Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models

0

Sign in to get full access
Overview
- This paper investigates how the syntax and supplementary information in prompts impact the knowledge retrieval performance of pretrained language models.
- The researchers conducted experiments to understand how prompt design affects the ability of language models to draw upon their learned knowledge to provide accurate and informative responses.
- The findings offer insights into effective prompt engineering to enhance the usefulness of language models for various applications.
Plain English Explanation
Language models are AI systems trained on vast amounts of text data to understand and generate human-like language. These models have shown impressive capabilities, but their performance can be heavily influenced by how they are prompted or instructed to complete a task.
In this study, the researchers examined how changes to the syntax and supplementary information in the prompts provided to language models affect their ability to retrieve and apply relevant knowledge. For example, a prompt that asks "What is the capital of France?" may yield a different response than one that says "Provide the capital city of France."
The researchers found that small variations in prompt wording and structure can have a significant impact on the accuracy and informativeness of the language model's outputs. Certain prompt formulations were more effective at eliciting comprehensive and relevant knowledge from the model.
By understanding these prompt effects, the researchers aim to help developers design more effective prompts to enhance the usefulness of language models for tasks like question answering, summarization, and knowledge retrieval. This could lead to language models that provide more reliable and informative responses to users.
Technical Explanation
The researchers conducted a series of experiments to systematically investigate the impact of prompt syntax and supplementary information on the performance of large language models. They used the GPT-3 model and prompted it with various question-answering tasks, manipulating factors like the presence of auxiliary verbs, the order of key elements, and the inclusion of additional context.
The results showed that prompt variations could significantly affect the accuracy, conciseness, and informativeness of the model's responses. For example, prompts that used a more direct syntax ("What is the capital of France?") tended to elicit more accurate but less elaborative responses compared to prompts with more context ("Provide the capital city of France and some key facts about it.").
Through detailed analyses, the researchers identified linguistic and structural features of prompts that were most predictive of effective knowledge retrieval. They found that prompts with a clear, explicit structure and supplementary information were generally more successful in drawing out the model's relevant factual knowledge.
These findings offer guidance for prompt engineering to optimize the usefulness of language models in applications that require reliable information retrieval, such as educational tools, question-answering systems, and knowledge-intensive tasks. The insights can also inform the development of more robust and transparent language models.
Critical Analysis
The researchers acknowledge several limitations of their study, including the use of a single language model (GPT-3) and the focus on relatively simple factual knowledge retrieval tasks. They suggest that future work should explore a wider range of models, tasks, and types of knowledge to further validate and expand the understanding of prompt effects.
Additionally, while the study demonstrates the significant impact of prompt design, it does not provide a comprehensive taxonomy or guidelines for creating optimal prompts. More research is needed to establish best practices and to understand the underlying cognitive and linguistic mechanisms driving the observed prompt effects.
Some potential concerns that could be explored in future work include the model's susceptibility to biases or misinformation present in the training data, the generalizability of the findings to more open-ended or contextual tasks, and the ethical implications of prompt engineering for language models deployed in high-stakes applications.
Overall, this study offers valuable insights into the nuances of prompt engineering and highlights the importance of careful design considerations when leveraging language models for practical applications. Continued research in this area can contribute to the development of more reliable and transparent AI systems.
Conclusion
This paper provides compelling evidence that the syntax and supplementary information in prompts can substantially influence the knowledge retrieval performance of large language models. The findings suggest that prompt engineering is a crucial factor in optimizing the usefulness of these models for a variety of tasks, from question answering to knowledge-intensive applications.
By understanding the impact of prompt design, researchers and developers can work towards creating more effective and trustworthy language models that can reliably draw upon their learned knowledge to provide informative and accurate responses. This, in turn, can enhance the practical applications of these powerful AI systems and contribute to their responsible and beneficial deployment in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Stephan Linzbach, Dimitar Dimitrov, Laura Kallmeyer, Kilian Evang, Hajira Jabeen, Stefan Dietze
Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
Read more4/3/2024
0
Paraphrase Types Elicit Prompt Engineering Capabilities
Jan Philip Wahle, Terry Ruas, Yang Xu, Bela Gipp
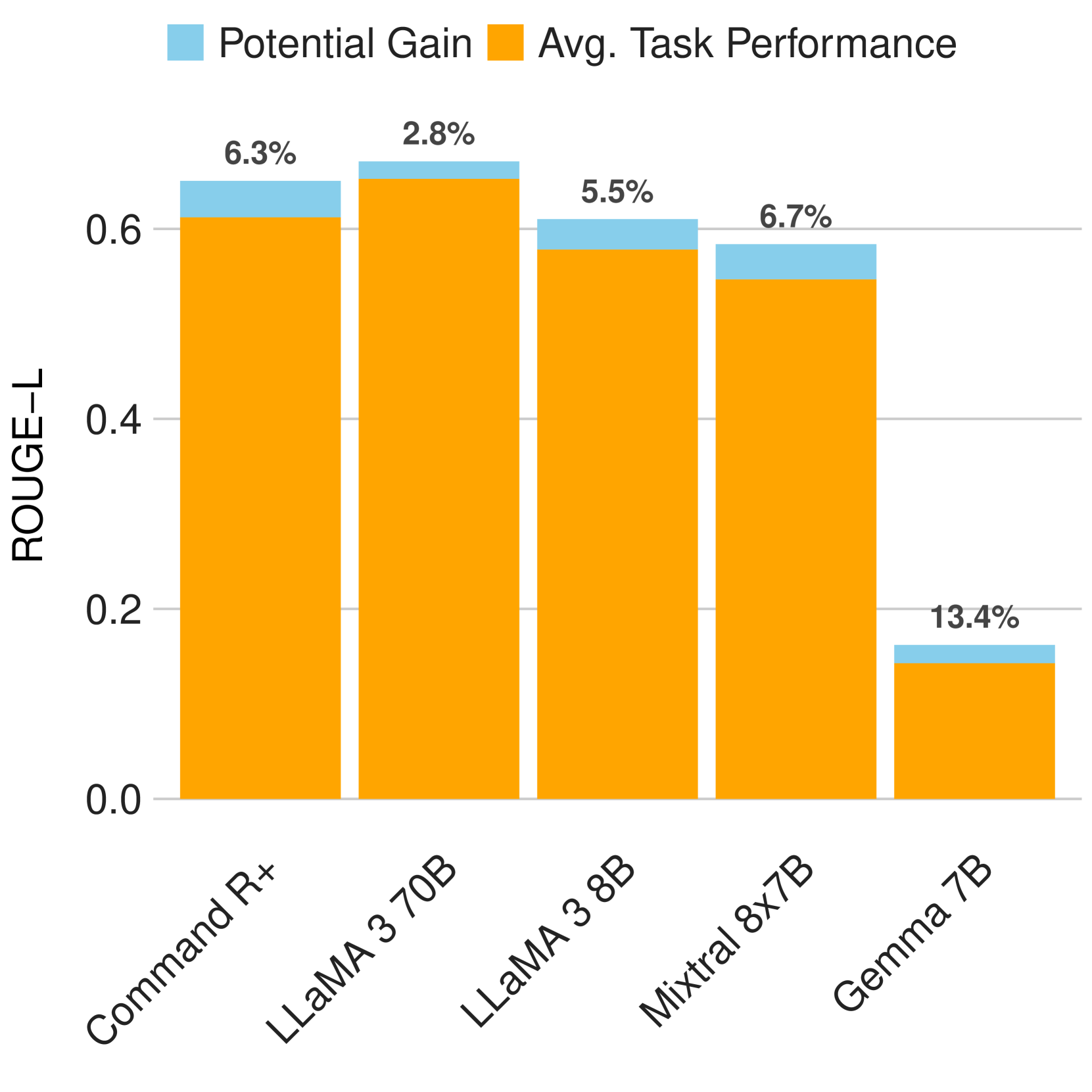
Much of the success of modern language models depends on finding a suitable prompt to instruct the model. Until now, it has been largely unknown how variations in the linguistic expression of prompts affect these models. This study systematically and empirically evaluates which linguistic features influence models through paraphrase types, i.e., different linguistic changes at particular positions. We measure behavioral changes for five models across 120 tasks and six families of paraphrases (i.e., morphology, syntax, lexicon, lexico-syntax, discourse, and others). We also control for other prompt engineering factors (e.g., prompt length, lexical diversity, and proximity to training data). Our results show a potential for language models to improve tasks when their prompts are adapted in specific paraphrase types (e.g., 6.7% median gain in Mixtral 8x7B; 5.5% in LLaMA 3 8B). In particular, changes in morphology and lexicon, i.e., the vocabulary used, showed promise in improving prompts. These findings contribute to developing more robust language models capable of handling variability in linguistic expression.
Read more9/30/2024

0
A Preliminary Empirical Study on Prompt-based Unsupervised Keyphrase Extraction
Mingyang Song, Yi Feng, Liping Jing
Pre-trained large language models can perform natural language processing downstream tasks by conditioning on human-designed prompts. However, a prompt-based approach often requires prompt engineering to design different prompts, primarily hand-crafted through laborious trial and error, requiring human intervention and expertise. It is a challenging problem when constructing a prompt-based keyphrase extraction method. Therefore, we investigate and study the effectiveness of different prompts on the keyphrase extraction task to verify the impact of the cherry-picked prompts on the performance of extracting keyphrases. Extensive experimental results on six benchmark keyphrase extraction datasets and different pre-trained large language models demonstrate that (1) designing complex prompts may not necessarily be more effective than designing simple prompts; (2) individual keyword changes in the designed prompts can affect the overall performance; (3) designing complex prompts achieve better performance than designing simple prompts when facing long documents.
Read more5/28/2024
💬
0
Demystifying Prompts in Language Models via Perplexity Estimation
Hila Gonen, Srini Iyer, Terra Blevins, Noah A. Smith, Luke Zettlemoyer
Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
Read more9/16/2024