Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
2405.13432
0
0
➖
Abstract
Supervised fine-tuning (SFT) on instruction-following corpus is a crucial approach toward the alignment of large language models (LLMs). However, the performance of LLMs on standard knowledge and reasoning benchmarks tends to suffer from deterioration at the latter stage of the SFT process, echoing the phenomenon of alignment tax. Through our pilot study, we put a hypothesis that the data biases are probably one cause behind the phenomenon. To address the issue, we introduce a simple disperse-then-merge framework. To be concrete, we disperse the instruction-following data into portions and train multiple sub-models using different data portions. Then we merge multiple models into a single one via model merging techniques. Despite its simplicity, our framework outperforms various sophisticated methods such as data curation and training regularization on a series of standard knowledge and reasoning benchmarks.
Create account to get full access
Overview
- Large language models (LLMs) are crucial for instruction-following tasks, but their performance on standard knowledge and reasoning benchmarks can suffer from a phenomenon called "alignment tax" towards the end of the supervised fine-tuning (SFT) process.
- The researchers hypothesize that data biases may be a cause of this alignment tax, and they introduce a simple "disperse-then-merge" framework to address the issue.
- Despite its simplicity, this framework outperforms more sophisticated methods like data curation and training regularization on various standard knowledge and reasoning benchmarks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. A crucial way to make these models better at following instructions is a process called supervised fine-tuning (SFT), where the model is trained on a dataset of instructions and their corresponding outputs.
However, the researchers found that as the SFT process progresses, the model's performance on standard tests of knowledge and reasoning can start to deteriorate. This is a problem known as "alignment tax," where the model becomes too focused on the specific instructions it was trained on and loses some of its broader capabilities.
The researchers suspect that this alignment tax may be caused by biases in the instruction-following data used for SFT. To address this, they developed a simple "disperse-then-merge" approach. Here's how it works:
- They split the instruction-following data into smaller portions.
- They train multiple "sub-models," each on a different data portion.
- Then, they combine these sub-models into a single, more robust model using a technique called "model merging."
Surprisingly, this straightforward approach outperformed more complex methods, like carefully curating the training data or using special regularization techniques during training. This suggests that the way the data is structured and combined can have a big impact on how well the final model performs, even on tasks outside of the specific instructions it was trained on.
Technical Explanation
The researchers conducted a pilot study to investigate the alignment tax phenomenon observed in LLMs during the SFT process on instruction-following tasks. They hypothesized that data biases might be a contributing factor to this issue.
To address the problem, the researchers introduced a simple "disperse-then-merge" framework. First, they split the instruction-following dataset into multiple portions. Then, they trained separate sub-models, each on a different data portion. Finally, they merged the sub-models into a single, consolidated model using model merging techniques.
Despite the simplicity of this approach, the researchers found that it outperformed more sophisticated methods, such as data curation and training regularization, on a range of standard knowledge and reasoning benchmarks. This suggests that the way the training data is structured and combined can have a significant impact on the final model's performance, even on tasks that are not directly related to the specific instructions it was trained on.
The researchers' findings highlight the importance of carefully considering the structure and composition of the training data when aligning LLMs to perform well on a wide range of tasks, beyond just the specific instructions they were trained on. This insight could inform the development of more effective instruction-tuning and alignment techniques for LLMs.
Critical Analysis
The researchers acknowledge that their study is a pilot and that further research is needed to fully understand the underlying causes of the alignment tax phenomenon and the effectiveness of the proposed disperse-then-merge framework.
One potential limitation of the study is that it focuses on a relatively narrow set of standard knowledge and reasoning benchmarks. It would be beneficial to evaluate the framework's performance on a broader range of tasks and datasets to better understand its generalizability.
Additionally, the researchers do not provide a detailed analysis of the specific biases present in the instruction-following data, nor do they explore how the disperse-then-merge approach might address these biases. A more in-depth investigation into the data characteristics and their impact on the model's performance could strengthen the findings.
Nevertheless, the researchers' work highlights the importance of considering data structure and composition when aligning LLMs, which could have important implications for the development of more effective instruction-following and alignment techniques.
Conclusion
The researchers' pilot study suggests that the way training data is structured and combined can have a significant impact on the performance of large language models (LLMs) on a wide range of tasks, beyond just the specific instructions they were trained on.
By introducing a simple "disperse-then-merge" framework, the researchers were able to outperform more sophisticated methods, such as data curation and training regularization, on standard knowledge and reasoning benchmarks. This highlights the importance of carefully considering the structure and composition of the training data when aligning LLMs to perform well on a diverse set of tasks.
The researchers' findings could inform the development of more effective instruction-following and alignment techniques for LLMs, with potential implications for a wide range of applications that rely on these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Phased Instruction Fine-Tuning for Large Language Models
Wei Pang, Chuan Zhou, Xiao-Hua Zhou, Xiaojie Wang
0
0
Instruction Fine-Tuning enhances pre-trained language models from basic next-word prediction to complex instruction-following. However, existing One-off Instruction Fine-Tuning (One-off IFT) method, applied on a diverse instruction, may not effectively boost models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To improve this, Phased Instruction Fine-Tuning (Phased IFT) is proposed, based on the idea that learning to follow instructions is a gradual process. It assesses instruction difficulty using GPT-4, divides the instruction data into subsets of increasing difficulty, and uptrains the model sequentially on these subsets. Experiments with Llama-2 7B/13B/70B, Llama3 8/70B and Mistral-7B models using Alpaca data show that Phased IFT significantly outperforms One-off IFT, supporting the progressive alignment hypothesis and providing a simple and efficient way to enhance large language models. Codes and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
6/18/2024
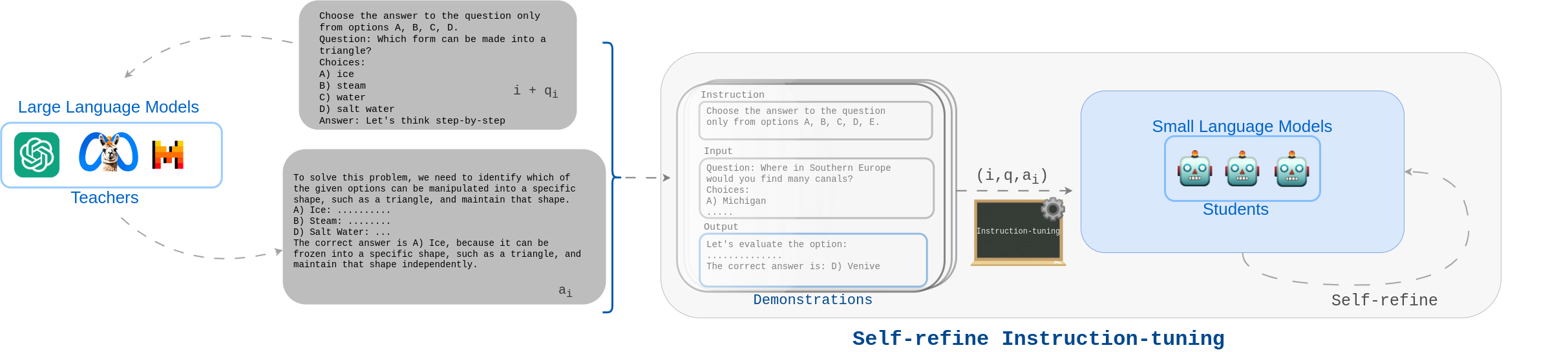
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
Leonardo Ranaldi, Andr`e Freitas
0
0
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
5/2/2024

How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, Jingren Zhou
0
0
Large language models (LLMs) with enormous pre-training tokens and parameters emerge diverse abilities, including math reasoning, code generation, and instruction following. These abilities are further enhanced by supervised fine-tuning (SFT). While the open-source community has explored ad-hoc SFT for enhancing individual capabilities, proprietary LLMs exhibit versatility across various skills. Therefore, understanding the facilitation of multiple abilities via SFT is paramount. In this study, we specifically focuses on the interplay of data composition between mathematical reasoning, code generation, and general human-aligning abilities during SFT. We propose four intriguing research questions to explore the association between model performance and various factors including data amount, composition ratio, model size and SFT strategies. Our experiments reveal that distinct capabilities scale differently and larger models generally show superior performance with same amount of data. Mathematical reasoning and code generation consistently improve with increasing data amount, whereas general abilities plateau after roughly a thousand samples. Moreover, we observe data composition appears to enhance various abilities under limited data conditions, yet can lead to performance conflicts when data is plentiful. Our findings also suggest the amount of composition data influences performance more than the composition ratio. In analysis of SFT strategies, we find that sequentially learning multiple skills risks catastrophic forgetting. Our proposed Dual-stage Mixed Fine-tuning (DMT) strategy offers a promising solution to learn multiple abilities with different scaling patterns.
6/10/2024

Optimizing and Testing Instruction-Following: Analyzing the Impact of Fine-Grained Instruction Variants on instruction-tuned LLMs
Jiuding Yang, Weidong Guo, Kaitong Yang, Xiangyang Li, Zhuwei Rao, Yu Xu, Di Niu
0
0
The effective alignment of Large Language Models (LLMs) with precise instructions is essential for their application in diverse real-world scenarios. Current methods focus on enhancing the diversity and complexity of training and evaluation samples, yet they fall short in accurately assessing LLMs' ability to follow similar instruction variants. We introduce an effective data augmentation technique that decomposes complex instructions into simpler sub-components, modifies these, and reconstructs them into new variants, thereby preserves the original instruction's context and complexity while introducing variability, which is critical for training and evaluating LLMs' instruction-following precision. We developed the DeMoRecon dataset using this method to both fine-tune and evaluate LLMs. Our findings show that LLMs fine-tuned with DeMoRecon will gain significant performance boost on both ours and commonly used instructions-following benchmarks.
6/18/2024