Disparate Impact on Group Accuracy of Linearization for Private Inference

0
Sign in to get full access
Overview
- This paper examines how linearization, a technique used to improve the privacy and efficiency of machine learning models, can have disparate impacts on the accuracy of different demographic groups.
- The authors investigate the trade-offs between accuracy, privacy, and fairness in the context of private inference.
- They propose several methods to mitigate the disparate impact of linearization, including Generalizing Orthogonalization Models for Non-Linearities, Differentially Private Post-processing for Fair Regression, and Individual Fairness through Reweighting & Tuning.
Plain English Explanation
Machine learning models are often used to make important decisions, like who gets approved for a loan or what kind of medical treatment someone receives. However, these models can sometimes be biased, leading to unfair outcomes for certain demographic groups.
One way to address this issue is by using a technique called "linearization," which can help improve the privacy and efficiency of the models. But this paper shows that linearization can also have unintended consequences, leading to disparities in the accuracy of the models for different groups.
The authors explore this problem in depth, looking at the trade-offs between accuracy, privacy, and fairness. They propose several methods to help mitigate the disparate impact of linearization, including techniques that generalize orthogonalization models for non-linear problems, use differential privacy to ensure fair regression outcomes, and adjust the weights and parameters of the model to improve individual fairness.
The goal of this research is to help ensure that machine learning models are not only accurate and efficient, but also fair and equitable for all members of society, regardless of their demographic background.
Technical Explanation
The paper explores the trade-offs between accuracy, privacy, and fairness in the context of private inference, where the goal is to protect the privacy of the data used to train the model while still maintaining accurate and fair predictions.
The authors focus on the use of linearization, a technique that can improve the privacy and efficiency of machine learning models by approximating the original non-linear model with a simpler linear one. However, they find that this linearization process can lead to disparate impacts on the accuracy of the model for different demographic groups.
To address this issue, the authors propose several methods:
-
Generalizing Orthogonalization Models for Non-Linearities: This approach generalizes the orthogonalization technique used in linear models to handle non-linear relationships, helping to mitigate the disparate impact of linearization.
-
Differentially Private Post-processing for Fair Regression: The authors use differential privacy, a technique for ensuring the privacy of individual data points, in combination with post-processing steps to improve the fairness of the regression model.
-
Individual Fairness through Reweighting & Tuning: This method adjusts the weights and parameters of the model to improve individual fairness, ensuring that the model performs equally well for all individuals, regardless of their demographic characteristics.
Through extensive experiments, the authors demonstrate the effectiveness of these approaches in mitigating the disparate impact of linearization and improving the overall fairness of the private inference system.
Critical Analysis
The authors of this paper have made a valuable contribution to the field of machine learning by highlighting the potential for disparate impacts when using linearization techniques. They have proposed several promising approaches to address this issue, which could have significant implications for the development of fair and equitable AI systems.
One potential limitation of the research is the specific focus on private inference, which may limit the generalizability of the findings to other machine learning contexts. Additionally, the authors note that their methods may introduce some trade-offs in terms of accuracy or computational complexity, which could be an area for further investigation.
It would also be interesting to see the authors explore the mitigation of nonlinear algorithmic bias in binary classification tasks or the use of low-rank finetuning to improve the fairness of large language models, as these related topics could provide additional insights and techniques for addressing the disparate impact of linearization.
Overall, this paper represents an important step forward in the ongoing effort to ensure that machine learning systems are not only accurate and efficient, but also fair and equitable for all members of society.
Conclusion
This paper highlights a critical issue in the field of machine learning: the potential for linearization techniques to have disparate impacts on the accuracy of models for different demographic groups. The authors have proposed several promising approaches to address this problem, including methods that leverage orthogonalization, differential privacy, and individual fairness adjustments.
The findings of this research have important implications for the development of fair and equitable AI systems, which are increasingly being used to make high-stakes decisions that can significantly impact people's lives. By ensuring that these systems do not perpetuate or exacerbate existing biases, we can work towards a more just and inclusive future.
As the field of machine learning continues to evolve, it will be crucial for researchers and practitioners to remain vigilant in identifying and mitigating the potential for disparate impacts, drawing on the insights and techniques presented in this and other related studies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Disparate Impact on Group Accuracy of Linearization for Private Inference
Saswat Das, Marco Romanelli, Ferdinando Fioretto
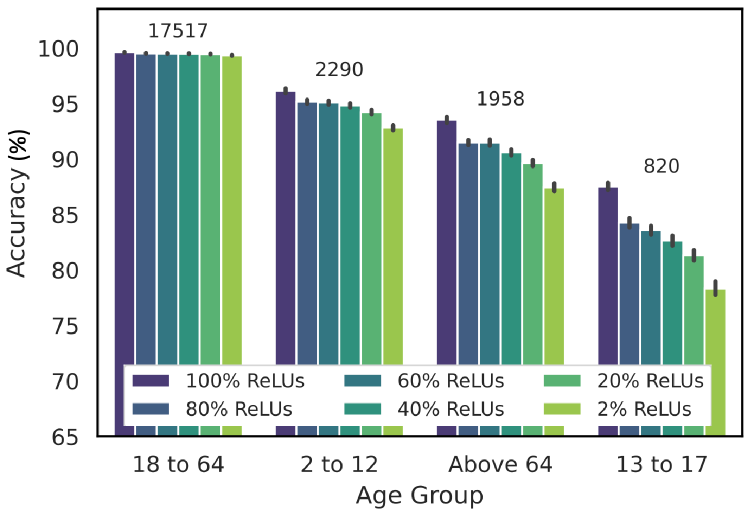
Ensuring privacy-preserving inference on cryptographically secure data is a well-known computational challenge. To alleviate the bottleneck of costly cryptographic computations in non-linear activations, recent methods have suggested linearizing a targeted portion of these activations in neural networks. This technique results in significantly reduced runtimes with often negligible impacts on accuracy. In this paper, we demonstrate that such computational benefits may lead to increased fairness costs. Specifically, we find that reducing the number of ReLU activations disproportionately decreases the accuracy for minority groups compared to majority groups. To explain these observations, we provide a mathematical interpretation under restricted assumptions about the nature of the decision boundary, while also showing the prevalence of this problem across widely used datasets and architectures. Finally, we show how a simple procedure altering the fine-tuning step for linearized models can serve as an effective mitigation strategy.
Read more8/21/2024

0
Generalizing Orthogonalization for Models with Non-linearities
David Rugamer, Chris Kolb, Tobias Weber, Lucas Kook, Thomas Nagler
The complexity of black-box algorithms can lead to various challenges, including the introduction of biases. These biases present immediate risks in the algorithms' application. It was, for instance, shown that neural networks can deduce racial information solely from a patient's X-ray scan, a task beyond the capability of medical experts. If this fact is not known to the medical expert, automatic decision-making based on this algorithm could lead to prescribing a treatment (purely) based on racial information. While current methodologies allow for the orthogonalization or normalization of neural networks with respect to such information, existing approaches are grounded in linear models. Our paper advances the discourse by introducing corrections for non-linearities such as ReLU activations. Our approach also encompasses scalar and tensor-valued predictions, facilitating its integration into neural network architectures. Through extensive experiments, we validate our method's effectiveness in safeguarding sensitive data in generalized linear models, normalizing convolutional neural networks for metadata, and rectifying pre-existing embeddings for undesired attributes.
Read more6/4/2024
↗️
0
Differentially Private Post-Processing for Fair Regression
Ruicheng Xian, Qiaobo Li, Gautam Kamath, Han Zhao
This paper describes a differentially private post-processing algorithm for learning fair regressors satisfying statistical parity, addressing privacy concerns of machine learning models trained on sensitive data, as well as fairness concerns of their potential to propagate historical biases. Our algorithm can be applied to post-process any given regressor to improve fairness by remapping its outputs. It consists of three steps: first, the output distributions are estimated privately via histogram density estimation and the Laplace mechanism, then their Wasserstein barycenter is computed, and the optimal transports to the barycenter are used for post-processing to satisfy fairness. We analyze the sample complexity of our algorithm and provide fairness guarantee, revealing a trade-off between the statistical bias and variance induced from the choice of the number of bins in the histogram, in which using less bins always favors fairness at the expense of error.
Read more5/8/2024
🔍
0
Individual Fairness Through Reweighting and Tuning
Abdoul Jalil Djiberou Mahamadou, Lea Goetz, Russ Altman
Inherent bias within society can be amplified and perpetuated by artificial intelligence (AI) systems. To address this issue, a wide range of solutions have been proposed to identify and mitigate bias and enforce fairness for individuals and groups. Recently, Graph Laplacian Regularizer (GLR), a regularization technique from the semi-supervised learning literature has been used as a substitute for the common Lipschitz condition to enhance individual fairness. Notable prior work has shown that enforcing individual fairness through a GLR can improve the transfer learning accuracy of AI models under covariate shifts. However, the prior work defines a GLR on the source and target data combined, implicitly assuming that the target data are available at train time, which might not hold in practice. In this work, we investigated whether defining a GLR independently on the train and target data could maintain similar accuracy. Furthermore, we introduced the Normalized Fairness Gain score (NFG) to measure individual fairness by measuring the amount of gained fairness when a GLR is used versus not. We evaluated the new and original methods under NFG, the Prediction Consistency (PC), and traditional classification metrics on the German Credit Approval dataset. The results showed that the two models achieved similar statistical mean performances over five-fold cross-validation. Furthermore, the proposed metric showed that PC scores can be misleading as the scores can be high and statistically similar to fairness-enhanced models while NFG scores are small. This work therefore provides new insights into when a GLR effectively enhances individual fairness and the pitfalls of PC.
Read more5/9/2024