XFT: Unlocking the Power of Code Instruction Tuning by Simply Merging Upcycled Mixture-of-Experts

0
🎲
Sign in to get full access
Overview
- Introduced a simple yet powerful training scheme called XFT
- XFT merges upcycled Mixture-of-Experts (MoE) to improve the performance of instruction-tuned code Large Language Models (LLMs)
- Vanilla sparse upcycling fails to improve instruction tuning, but XFT introduces a shared expert mechanism and a novel routing weight normalization strategy to significantly boost instruction tuning
- XFT also includes a learnable model merging mechanism to compile the upcycled MoE model back to a dense model, achieving upcycled MoE-level performance with only dense-model compute
Plain English Explanation
XFT is a new training method that aims to enhance the performance of large language models (LLMs) when they are used for code-related tasks, such as generating or understanding code. The key idea behind XFT is to combine the power of Mixture-of-Experts (MoE) models with a process called "upcycling."
Upcycling is a technique that takes a pre-trained model and transforms it into a more specialized and powerful model. However, the researchers found that simply applying upcycling to LLMs did not improve their performance on code-related tasks. To address this, XFT introduces a new mechanism where the experts in the MoE model share information and a novel way of normalizing the weights used to route inputs to the experts.
After this specialized training, XFT then uses a learnable merging process to combine the upcycled MoE model back into a dense model. This allows the model to maintain the performance benefits of the upcycled MoE, but with the efficiency of a dense model. The researchers were able to create a new state-of-the-art "tiny" code LLM (less than 3 billion parameters) using this approach, as well as improve the performance of existing models on a variety of code-related benchmarks.
Technical Explanation
The key innovation in XFT is the way it combines upcycling and MoE models to improve the performance of instruction-tuned code LLMs. Vanilla sparse upcycling, where a pre-trained model is fine-tuned on a specialized task, failed to significantly improve the models' performance on code-related tasks.
To address this, XFT introduces a "shared expert" mechanism, where the experts in the MoE model are allowed to share information with each other. This is combined with a novel "routing weight normalization" strategy, which helps the model learn better how to route inputs to the appropriate experts.
After this upcycling process, XFT then uses a learnable model merging mechanism to compile the upcycled MoE model back into a dense model. This allows the model to maintain the performance benefits of the upcycled MoE, but with the efficiency of a dense model.
The researchers applied XFT to a 1.3 billion parameter model, creating a new state-of-the-art "tiny" code LLM (less than 3 billion parameters) with strong performance on code-related benchmarks like HumanEval and HumanEval+. They also showed that XFT can consistently improve the performance of supervised fine-tuning on other code-related datasets, such as MBPP+, MultiPL-E, and DS-1000.
Critical Analysis
The researchers note that XFT is fully orthogonal to existing techniques like Evol-Instruct and OSS-Instruct, meaning it can be combined with these approaches to further improve instruction-tuned code LLMs.
However, the paper does not provide a detailed analysis of the computational cost and training time required for the XFT approach, which could be an important consideration for real-world deployment. Additionally, the researchers only tested XFT on a relatively small model (1.3 billion parameters), and it's unclear how well the approach would scale to larger, more powerful LLMs.
Further research could also explore the generalizability of XFT beyond code-related tasks, as well as investigate potential biases or limitations introduced by the shared expert mechanism and routing weight normalization strategy.
Conclusion
XFT introduces a novel training scheme that combines upcycling and Mixture-of-Experts models to significantly improve the performance of instruction-tuned code LLMs. By introducing a shared expert mechanism and a learnable model merging process, XFT is able to create a new state-of-the-art "tiny" code LLM and consistently boost the performance of existing models on a variety of code-related benchmarks.
This work opens up new possibilities for enhancing the capabilities of large language models in specialized domains, and the researchers suggest that XFT can be combined with other techniques to further advance the field of instruction-tuned LLMs. While the paper raises some questions about the practical considerations of the approach, the core ideas behind XFT demonstrate the potential for innovative training schemes to unlock the full potential of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
XFT: Unlocking the Power of Code Instruction Tuning by Simply Merging Upcycled Mixture-of-Experts
Yifeng Ding, Jiawei Liu, Yuxiang Wei, Terry Yue Zhuo, Lingming Zhang
We introduce XFT, a simple yet powerful training scheme, by simply merging upcycled Mixture-of-Experts (MoE) to unleash the performance limit of instruction-tuned code Large Language Models (LLMs). While vanilla sparse upcycling fails to improve instruction tuning, XFT introduces a shared expert mechanism with a novel routing weight normalization strategy into sparse upcycling, which significantly boosts instruction tuning. After fine-tuning the upcycled MoE model, XFT introduces a learnable model merging mechanism to compile the upcycled MoE model back to a dense model, achieving upcycled MoE-level performance with only dense-model compute. By applying XFT to a 1.3B model, we create a new state-of-the-art tiny code LLM (<3B) with 67.1 and 64.6 pass@1 on HumanEval and HumanEval+ respectively. With the same data and model architecture, XFT improves supervised fine-tuning (SFT) by 13% on HumanEval+, along with consistent improvements from 2% to 13% on MBPP+, MultiPL-E, and DS-1000, demonstrating its generalizability. XFT is fully orthogonal to existing techniques such as Evol-Instruct and OSS-Instruct, opening a new dimension for improving code instruction tuning. Codes are available at https://github.com/ise-uiuc/xft.
Read more6/10/2024
0
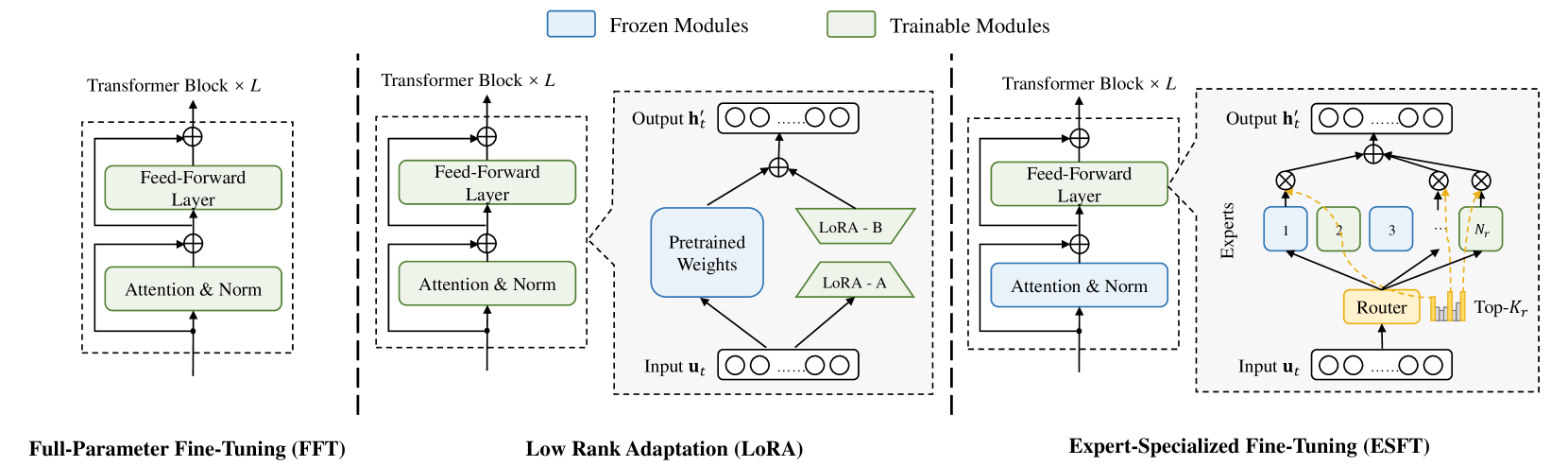
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, Y. Wu
Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness. Our code is available at https://github.com/deepseek-ai/ESFT.
Read more7/8/2024
➖
0
Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
Tingchen Fu, Deng Cai, Lemao Liu, Shuming Shi, Rui Yan
Supervised fine-tuning (SFT) on instruction-following corpus is a crucial approach toward the alignment of large language models (LLMs). However, the performance of LLMs on standard knowledge and reasoning benchmarks tends to suffer from deterioration at the latter stage of the SFT process, echoing the phenomenon of alignment tax. Through our pilot study, we put a hypothesis that the data biases are probably one cause behind the phenomenon. To address the issue, we introduce a simple disperse-then-merge framework. To be concrete, we disperse the instruction-following data into portions and train multiple sub-models using different data portions. Then we merge multiple models into a single one via model merging techniques. Despite its simplicity, our framework outperforms various sophisticated methods such as data curation and training regularization on a series of standard knowledge and reasoning benchmarks.
Read more5/24/2024
0
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
Jitai Hao, WeiWei Sun, Xin Xin, Qi Meng, Zhumin Chen, Pengjie Ren, Zhaochun Ren
Parameter-Efficient Fine-tuning (PEFT) facilitates the fine-tuning of Large Language Models (LLMs) under limited resources. However, the fine-tuning performance with PEFT on complex, knowledge-intensive tasks is limited due to the constrained model capacity, which originates from the limited number of additional trainable parameters. To overcome this limitation, we introduce a novel mechanism that fine-tunes LLMs with adapters of larger size yet memory-efficient. This is achieved by leveraging the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and utilizing the larger capacity of Central Processing Unit (CPU) memory compared to Graphics Processing Unit (GPU). We store and update the parameters of larger adapters on the CPU. Moreover, we employ a Mixture of Experts (MoE)-like architecture to mitigate unnecessary CPU computations and reduce the communication volume between the GPU and CPU. This is particularly beneficial over the limited bandwidth of PCI Express (PCIe). Our method can achieve fine-tuning results comparable to those obtained with larger memory capacities, even when operating under more limited resources such as a 24GB memory single GPU setup, with acceptable loss in training efficiency. Our codes are available at https://github.com/CURRENTF/MEFT.
Read more6/10/2024