Paraphrase Types Elicit Prompt Engineering Capabilities

0
Sign in to get full access
Overview
- This research paper explores how different types of paraphrases can be used to test and improve prompt engineering capabilities for large language models.
- The authors investigate how variations in prompt syntax and supplementary information affect model performance on a diverse set of paraphrasing tasks.
- The findings provide insights into prompt engineering best practices and the importance of considering different paraphrase types when evaluating and developing language models.
Plain English Explanation
The paper focuses on how to effectively prompt or instruct large language models, like GPT-3, to perform well on paraphrasing tasks. Paraphrasing is the process of rephrasing the same information in different words, while preserving the original meaning.
The researchers tested various ways of formulating prompts, such as changing the syntax or adding extra context. They found that the specific type of paraphrase being generated had a big impact on what kind of prompt worked best. For example, prompts that provided more information were helpful for producing formal academic paraphrases, but less useful for generating informal conversational rewrites.
These insights are important for prompt engineering - the art of crafting effective prompts to get language models to perform desired tasks. By understanding how prompt variations interact with different paraphrase types, researchers and developers can improve prompt engineering practices and build more capable and reliable language AI systems.
Technical Explanation
The paper examines how variations in prompt syntax and supplementary information impact the performance of large language models on a diverse set of paraphrasing tasks. The authors curated a dataset of over 20,000 paraphrases spanning four distinct types: formal, informal, lexical, and structural.
They then evaluated several prompt engineering techniques across this dataset using the GPT-3 language model. Key findings include:
- Prompts providing more contextual information improved performance on formal and academic-style paraphrases, but hurt performance on more conversational rewrites.
- Varying the prompt syntax, such as phrasing it as a question vs. a statement, had significant impacts on model outputs depending on paraphrase type.
- Certain paraphrase types, like lexical substitutions, were more robust to prompt variations than others, like structural rewrites.
These results demonstrate the importance of considering diverse paraphrase types when developing prompt engineering strategies for language models. The insights can inform best practices for evaluating and improving the capabilities of large language AI systems.
Critical Analysis
The paper provides a thorough and systematic analysis of how prompt engineering impacts language model performance on paraphrasing tasks. However, the dataset used is limited to English text, so the generalizability to other languages is unclear.
Additionally, the study only evaluates the GPT-3 model, so it's uncertain whether the findings would extend to other large language models. Further research is needed to assess prompt engineering across a wider range of models and datasets.
The authors also acknowledge that their paraphrase categories are somewhat subjective and may overlap. Developing more robust and standardized taxonomies for paraphrase types could strengthen future studies in this area.
Overall, this work represents an important step towards understanding the nuances of prompt engineering and its interactions with diverse language generation tasks. Continued research in this direction has the potential to significantly advance the capabilities and reliability of large language AI systems.
Conclusion
This paper demonstrates that the specific type of paraphrase being generated has a major impact on what kinds of prompts work best for eliciting high-quality outputs from large language models.
By exploring how prompt variations interact with diverse paraphrase styles, the authors provide valuable insights to guide the development of effective prompt engineering practices. These findings can help researchers and practitioners build more capable and robust language AI systems that can reliably perform a wide range of text generation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Paraphrase Types Elicit Prompt Engineering Capabilities
Jan Philip Wahle, Terry Ruas, Yang Xu, Bela Gipp
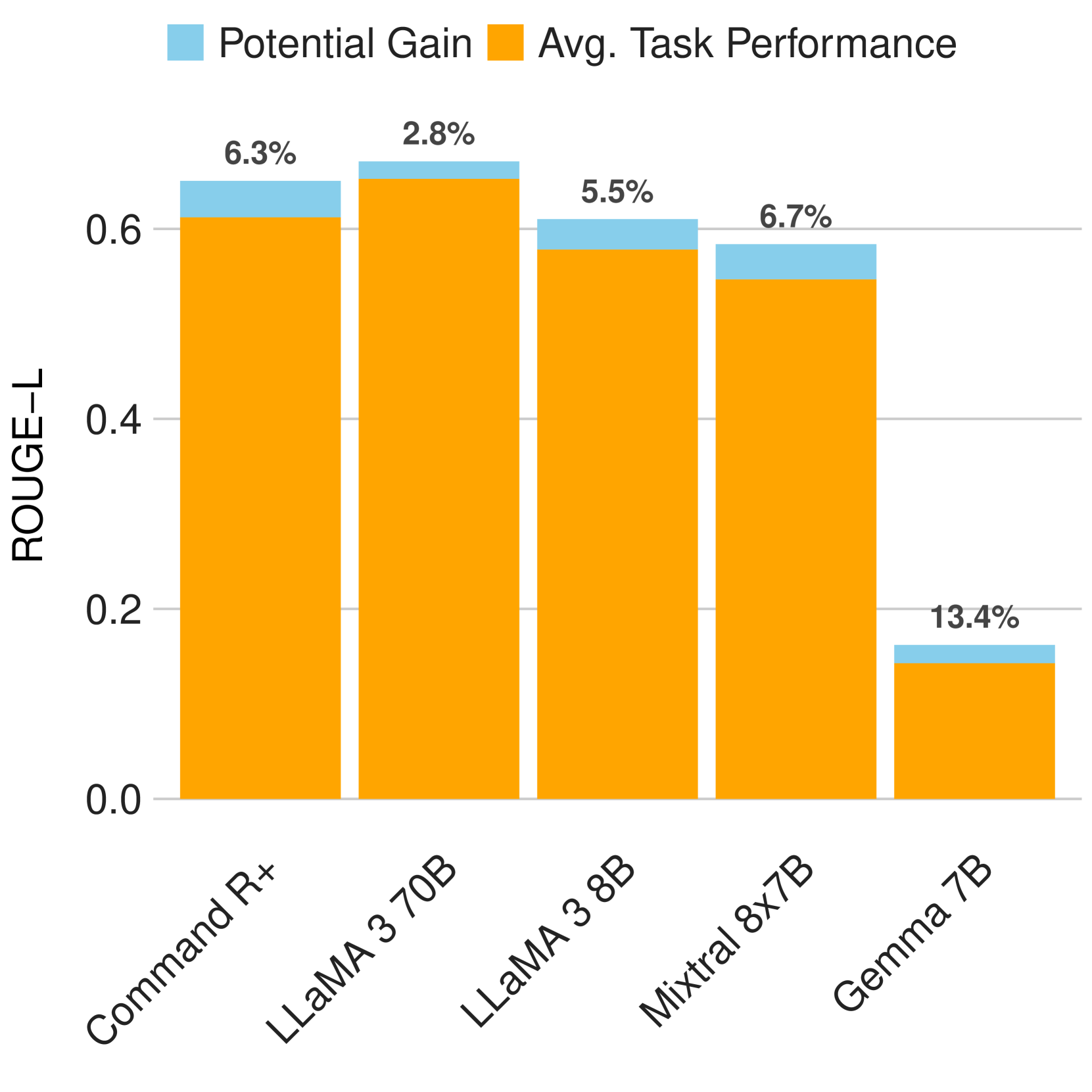
Much of the success of modern language models depends on finding a suitable prompt to instruct the model. Until now, it has been largely unknown how variations in the linguistic expression of prompts affect these models. This study systematically and empirically evaluates which linguistic features influence models through paraphrase types, i.e., different linguistic changes at particular positions. We measure behavioral changes for five models across 120 tasks and six families of paraphrases (i.e., morphology, syntax, lexicon, lexico-syntax, discourse, and others). We also control for other prompt engineering factors (e.g., prompt length, lexical diversity, and proximity to training data). Our results show a potential for language models to improve tasks when their prompts are adapted in specific paraphrase types (e.g., 6.7% median gain in Mixtral 8x7B; 5.5% in LLaMA 3 8B). In particular, changes in morphology and lexicon, i.e., the vocabulary used, showed promise in improving prompts. These findings contribute to developing more robust language models capable of handling variability in linguistic expression.
Read more7/1/2024

0
Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Stephan Linzbach, Dimitar Dimitrov, Laura Kallmeyer, Kilian Evang, Hajira Jabeen, Stefan Dietze
Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
Read more4/3/2024
💬
0
A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
Shubham Vatsal, Harsh Dubey
Large language models (LLMs) have shown remarkable performance on many different Natural Language Processing (NLP) tasks. Prompt engineering plays a key role in adding more to the already existing abilities of LLMs to achieve significant performance gains on various NLP tasks. Prompt engineering requires composing natural language instructions called prompts to elicit knowledge from LLMs in a structured way. Unlike previous state-of-the-art (SoTA) models, prompt engineering does not require extensive parameter re-training or fine-tuning based on the given NLP task and thus solely operates on the embedded knowledge of LLMs. Additionally, LLM enthusiasts can intelligently extract LLMs' knowledge through a basic natural language conversational exchange or prompt engineering, allowing more and more people even without deep mathematical machine learning background to experiment with LLMs. With prompt engineering gaining popularity in the last two years, researchers have come up with numerous engineering techniques around designing prompts to improve accuracy of information extraction from the LLMs. In this paper, we summarize different prompting techniques and club them together based on different NLP tasks that they have been used for. We further granularly highlight the performance of these prompting strategies on various datasets belonging to that NLP task, talk about the corresponding LLMs used, present a taxonomy diagram and discuss the possible SoTA for specific datasets. In total, we read and present a survey of 44 research papers which talk about 39 different prompting methods on 29 different NLP tasks of which most of them have been published in the last two years.
Read more7/25/2024
🛸
0
Paraphrase Types for Generation and Detection
Jan Philip Wahle, Bela Gipp, Terry Ruas
Current approaches in paraphrase generation and detection heavily rely on a single general similarity score, ignoring the intricate linguistic properties of language. This paper introduces two new tasks to address this shortcoming by considering paraphrase types - specific linguistic perturbations at particular text positions. We name these tasks Paraphrase Type Generation and Paraphrase Type Detection. Our results suggest that while current techniques perform well in a binary classification scenario, i.e., paraphrased or not, the inclusion of fine-grained paraphrase types poses a significant challenge. While most approaches are good at generating and detecting general semantic similar content, they fail to understand the intrinsic linguistic variables they manipulate. Models trained in generating and identifying paraphrase types also show improvements in tasks without them. In addition, scaling these models further improves their ability to understand paraphrase types. We believe paraphrase types can unlock a new paradigm for developing paraphrase models and solving tasks in the future.
Read more7/17/2024