Phased Instruction Fine-Tuning for Large Language Models
2406.04371
0
0

Abstract
Instruction Fine-Tuning enhances pre-trained language models from basic next-word prediction to complex instruction-following. However, existing One-off Instruction Fine-Tuning (One-off IFT) method, applied on a diverse instruction, may not effectively boost models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To improve this, Phased Instruction Fine-Tuning (Phased IFT) is proposed, based on the idea that learning to follow instructions is a gradual process. It assesses instruction difficulty using GPT-4, divides the instruction data into subsets of increasing difficulty, and uptrains the model sequentially on these subsets. Experiments with Llama-2 7B/13B/70B, Llama3 8/70B and Mistral-7B models using Alpaca data show that Phased IFT significantly outperforms One-off IFT, supporting the progressive alignment hypothesis and providing a simple and efficient way to enhance large language models. Codes and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
Create account to get full access
Overview
- The paper explores a technique called "Phased Instruction Fine-Tuning" for improving the performance of large language models on a variety of tasks.
- The approach involves a multi-stage fine-tuning process that first trains the model on a broad set of instructions, then fine-tunes it on more specific instruction-based tasks.
- The authors demonstrate that this method outperforms traditional fine-tuning approaches on several benchmark datasets.
Plain English Explanation
Large language models like GPT-3 are powerful machine learning systems that can understand and generate human-like text. However, to perform well on specific tasks, these models often need to be "fine-tuned" on task-specific data.
The researchers in this paper propose a novel fine-tuning approach called "Phased Instruction Fine-Tuning" that aims to improve the model's performance on a wide range of instruction-based tasks. The key idea is to first train the model on a broad set of instructions, then fine-tune it on more specific instruction-based tasks.
This two-stage process helps the model learn general patterns and skills that can be applied to a variety of tasks, rather than just memorizing the details of a single task. The authors show that this approach outperforms traditional fine-tuning methods on several benchmark datasets, including instruction-tuning loss over instructions, BioInstruct, and Contrastive Instruction Tuning.
The intuition behind this approach is that by first learning a broad set of skills, the model can more effectively adapt to new, specific tasks, similar to how humans learn general principles before applying them to specific situations. This "transfer learning" allows the model to leverage its previous knowledge and perform better on new tasks.
Technical Explanation
The key elements of the Phased Instruction Fine-Tuning approach are:
-
Instruction Pretraining: The model is first trained on a diverse set of instructions, covering a wide range of tasks and domains. This helps the model learn general patterns and skills that can be applied to a variety of instruction-based tasks.
-
Instruction-Specific Fine-Tuning: After the initial pretraining, the model is fine-tuned on more specific instruction-based tasks, such as those in the Disperse Then Merge and Contrastive Instruction Tuning datasets. This allows the model to adapt its general knowledge to the specific requirements of each task.
The authors evaluate their approach on several benchmark datasets and compare it to traditional fine-tuning methods. They show that Phased Instruction Fine-Tuning consistently outperforms these baselines, demonstrating the effectiveness of the two-stage training process.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear explanation of the proposed method and a comprehensive evaluation on relevant datasets. However, there are a few potential caveats and areas for further research:
-
Computational and Memory Requirements: The two-stage training process may require more computational resources and memory compared to traditional fine-tuning approaches. The authors do not provide detailed information on the computational costs of their method.
-
Generalization to Other Tasks: While the paper demonstrates the effectiveness of Phased Instruction Fine-Tuning on instruction-based tasks, it is unclear how well the approach would generalize to other types of language modeling tasks, such as open-ended text generation or question answering.
-
Interpretation of Learned Representations: The paper does not delve deeply into the internal representations learned by the model during the different stages of training. Analyzing these representations could provide insights into how the phased approach affects the model's understanding of language and task-specific knowledge.
-
Potential Biases and Limitations: As with any machine learning model, there may be biases or limitations inherent in the datasets and tasks used for training and evaluation. The authors should address these potential issues and discuss ways to mitigate them in future research.
Conclusion
The Phased Instruction Fine-Tuning approach presented in this paper offers a promising method for improving the performance of large language models on a variety of instruction-based tasks. By first training the model on a broad set of instructions and then fine-tuning it on more specific tasks, the researchers demonstrate that their approach can outperform traditional fine-tuning techniques.
This work contributes to the ongoing efforts to enhance the capabilities of large language models and improve their ability to understand and follow complex instructions, which has important implications for a wide range of applications, from conversational AI assistants to task-oriented language models. While the paper identifies some potential areas for further research, the findings presented here represent a significant step forward in the field of instruction-based language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
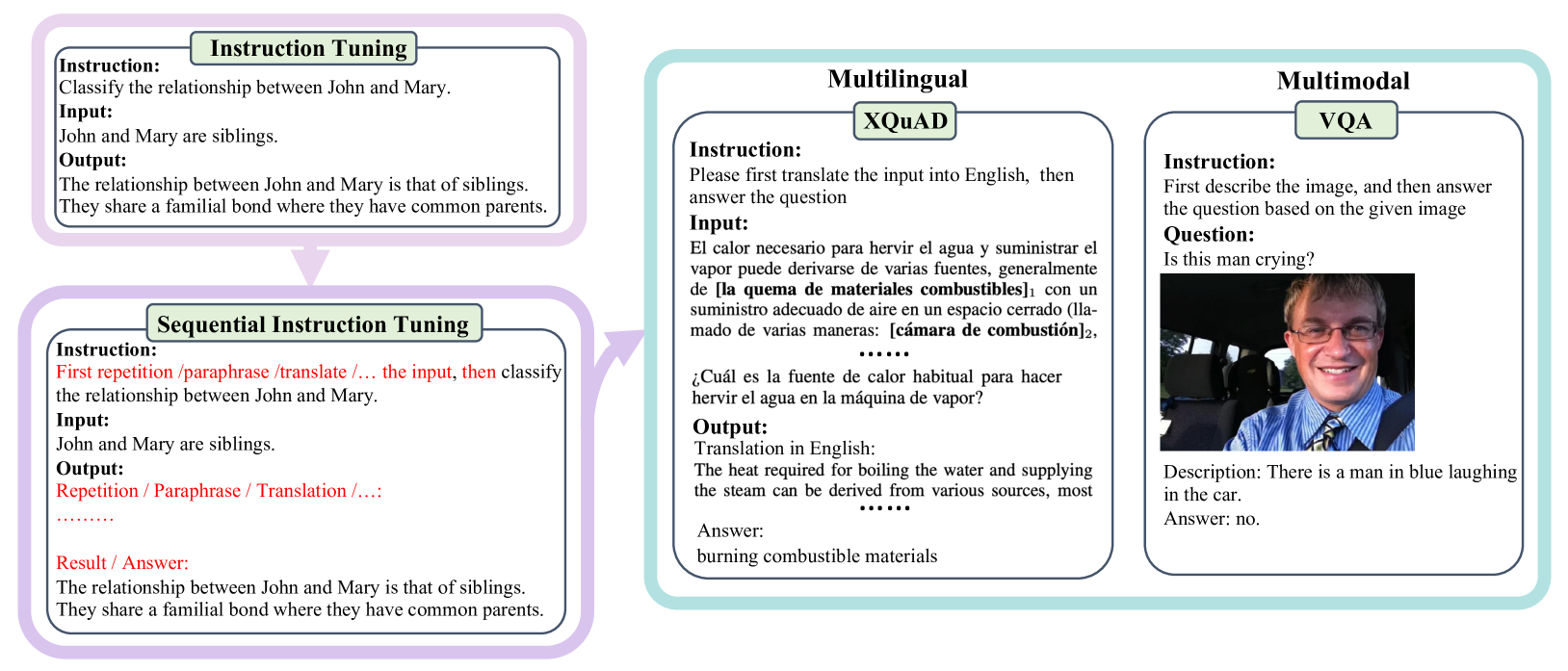
SIT: Fine-tuning Large Language Models with Sequential Instructions
Hanxu Hu, Simon Yu, Pinzhen Chen, Edoardo M. Ponti
0
0
Despite the success of existing instruction-tuned models, we find that they usually struggle to respond to queries with multiple instructions. This impairs their performance in complex problems whose solution consists of multiple intermediate tasks. Thus, we contend that part of the fine-tuning data mixture should be sequential--containing a chain of interrelated tasks. We first approach sequential instruction tuning from a task-driven perspective, manually creating interpretable intermediate tasks for multilingual and visual question answering: namely translate then predict and caption then answer. Next, we automate this process by turning instructions in existing datasets (e.g., Alpaca and FlanCoT) into diverse and complex sequential instructions, making our method general-purpose. Models that underwent our sequential instruction tuning show improved results in coding, maths, and open-ended generation. Moreover, we put forward a new benchmark named SeqEval to evaluate a model's ability to follow all the instructions in a sequence, which further corroborates the benefits of our fine-tuning method. We hope that our endeavours will open new research avenues on instruction tuning for complex tasks.
6/21/2024

Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou
0
0
One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
6/21/2024

InstructionCP: A fast approach to transfer Large Language Models into target language
Kuang-Ming Chen, Hung-yi Lee
0
0
The rapid development of large language models (LLMs) in recent years has largely focused on English, resulting in models that respond exclusively in English. To adapt these models to other languages, continual pre-training (CP) is often employed, followed by supervised fine-tuning (SFT) to maintain conversational abilities. However, CP and SFT can reduce a model's ability to filter harmful content. We propose Instruction Continual Pre-training (InsCP), which integrates instruction tags into the CP process to prevent loss of conversational proficiency while acquiring new languages. Our experiments demonstrate that InsCP retains conversational and Reinforcement Learning from Human Feedback (RLHF) abilities. Empirical evaluations on language alignment, reliability, and knowledge benchmarks confirm the efficacy of InsCP. Notably, this approach requires only 0.1 billion tokens of high-quality instruction-following data, thereby reducing resource consumption.
5/31/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024