HyDiscGAN: A Hybrid Distributed cGAN for Audio-Visual Privacy Preservation in Multimodal Sentiment Analysis
2404.11938
0
0

Abstract
Multimodal Sentiment Analysis (MSA) aims to identify speakers' sentiment tendencies in multimodal video content, raising serious concerns about privacy risks associated with multimodal data, such as voiceprints and facial images. Recent distributed collaborative learning has been verified as an effective paradigm for privacy preservation in multimodal tasks. However, they often overlook the privacy distinctions among different modalities, struggling to strike a balance between performance and privacy preservation. Consequently, it poses an intriguing question of maximizing multimodal utilization to improve performance while simultaneously protecting necessary modalities. This paper forms the first attempt at modality-specified (i.e., audio and visual) privacy preservation in MSA tasks. We propose a novel Hybrid Distributed cross-modality cGAN framework (HyDiscGAN), which learns multimodality alignment to generate fake audio and visual features conditioned on shareable de-identified textual data. The objective is to leverage the fake features to approximate real audio and visual content to guarantee privacy preservation while effectively enhancing performance. Extensive experiments show that compared with the state-of-the-art MSA model, HyDiscGAN can achieve superior or competitive performance while preserving privacy.
Create account to get full access
Overview
- Proposes a novel hybrid distributed conditional generative adversarial network (HyDiscGAN) for audio-visual privacy preservation in multimodal sentiment analysis
- Combines distributed GAN training with conditional inputs to generate realistic synthetic data while preserving privacy
- Aims to improve multimodal sentiment analysis performance while protecting sensitive audio-visual information
Plain English Explanation
This research paper introduces a new machine learning model called HyDiscGAN that is designed to protect people's privacy while still allowing for effective analysis of their emotions and opinions (sentiment analysis) using audio and visual data.
Typically, sentiment analysis uses real-world audio and video recordings of people, which can raise privacy concerns. The HyDiscGAN model instead learns to generate synthetic (fake) audio and video data that preserves the underlying emotional information, but hides the identities and other sensitive details of the people involved.
The key innovations of HyDiscGAN are: 1) it uses a distributed training approach to improve efficiency and scalability, and 2) it incorporates "conditional" inputs that allow the model to generate data tailored to specific analysis tasks, like sentiment detection. By combining these techniques, HyDiscGAN can produce realistic synthetic data that maintains privacy while still supporting useful multimodal sentiment analysis.
Technical Explanation
The HyDiscGAN paper proposes a novel hybrid distributed conditional generative adversarial network (HyDiscGAN) architecture for audio-visual privacy preservation in multimodal sentiment analysis. The core idea is to leverage the distributed and conditional aspects of GANs to generate realistic synthetic data that preserves the underlying emotional information while obfuscating sensitive personal details.
The distributed training approach similar to MCL-GAN allows HyDiscGAN to scale to large datasets efficiently on a single GPU. Meanwhile, the conditional inputs as in agent-driven generative semantic communication enable the model to generate data tailored to specific analysis tasks, like detecting sentiment from audio-visual cues.
The authors demonstrate that HyDiscGAN outperforms prior work on weakly supervised audio separation for multimodal sentiment analysis, while also providing strong differential privacy guarantees to protect individual privacy.
Critical Analysis
The HyDiscGAN paper presents a promising approach to balancing the needs of multimodal sentiment analysis with the imperative of protecting individual privacy. By generating synthetic data, the model avoids the ethical and legal issues associated with using real audio-visual recordings.
That said, the authors acknowledge several limitations and areas for future work. For example, the current HyDiscGAN architecture may not generalize well to diverse datasets, and the conditional inputs could potentially leak sensitive information if not designed carefully. Additionally, the paper does not explore the long-term societal impacts of deploying such a system at scale.
Overall, the HyDiscGAN research represents an important step forward in the quest to enable beneficial AI applications while respecting fundamental rights to privacy. However, ongoing scrutiny and responsible development will be essential to ensure these techniques are deployed ethically and equitably.
Conclusion
The HyDiscGAN model introduced in this paper offers a novel solution to the challenge of preserving privacy in multimodal sentiment analysis. By combining distributed GAN training with conditional inputs, the system can generate realistic synthetic data that maintains the emotional information needed for analysis tasks while protecting sensitive personal details.
This work demonstrates the potential for advanced machine learning techniques like GANs to enable valuable applications while respecting individual privacy. As AI systems become more pervasive in our lives, it will be crucial to develop innovative approaches like HyDiscGAN that balance competing needs and uphold ethical principles. With continued research and responsible deployment, this technology could have significant positive impacts on fields like mental health, customer experience, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
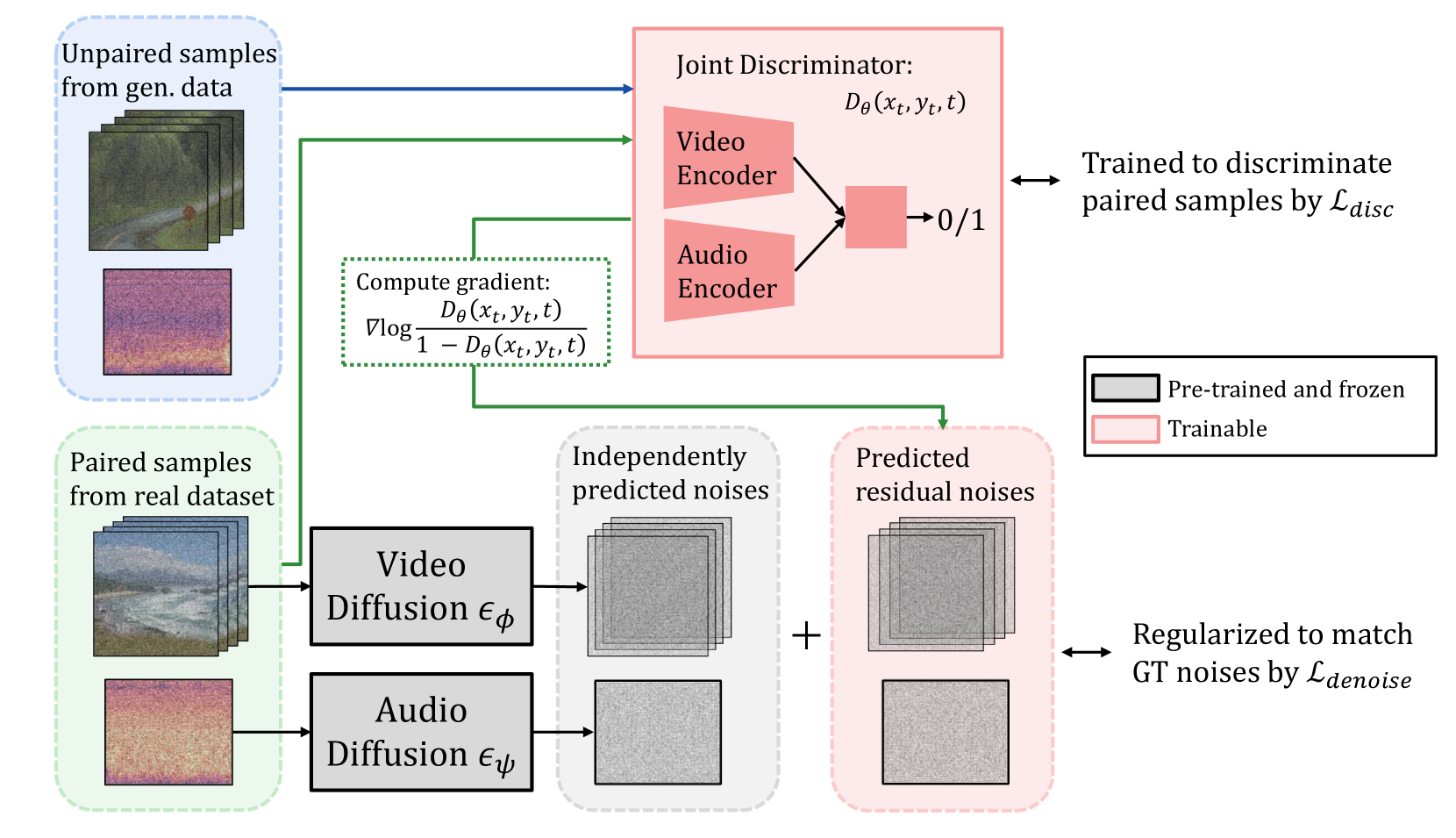
Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
Akio Hayakawa, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.
5/29/2024
🌐
HAGAN: Hybrid Augmented Generative Adversarial Network for Medical Image Synthesis
Zhihan Ju, Wanting Zhou, Longteng Kong, Yu Chen, Yi Li, Zhenan Sun, Caifeng Shan
0
0
Medical Image Synthesis (MIS) plays an important role in the intelligent medical field, which greatly saves the economic and time costs of medical diagnosis. However, due to the complexity of medical images and similar characteristics of different tissue cells, existing methods face great challenges in meeting their biological consistency. To this end, we propose the Hybrid Augmented Generative Adversarial Network (HAGAN) to maintain the authenticity of structural texture and tissue cells. HAGAN contains Attention Mixed (AttnMix) Generator, Hierarchical Discriminator and Reverse Skip Connection between Discriminator and Generator. The AttnMix consistency differentiable regularization encourages the perception in structural and textural variations between real and fake images, which improves the pathological integrity of synthetic images and the accuracy of features in local areas. The Hierarchical Discriminator introduces pixel-by-pixel discriminant feedback to generator for enhancing the saliency and discriminance of global and local details simultaneously. The Reverse Skip Connection further improves the accuracy for fine details by fusing real and synthetic distribution features. Our experimental evaluations on three datasets of different scales, i.e., COVID-CT, ACDC and BraTS2018, demonstrate that HAGAN outperforms the existing methods and achieves state-of-the-art performance in both high-resolution and low-resolution.
5/9/2024
🌐
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
0
0
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
5/28/2024
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, Jos'e Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli
0
0
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
5/24/2024