Disentangling Visual Priors: Unsupervised Learning of Scene Interpretations with Compositional Autoencoder

0
Sign in to get full access
Overview
- This paper explores an unsupervised learning approach to scene interpretation using a compositional autoencoder.
- The goal is to disentangle visual priors and learn interpretable scene representations without supervised labeling.
- The proposed model can decompose scenes into meaningful elements and learn how they can be composed to represent diverse scenes.
Plain English Explanation
The paper proposes a new way to help computers better understand the contents of images. Often, teaching computers to recognize objects, scenes, and other visual elements requires a lot of labeled training data, which can be time-consuming and expensive to create.
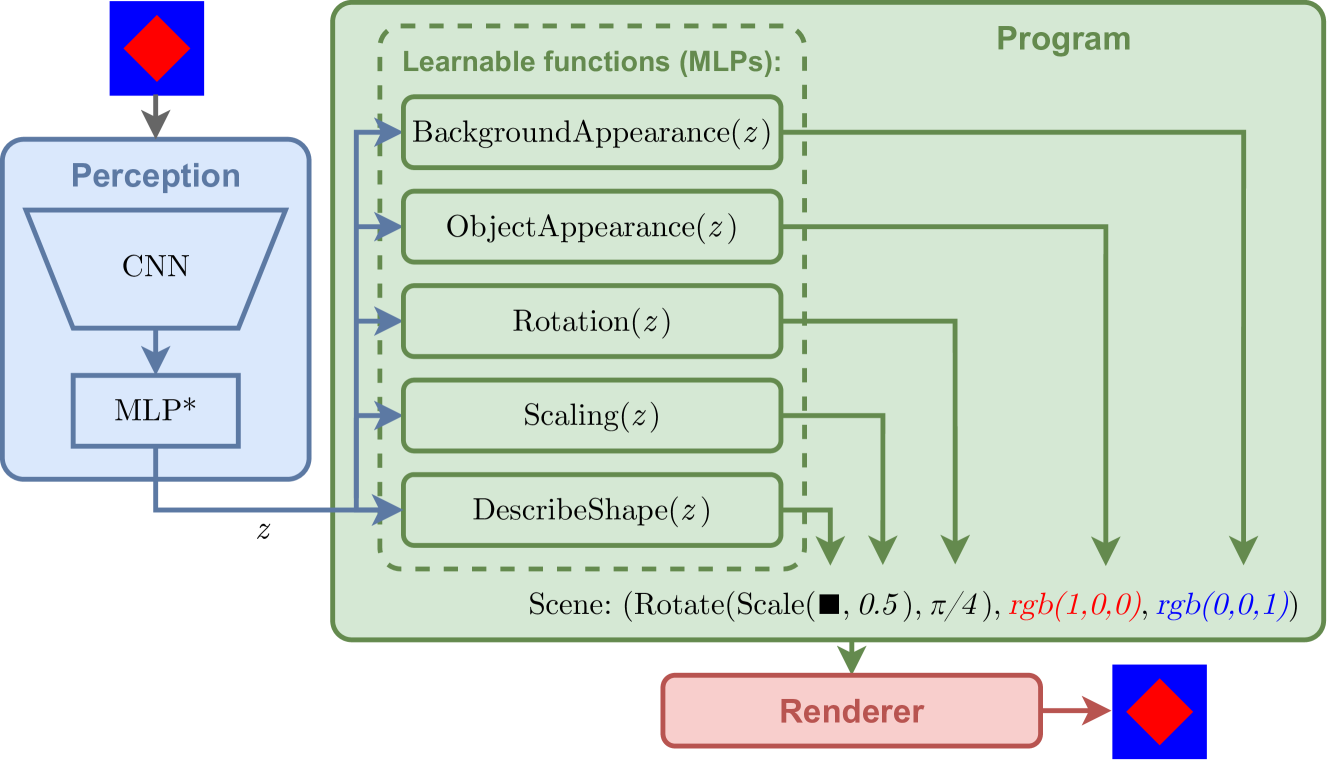
This research explores an unsupervised approach, where the model can learn to interpret visual scenes without being explicitly told what's in the images. The key idea is to use a [object Object] - a neural network that can break down images into simpler, interpretable elements, and then learn how to put those elements back together in different ways to represent diverse scenes.
By disentangling the underlying "visual priors" - the common patterns and structures that make up scenes - the model can learn a more flexible and generalizable representation of visual information. This could lead to better [object Object] of image understanding, with applications in areas like [object Object] and [object Object].
Technical Explanation
The core of the proposed approach is a compositional autoencoder that can decompose images into a set of interpretable elements and learn how to recompose them to represent diverse visual scenes. This is achieved through a neural network architecture with several key components:
- Scene Encoder: This part of the model takes an input image and encodes it into a set of latent variables that represent the underlying scene elements and their spatial relationships.
- Scene Decoder: The decoder network takes the latent representation and generates a reconstructed image by composing the learned scene elements.
- Disentanglement Regularizer: To encourage the model to learn interpretable and disentangled scene representations, the authors introduce a regularization term that promotes independence between the latent variables.
The model is trained in an unsupervised manner on a dataset of natural images. During training, the autoencoder learns to efficiently encode the input images into a compact, disentangled latent representation, and then reconstruct the original images from this representation.
The authors evaluate their approach on several benchmarks, demonstrating that the learned scene representations are more interpretable and generalizable compared to traditional autoencoder models. They also show that the compositional nature of the model allows for interesting applications, such as scene editing and image generation.
Critical Analysis
The paper presents a compelling approach to unsupervised scene interpretation, with several notable strengths:
- Interpretability: The proposed model can learn disentangled and interpretable representations of visual scenes, which is an important step towards making AI systems more transparent and explainable.
- Generalization: By learning to decompose scenes into reusable elements, the model can potentially generalize to a wider range of visual inputs, beyond the training data.
- Potential Applications: The compositional nature of the learned representations opens up interesting possibilities for applications like image editing, generation, and scene understanding.
However, the paper also acknowledges several limitations and areas for further research:
- Dataset Bias: The model's performance may be sensitive to the specific distribution of the training data, and it's unclear how well the approach would generalize to more diverse or challenging visual domains.
- Architectural Choices: The authors mention that the specific neural network architecture and hyperparameters used in the experiments can have a significant impact on the learned representations, and more work is needed to understand the best design choices.
- Evaluation Metrics: The paper relies on qualitative evaluations and proxy metrics (e.g., reconstruction quality) to assess the interpretability and disentanglement of the learned representations. More work is needed to develop robust, quantitative evaluation methods for this type of unsupervised learning.
Overall, the paper presents an interesting and promising approach to unsupervised scene interpretation, but further research is needed to fully understand the capabilities and limitations of the proposed model.
Conclusion
This research explores a novel unsupervised learning approach to scene interpretation, using a compositional autoencoder to disentangle visual priors and learn interpretable representations of visual scenes. By decomposing images into reusable elements and learning how to recompose them, the model can potentially generalize to a wider range of visual inputs and enable interesting applications in areas like image editing and scene understanding.
While the paper demonstrates promising results, it also highlights the need for further research to address limitations around dataset bias, architectural choices, and evaluation metrics. Nonetheless, this work represents an important step towards developing more flexible and interpretable AI systems for understanding and interacting with the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Disentangling Visual Priors: Unsupervised Learning of Scene Interpretations with Compositional Autoencoder
Krzysztof Krawiec, Antoni Nowinowski
Contemporary deep learning architectures lack principled means for capturing and handling fundamental visual concepts, like objects, shapes, geometric transforms, and other higher-level structures. We propose a neurosymbolic architecture that uses a domain-specific language to capture selected priors of image formation, including object shape, appearance, categorization, and geometric transforms. We express template programs in that language and learn their parameterization with features extracted from the scene by a convolutional neural network. When executed, the parameterized program produces geometric primitives which are rendered and assessed for correspondence with the scene content and trained via auto-association with gradient. We confront our approach with a baseline method on a synthetic benchmark and demonstrate its capacity to disentangle selected aspects of the image formation process, learn from small data, correct inference in the presence of noise, and out-of-sample generalization.
Read more9/17/2024
🧠
0
Pix2Code: Learning to Compose Neural Visual Concepts as Programs
Antonia Wust, Wolfgang Stammer, Quentin Delfosse, Devendra Singh Dhami, Kristian Kersting
The challenge in learning abstract concepts from images in an unsupervised fashion lies in the required integration of visual perception and generalizable relational reasoning. Moreover, the unsupervised nature of this task makes it necessary for human users to be able to understand a model's learnt concepts and potentially revise false behaviours. To tackle both the generalizability and interpretability constraints of visual concept learning, we propose Pix2Code, a framework that extends program synthesis to visual relational reasoning by utilizing the abilities of both explicit, compositional symbolic and implicit neural representations. This is achieved by retrieving object representations from images and synthesizing relational concepts as lambda-calculus programs. We evaluate the diverse properties of Pix2Code on the challenging reasoning domains, Kandinsky Patterns and CURI, thereby testing its ability to identify compositional visual concepts that generalize to novel data and concept configurations. Particularly, in stark contrast to neural approaches, we show that Pix2Code's representations remain human interpretable and can be easily revised for improved performance.
Read more7/9/2024

0
Self-supervised Photographic Image Layout Representation Learning
Zhaoran Zhao, Peng Lu, Xujun Peng, Wenhao Guo
In the domain of image layout representation learning, the critical process of translating image layouts into succinct vector forms is increasingly significant across diverse applications, such as image retrieval, manipulation, and generation. Most approaches in this area heavily rely on costly labeled datasets and notably lack in adapting their modeling and learning methods to the specific nuances of photographic image layouts. This shortfall makes the learning process for photographic image layouts suboptimal. In our research, we directly address these challenges. We innovate by defining basic layout primitives that encapsulate various levels of layout information and by mapping these, along with their interconnections, onto a heterogeneous graph structure. This graph is meticulously engineered to capture the intricate layout information within the pixel domain explicitly. Advancing further, we introduce novel pretext tasks coupled with customized loss functions, strategically designed for effective self-supervised learning of these layout graphs. Building on this foundation, we develop an autoencoder-based network architecture skilled in compressing these heterogeneous layout graphs into precise, dimensionally-reduced layout representations. Additionally, we introduce the LODB dataset, which features a broader range of layout categories and richer semantics, serving as a comprehensive benchmark for evaluating the effectiveness of layout representation learning methods. Our extensive experimentation on this dataset demonstrates the superior performance of our approach in the realm of photographic image layout representation learning.
Read more8/21/2024

0
Unsupervised Composable Representations for Audio
Giovanni Bindi, Philippe Esling
Current generative models are able to generate high-quality artefacts but have been shown to struggle with compositional reasoning, which can be defined as the ability to generate complex structures from simpler elements. In this paper, we focus on the problem of compositional representation learning for music data, specifically targeting the fully-unsupervised setting. We propose a simple and extensible framework that leverages an explicit compositional inductive bias, defined by a flexible auto-encoding objective that can leverage any of the current state-of-art generative models. We demonstrate that our framework, used with diffusion models, naturally addresses the task of unsupervised audio source separation, showing that our model is able to perform high-quality separation. Our findings reveal that our proposal achieves comparable or superior performance with respect to other blind source separation methods and, furthermore, it even surpasses current state-of-art supervised baselines on signal-to-interference ratio metrics. Additionally, by learning an a-posteriori masking diffusion model in the space of composable representations, we achieve a system capable of seamlessly performing unsupervised source separation, unconditional generation, and variation generation. Finally, as our proposal works in the latent space of pre-trained neural audio codecs, it also provides a lower computational cost with respect to other neural baselines.
Read more8/20/2024