Learning to Infer Generative Template Programs for Visual Concepts
2403.15476
2
0

Abstract
People grasp flexible visual concepts from a few examples. We explore a neurosymbolic system that learns how to infer programs that capture visual concepts in a domain-general fashion. We introduce Template Programs: programmatic expressions from a domain-specific language that specify structural and parametric patterns common to an input concept. Our framework supports multiple concept-related tasks, including few-shot generation and co-segmentation through parsing. We develop a learning paradigm that allows us to train networks that infer Template Programs directly from visual datasets that contain concept groupings. We run experiments across multiple visual domains: 2D layouts, Omniglot characters, and 3D shapes. We find that our method outperforms task-specific alternatives, and performs competitively against domain-specific approaches for the limited domains where they exist.
Create account to get full access
Overview
- This paper proposes a novel approach to learning visual concepts by inferring generative template programs.
- The key idea is to learn a neural program that can generate instances of a visual concept, rather than just recognizing it.
- The authors demonstrate how this approach can be used for a variety of visual concepts, including simple shapes, complex objects, and even scenes.
Plain English Explanation
The researchers in this paper have developed a new way to teach computers about visual concepts, like different shapes, objects, and even entire scenes. Rather than just having the computer recognize these concepts, the approach allows the computer to actually generate, or create, new examples of the concepts.
The basic idea is to have the computer learn a "program" that can be used to generate new instances of a visual concept. This program is like a set of instructions that the computer can follow to create new examples of the concept. For example, the program for a circle might say "draw a loop with this radius," while the program for a house might say "draw a rectangle, add a triangle on top, and put windows and a door in certain places."
By learning these generative programs, the computer can do more than just recognize visual concepts - it can actually create new examples of them. This could be useful for all sorts of applications, like generating concept art or editing visual programs in an efficient way.
The paper shows how this approach can be applied to a wide range of visual concepts, from simple shapes to complex objects and even entire scenes. It's an interesting step towards data-efficient learning of neural programs and language-informed visual concept learning.
Technical Explanation
The key innovation in this paper is the use of generative template programs to represent visual concepts. Instead of just learning to recognize visual concepts, the authors propose learning a neural program that can generate new instances of those concepts.
The program induction process involves two main steps:
- Program Encoding: The authors use a neural network to encode a set of example instances of a visual concept into a compact program representation.
- Program Execution: This program representation is then executed by a differentiable program executor to generate new instances of the concept.
The authors demonstrate this approach on a variety of visual concepts, including simple shapes, complex objects, and even compositional visual scenes. They show that the learned programs can be used to efficiently generate new examples of the concepts, even in a few-shot learning setting.
Critical Analysis
One potential limitation of this approach is the reliance on a fixed set of low-level "primitives" that the programs can use to generate new instances. While the authors show that this can be effective, it may limit the expressiveness and flexibility of the learned programs. Exploring more open-ended program representations could be an interesting direction for future work.
Additionally, the training process for the program induction model is quite complex, involving a combination of supervised and unsupervised learning. It's not clear how robust this approach would be to different types of visual concepts or data distributions, and further research would be needed to understand its limitations and failure modes.
Overall, this paper represents an intriguing step towards more data-efficient learning of neural programs and language-informed visual concept learning. While there are still some open challenges, the idea of learning generative template programs for visual concepts is a promising direction for advancing our understanding of how humans and machines can learn and represent visual knowledge.
Conclusion
This paper presents a novel approach to learning visual concepts by inferring generative template programs. By learning a neural program that can generate new instances of a concept, rather than just recognizing it, the authors demonstrate a more flexible and expressive way of representing visual knowledge.
The potential applications of this work are wide-ranging, from more efficient and intuitive visual editing tools to better data-efficient learning of neural programs and deeper language-informed visual concept learning. While there are still some challenges to overcome, this research represents an exciting step towards more advanced and versatile visual understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
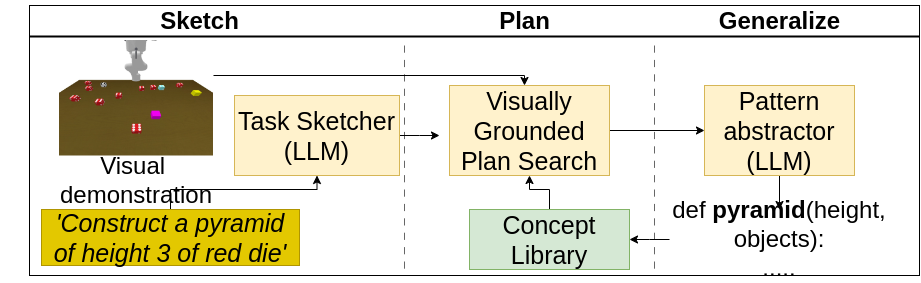
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Namasivayam Kalithasan, Sachit Sachdeva, Himanshu Gaurav Singh, Vishal Bindal, Arnav Tuli, Gurarmaan Singh Panjeta, Divyanshu Aggarwal, Rohan Paul, Parag Singla
0
0
Our goal is to enable embodied agents to learn inductively generalizable spatial concepts, e.g., learning staircase as an inductive composition of towers of increasing height. Given a human demonstration, we seek a learning architecture that infers a succinct ${program}$ representation that explains the observed instance. Additionally, the approach should generalize inductively to novel structures of different sizes or complex structures expressed as a hierarchical composition of previously learned concepts. Existing approaches that use code generation capabilities of pre-trained large (visual) language models, as well as purely neural models, show poor generalization to a-priori unseen complex concepts. Our key insight is to factor inductive concept learning as (i) ${it Sketch:}$ detecting and inferring a coarse signature of a new concept (ii) ${it Plan:}$ performing MCTS search over grounded action sequences (iii) ${it Generalize:}$ abstracting out grounded plans as inductive programs. Our pipeline facilitates generalization and modular reuse, enabling continual concept learning. Our approach combines the benefits of the code generation ability of large language models (LLM) along with grounded neural representations, resulting in neuro-symbolic programs that show stronger inductive generalization on the task of constructing complex structures in relation to LLM-only and neural-only approaches. Furthermore, we demonstrate reasoning and planning capabilities with learned concepts for embodied instruction following.
5/30/2024

Learning to Edit Visual Programs with Self-Supervision
R. Kenny Jones, Renhao Zhang, Aditya Ganeshan, Daniel Ritchie
0
0
We design a system that learns how to edit visual programs. Our edit network consumes a complete input program and a visual target. From this input, we task our network with predicting a local edit operation that could be applied to the input program to improve its similarity to the target. In order to apply this scheme for domains that lack program annotations, we develop a self-supervised learning approach that integrates this edit network into a bootstrapped finetuning loop along with a network that predicts entire programs in one-shot. Our joint finetuning scheme, when coupled with an inference procedure that initializes a population from the one-shot model and evolves members of this population with the edit network, helps to infer more accurate visual programs. Over multiple domains, we experimentally compare our method against the alternative of using only the one-shot model, and find that even under equal search-time budgets, our editing-based paradigm provides significant advantages.
6/5/2024
⛏️
Language-Informed Visual Concept Learning
Sharon Lee, Yunzhi Zhang, Shangzhe Wu, Jiajun Wu
0
0
Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
4/4/2024

Data-Efficient Learning with Neural Programs
Alaia Solko-Breslin, Seewon Choi, Ziyang Li, Neelay Velingker, Rajeev Alur, Mayur Naik, Eric Wong
0
0
Many computational tasks can be naturally expressed as a composition of a DNN followed by a program written in a traditional programming language or an API call to an LLM. We call such composites neural programs and focus on the problem of learning the DNN parameters when the training data consist of end-to-end input-output labels for the composite. When the program is written in a differentiable logic programming language, techniques from neurosymbolic learning are applicable, but in general, the learning for neural programs requires estimating the gradients of black-box components. We present an algorithm for learning neural programs, called ISED, that only relies on input-output samples of black-box components. For evaluation, we introduce new benchmarks that involve calls to modern LLMs such as GPT-4 and also consider benchmarks from the neurosymolic learning literature. Our evaluation shows that for the latter benchmarks, ISED has comparable performance to state-of-the-art neurosymbolic frameworks. For the former, we use adaptations of prior work on gradient approximations of black-box components as a baseline, and show that ISED achieves comparable accuracy but in a more data- and sample-efficient manner.
6/11/2024