Pix2Code: Learning to Compose Neural Visual Concepts as Programs

0
🧠
Sign in to get full access
Overview
- Challenges in learning abstract concepts from images in an unsupervised way
- Need to integrate visual perception and relational reasoning
- Unsupervised nature requires interpretable learned concepts for users to revise
Plain English Explanation
Learning abstract concepts from images without supervision is a challenging task. It requires integrating the ability to perceive visual information with the ability to reason about relationships between objects. Additionally, since this learning is unsupervised, it's important that the concepts a model learns are interpretable to human users. This way, users can understand the model's reasoning and potentially revise any false behaviors.
To address these constraints of generalizability and interpretability in visual concept learning, the researchers propose a framework called Pix2Code. Pix2Code extends program synthesis techniques to visual relational reasoning, using a combination of explicit, compositional symbolic representations and implicit neural representations.
Technical Explanation
The Pix2Code framework retrieves object representations from images and synthesizes relational concepts as lambda-calculus programs. This allows it to leverage the strengths of both symbolic and neural approaches to represent and reason about visual concepts.
The researchers evaluate Pix2Code on two challenging reasoning domains: Kandinsky Patterns and CURI. These datasets test Pix2Code's ability to identify compositional visual concepts that generalize to novel data and configurations.
Importantly, the researchers show that Pix2Code's representations remain human-interpretable, in contrast to purely neural approaches. This allows users to revise the model's behavior if necessary, as described in related work on concept learning and language-informed visual concept learning.
Critical Analysis
The paper presents a promising approach to addressing the challenges of learning abstract visual concepts in an unsupervised way. The use of a hybrid symbolic-neural framework is an interesting and potentially powerful solution.
However, the researchers acknowledge that Pix2Code has limitations, such as the need for extensive training data and the complexity of the program synthesis process. Additionally, the evaluation is focused on relatively simple, synthetic datasets, and it remains to be seen how well the approach would scale to more complex, real-world visual reasoning tasks.
Further research is needed to explore the broader applicability of Pix2Code and to address these limitations. Nonetheless, the work represents an important step towards developing more interpretable and generalizable visual reasoning systems.
Conclusion
The Pix2Code framework tackles the challenge of learning abstract visual concepts in an unsupervised way by combining symbolic and neural representations. This allows it to achieve both generalizability and interpretability, which are critical for developing visual reasoning systems that can be understood and revised by human users.
The promising results on the Kandinsky Patterns and CURI datasets suggest that this hybrid approach has the potential to advance the field of compositional visual reasoning. Further research is needed to explore the scalability and real-world applicability of Pix2Code, but the work represents an important contribution to the ongoing effort to create more interpretable and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Pix2Code: Learning to Compose Neural Visual Concepts as Programs
Antonia Wust, Wolfgang Stammer, Quentin Delfosse, Devendra Singh Dhami, Kristian Kersting
The challenge in learning abstract concepts from images in an unsupervised fashion lies in the required integration of visual perception and generalizable relational reasoning. Moreover, the unsupervised nature of this task makes it necessary for human users to be able to understand a model's learnt concepts and potentially revise false behaviours. To tackle both the generalizability and interpretability constraints of visual concept learning, we propose Pix2Code, a framework that extends program synthesis to visual relational reasoning by utilizing the abilities of both explicit, compositional symbolic and implicit neural representations. This is achieved by retrieving object representations from images and synthesizing relational concepts as lambda-calculus programs. We evaluate the diverse properties of Pix2Code on the challenging reasoning domains, Kandinsky Patterns and CURI, thereby testing its ability to identify compositional visual concepts that generalize to novel data and concept configurations. Particularly, in stark contrast to neural approaches, we show that Pix2Code's representations remain human interpretable and can be easily revised for improved performance.
Read more7/9/2024

0
Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Aleksandar Stani'c, Sergi Caelles, Michael Tschannen
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
Read more5/16/2024

1
Learning to Infer Generative Template Programs for Visual Concepts
R. Kenny Jones, Siddhartha Chaudhuri, Daniel Ritchie
People grasp flexible visual concepts from a few examples. We explore a neurosymbolic system that learns how to infer programs that capture visual concepts in a domain-general fashion. We introduce Template Programs: programmatic expressions from a domain-specific language that specify structural and parametric patterns common to an input concept. Our framework supports multiple concept-related tasks, including few-shot generation and co-segmentation through parsing. We develop a learning paradigm that allows us to train networks that infer Template Programs directly from visual datasets that contain concept groupings. We run experiments across multiple visual domains: 2D layouts, Omniglot characters, and 3D shapes. We find that our method outperforms task-specific alternatives, and performs competitively against domain-specific approaches for the limited domains where they exist.
Read more6/11/2024
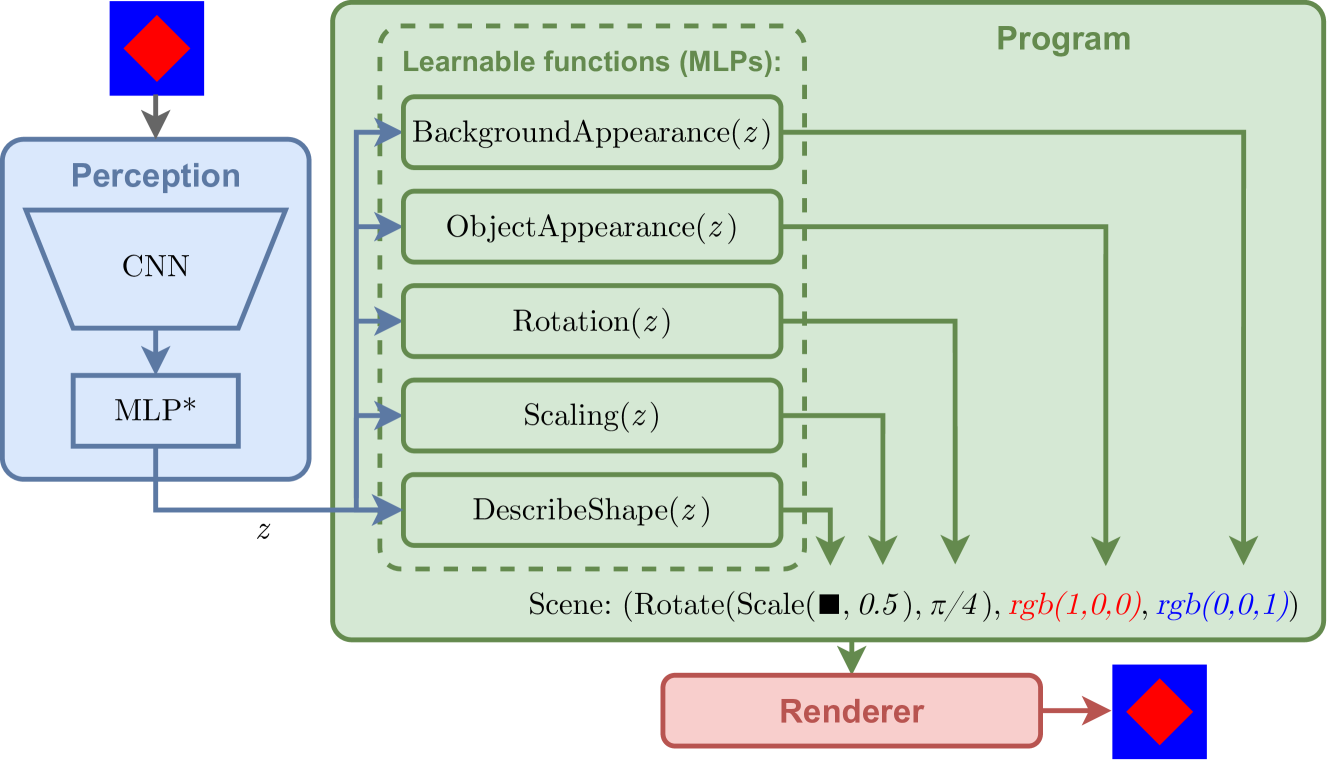
0
New!Disentangling Visual Priors: Unsupervised Learning of Scene Interpretations with Compositional Autoencoder
Krzysztof Krawiec, Antoni Nowinowski
Contemporary deep learning architectures lack principled means for capturing and handling fundamental visual concepts, like objects, shapes, geometric transforms, and other higher-level structures. We propose a neurosymbolic architecture that uses a domain-specific language to capture selected priors of image formation, including object shape, appearance, categorization, and geometric transforms. We express template programs in that language and learn their parameterization with features extracted from the scene by a convolutional neural network. When executed, the parameterized program produces geometric primitives which are rendered and assessed for correspondence with the scene content and trained via auto-association with gradient. We confront our approach with a baseline method on a synthetic benchmark and demonstrate its capacity to disentangle selected aspects of the image formation process, learn from small data, correct inference in the presence of noise, and out-of-sample generalization.
Read more9/17/2024