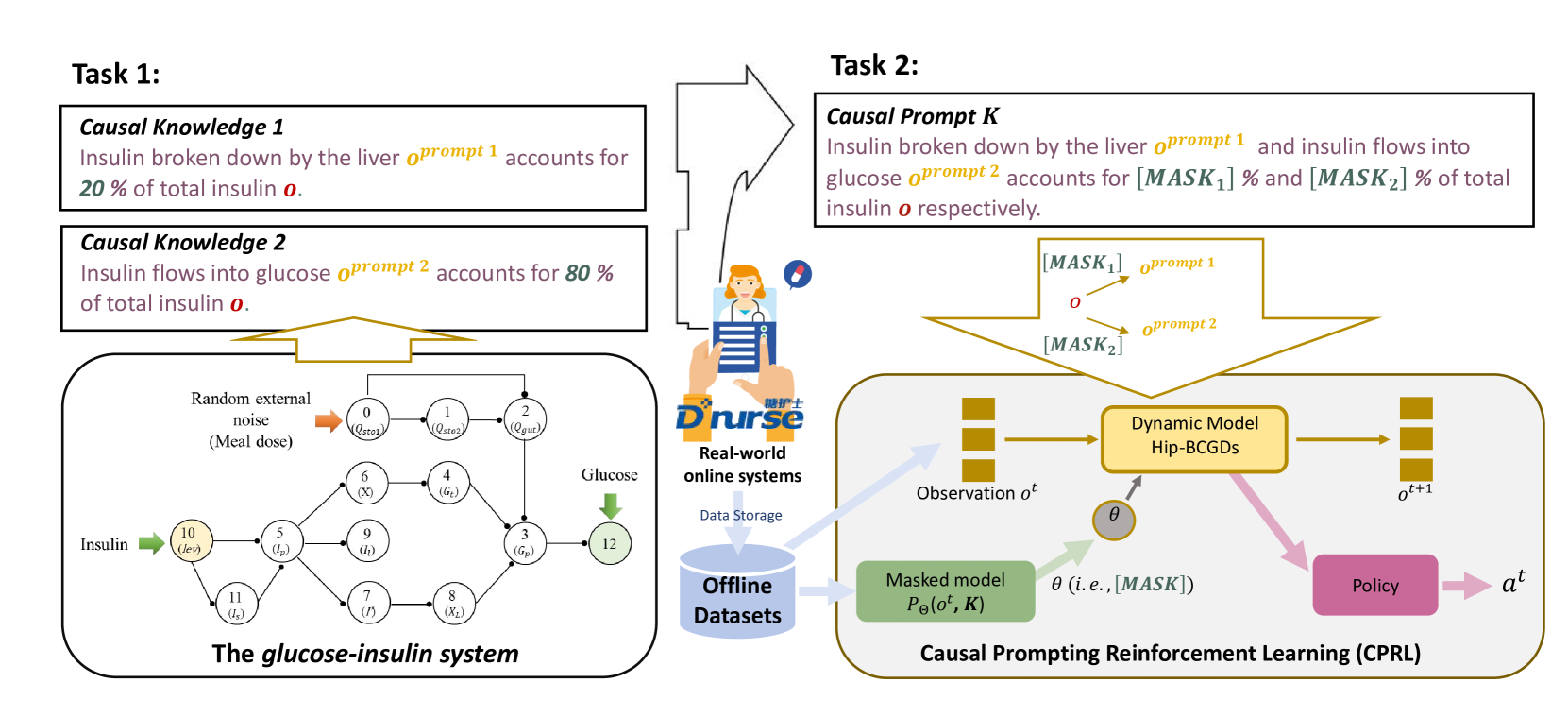
Causal prompting model-based offline reinforcement learning
Xuehui Yu, Yi Guan, Rujia Shen, Xin Li, Chen Tang, Jingchi Jiang
0
0
Model-based offline Reinforcement Learning (RL) allows agents to fully utilise pre-collected datasets without requiring additional or unethical explorations. However, applying model-based offline RL to online systems presents challenges, primarily due to the highly suboptimal (noise-filled) and diverse nature of datasets generated by online systems. To tackle these issues, we introduce the Causal Prompting Reinforcement Learning (CPRL) framework, designed for highly suboptimal and resource-constrained online scenarios. The initial phase of CPRL involves the introduction of the Hidden-Parameter Block Causal Prompting Dynamic (Hip-BCPD) to model environmental dynamics. This approach utilises invariant causal prompts and aligns hidden parameters to generalise to new and diverse online users. In the subsequent phase, a single policy is trained to address multiple tasks through the amalgamation of reusable skills, circumventing the need for training from scratch. Experiments conducted across datasets with varying levels of noise, including simulation-based and real-world offline datasets from the Dnurse APP, demonstrate that our proposed method can make robust decisions in out-of-distribution and noisy environments, outperforming contemporary algorithms. Additionally, we separately verify the contributions of Hip-BCPDs and the skill-reuse strategy to the robustness of performance. We further analyse the visualised structure of Hip-BCPD and the interpretability of sub-skills. We released our source code and the first ever real-world medical dataset for precise medical decision-making tasks.
6/4/2024
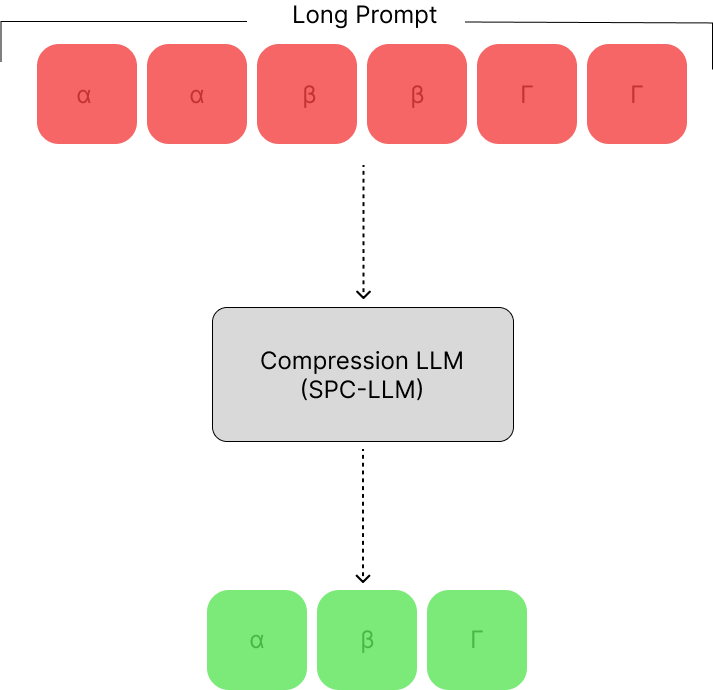
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd
0
0
The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
4/22/2024