Causal prompting model-based offline reinforcement learning
2406.01065
0
0
Abstract
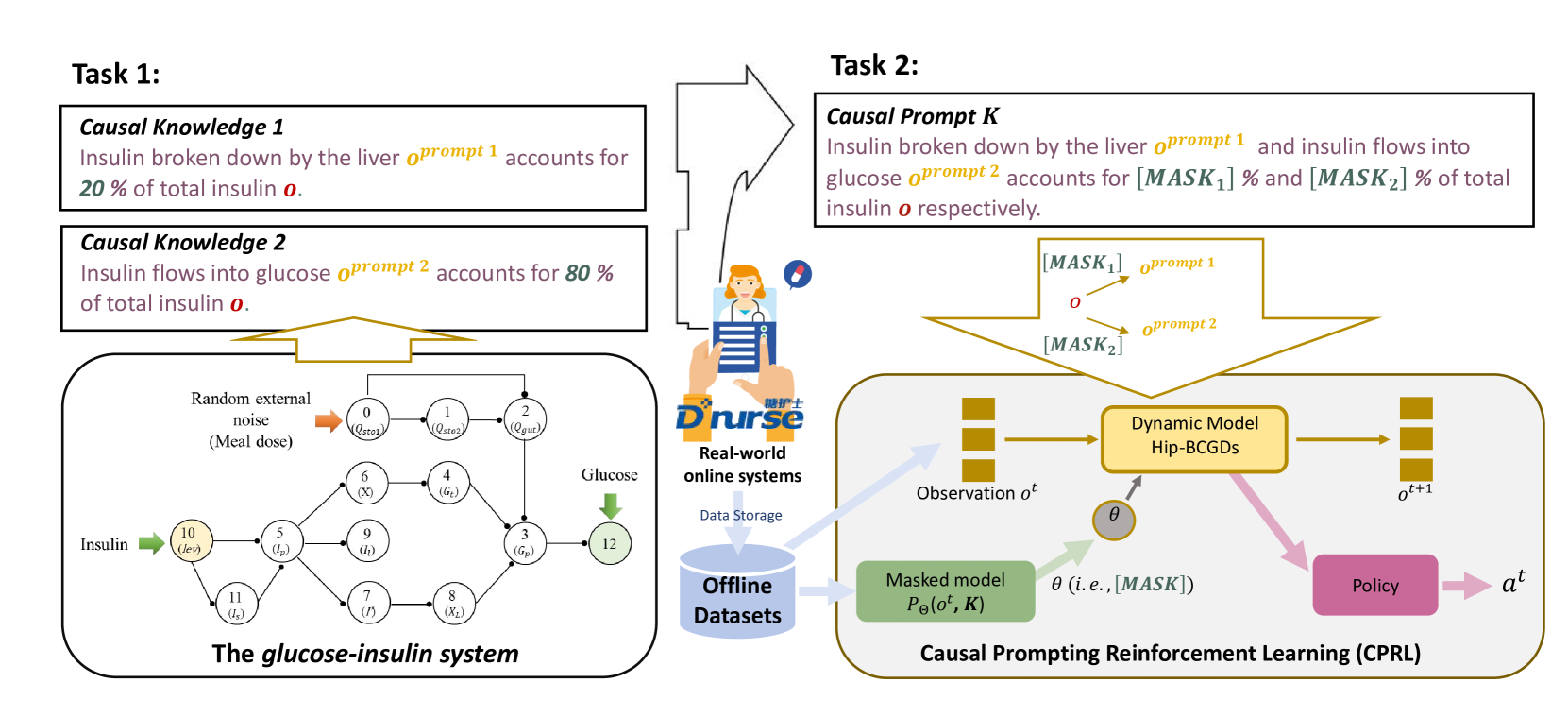
Model-based offline Reinforcement Learning (RL) allows agents to fully utilise pre-collected datasets without requiring additional or unethical explorations. However, applying model-based offline RL to online systems presents challenges, primarily due to the highly suboptimal (noise-filled) and diverse nature of datasets generated by online systems. To tackle these issues, we introduce the Causal Prompting Reinforcement Learning (CPRL) framework, designed for highly suboptimal and resource-constrained online scenarios. The initial phase of CPRL involves the introduction of the Hidden-Parameter Block Causal Prompting Dynamic (Hip-BCPD) to model environmental dynamics. This approach utilises invariant causal prompts and aligns hidden parameters to generalise to new and diverse online users. In the subsequent phase, a single policy is trained to address multiple tasks through the amalgamation of reusable skills, circumventing the need for training from scratch. Experiments conducted across datasets with varying levels of noise, including simulation-based and real-world offline datasets from the Dnurse APP, demonstrate that our proposed method can make robust decisions in out-of-distribution and noisy environments, outperforming contemporary algorithms. Additionally, we separately verify the contributions of Hip-BCPDs and the skill-reuse strategy to the robustness of performance. We further analyse the visualised structure of Hip-BCPD and the interpretability of sub-skills. We released our source code and the first ever real-world medical dataset for precise medical decision-making tasks.
Create account to get full access
Overview
- This paper introduces a novel approach called "Causal Prompting Model-based Offline Reinforcement Learning" (CPMORL) for improving the efficiency and performance of offline reinforcement learning.
- Offline reinforcement learning, also known as batch reinforcement learning, involves learning policies from previously collected data without any further environment interactions.
- The key idea behind CPMORL is to leverage causal prompting, a technique that allows models to reason about causal relationships, to enhance the offline reinforcement learning process.
Plain English Explanation
The researchers have developed a new method called "Causal Prompting Model-based Offline Reinforcement Learning" (CPMORL) that aims to make offline reinforcement learning more effective and efficient. Offline reinforcement learning is a type of machine learning where an agent learns a policy (a way of making decisions) based on previously collected data, without interacting with the environment further.
The key innovation in CPMORL is the use of "causal prompting," a technique that allows the model to reason about the underlying causal relationships in the data. By understanding these causal connections, the model can make better decisions and learn more effective policies from the available offline data. This is in contrast to traditional offline reinforcement learning methods, which may struggle to extract the right insights from the data.
The researchers believe that CPMORL can lead to significant improvements in the performance and sample efficiency of offline reinforcement learning, making it a more practical and useful tool for a variety of real-world applications where data collection is costly or difficult, such as robotics or healthcare.
Technical Explanation
The paper introduces a novel approach called "Causal Prompting Model-based Offline Reinforcement Learning" (CPMORL) that leverages causal prompting to enhance the performance and efficiency of offline reinforcement learning.
Offline reinforcement learning, also known as batch reinforcement learning, involves learning policies from previously collected data without any further environment interactions. This is in contrast to traditional reinforcement learning, where an agent learns by actively interacting with the environment.
The key innovation in CPMORL is the use of causal prompting, a technique that allows models to reason about causal relationships in the data. By understanding these causal connections, the model can make more informed decisions and learn more effective policies from the available offline data.
The paper presents a detailed algorithm for CPMORL, which includes steps for causal model learning, causal prompting, and policy optimization. The researchers evaluate their approach on several benchmark tasks and demonstrate significant improvements in performance and sample efficiency compared to traditional offline reinforcement learning methods.
Critical Analysis
The paper presents a promising approach for improving the efficiency and performance of offline reinforcement learning through the use of causal prompting. The authors provide a thorough technical explanation of their method and demonstrate its effectiveness on a range of benchmark tasks.
However, the paper does not address some potential limitations and areas for further research. For example, the reliance on accurate causal models could be a bottleneck, as learning these models from limited offline data may be challenging in practice. Additionally, the paper does not explore the robustness of CPMORL to different types of distributional shift, which is a key concern in offline reinforcement learning.
Further research could also investigate the scalability of CPMORL to more complex, high-dimensional environments, as well as its applicability to real-world domains, such as robotics or healthcare, where offline data is often the primary source of information.
Conclusion
The Causal Prompting Model-based Offline Reinforcement Learning (CPMORL) approach presented in this paper offers a promising solution for improving the efficiency and performance of offline reinforcement learning. By leveraging causal prompting to reason about the underlying causal relationships in the data, CPMORL can learn more effective policies from limited offline data, potentially leading to significant advancements in applications where data collection is costly or difficult.
While the paper presents a strong technical foundation and demonstrates the effectiveness of CPMORL on benchmark tasks, further research is needed to address potential limitations and explore its real-world applicability. Continued advancements in this area could have far-reaching implications for the field of reinforcement learning and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Discrete Prompt Compression with Reinforcement Learning
Hoyoun Jung, Kyung-Joong Kim
0
0
Compressed prompts aid instruction-tuned language models (LMs) in overcoming context window limitations and reducing computational costs. Existing methods, which primarily based on training embeddings, face various challenges associated with interpretability, the fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), which is a discrete prompt compression method that addresses these issues. The proposed PCRL method utilizes a computationally efficient policy network that edits prompts directly. The training approach employed in the proposed PCRLs can be applied flexibly to various types of LMs, including both decoder-only and encoder-decoder architecture and it can be trained without gradient access to the LMs or labeled data. The proposed PCRL achieves an average reduction of 24.6% in terms of the token count across various instruction prompts while maintaining sufficient performance. In addition, we demonstrate that the learned policy can be transferred to larger LMs, and through a comprehensive analysis, we explore the token importance within the prompts. Our code is accessible at https://github.com/nenomigami/PromptCompressor.
6/4/2024
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
0
0
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
6/27/2024
🏅
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
0
0
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
6/6/2024
🐍
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
0
0
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
6/5/2024