Entity Alignment with Noisy Annotations from Large Language Models
2405.16806
0
0

Abstract
Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. While existing methods heavily rely on human-generated labels, it is prohibitively expensive to incorporate cross-domain experts for annotation in real-world scenarios. The advent of Large Language Models (LLMs) presents new avenues for automating EA with annotations, inspired by their comprehensive capability to process semantic information. However, it is nontrivial to directly apply LLMs for EA since the annotation space in real-world KGs is large. LLMs could also generate noisy labels that may mislead the alignment. To this end, we propose a unified framework, LLM4EA, to effectively leverage LLMs for EA. Specifically, we design a novel active learning policy to significantly reduce the annotation space by prioritizing the most valuable entities based on the entire inter-KG and intra-KG structure. Moreover, we introduce an unsupervised label refiner to continuously enhance label accuracy through in-depth probabilistic reasoning. We iteratively optimize the policy based on the feedback from a base EA model. Extensive experiments demonstrate the advantages of LLM4EA on four benchmark datasets in terms of effectiveness, robustness, and efficiency. Codes are available via https://github.com/chensyCN/llm4ea_official.
Create account to get full access
Overview
- This paper presents a novel approach for aligning entities across knowledge bases using noisy annotations from large language models (LLMs).
- The method leverages the rich semantic knowledge captured by pre-trained LLMs to enhance the entity alignment task, which is typically challenging due to the lack of high-quality training data.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showcasing improved performance over existing methods.
Plain English Explanation
Knowledge bases are databases that store information about entities, such as people, places, and things. Towards Complex Ontology Alignment Using Large Language Models and Augmenting NER Datasets with LLMs Towards Automated Refined Annotation have explored using large language models to better extract and align information in these knowledge bases.
This paper builds on these ideas, focusing on the specific task of entity alignment. Entity alignment is the process of matching up the same entities that appear in different knowledge bases. This is important for integrating data from multiple sources and getting a more complete picture.
The key innovation in this paper is using the rich semantic knowledge captured by large language models to help with the entity alignment task. Large language models are AI systems that have been trained on massive amounts of text data, allowing them to understand the meaning and relationships between words and concepts very well.
The authors show that by leveraging this semantic knowledge, their approach can achieve better entity alignment results compared to existing methods, even when the training data is noisy or limited. This is particularly useful in real-world scenarios where high-quality training data for entity alignment can be hard to come by.
Technical Explanation
The paper proposes a novel framework for Entity Alignment with Noisy Annotations from Large Language Models (ENALN). The core idea is to use the semantic representations learned by pre-trained LLMs to enhance the entity alignment task.
The ENALN framework consists of three main components:
-
Noisy Annotation Generation: The authors leverage LLMs to automatically generate noisy annotations for entity pairs, which serve as weak supervision signals for the alignment task. This helps address the challenge of scarce high-quality training data.
-
Semantic-aware Entity Alignment: The framework uses the semantic representations from the LLMs to capture the rich semantic information about entities, which is then used to improve the alignment process. This is done through a neural network architecture that jointly learns entity representations and alignment scores.
-
Noise-robust Training: To handle the inherent noise in the automatically generated annotations, the authors employ a noise-robust training strategy that can effectively learn from the noisy data.
The authors evaluate their ENALN framework on several benchmark datasets for entity alignment, including LAB: Large-scale Alignment of Chatbots and Distantly Supervised Joint Extraction with Noise-Robust Learning. The results demonstrate that ENALN outperforms existing state-of-the-art methods, particularly in scenarios with limited or noisy training data.
Critical Analysis
The paper presents a compelling approach to leveraging the power of large language models for the challenging task of entity alignment. The key strengths of the ENALN framework include:
-
Addressing the data scarcity problem: The ability to generate noisy annotations using LLMs is a valuable contribution, as it helps overcome the lack of high-quality training data, which is a common issue in real-world entity alignment scenarios.
-
Effective use of semantic knowledge: The integration of the semantic representations from LLMs into the alignment process is a novel and well-designed aspect of the framework, allowing it to capture richer information about the entities.
-
Noise-robust training: The authors' approach to handling the inherent noise in the automatically generated annotations is an important consideration and a strength of the overall framework.
However, the paper also raises a few points worthy of further discussion:
-
Generalizability: While the results on the benchmark datasets are promising, it would be valuable to see how the ENALN framework performs on a wider range of knowledge bases and entity types, including those with different characteristics and levels of complexity.
-
Interpretability: The use of neural networks in the framework may raise questions about the interpretability of the model's decision-making process. Providing more insights into how the semantic knowledge is being leveraged, and the specific factors contributing to the alignment decisions, could strengthen the overall contribution.
-
Computational efficiency: The reliance on pre-trained LLMs may have implications for the computational cost and inference time of the ENALN framework. Addressing these aspects, or providing guidance on how to balance performance and efficiency, could enhance the practical applicability of the approach.
EAMA: Entity-Aware Multimodal Alignment-Based Approach is another relevant paper that explores the integration of multimodal information for entity alignment, which could provide additional insights and opportunities for further research.
Conclusion
This paper presents a novel framework, ENALN, that leverages the semantic knowledge captured by large language models to enhance the entity alignment task. By generating noisy annotations and employing a noise-robust training strategy, the authors demonstrate improved performance over existing methods, particularly in scenarios with limited or imperfect training data.
The work showcases the potential of harnessing the rich contextual understanding of LLMs to tackle complex knowledge integration challenges. As knowledge bases continue to grow in size and complexity, the ENALN approach may offer a valuable contribution towards building more robust and comprehensive data ecosystems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Leveraging Large Language Models for Entity Matching
Qianyu Huang, Tongfang Zhao
0
0
Entity matching (EM) is a critical task in data integration, aiming to identify records across different datasets that refer to the same real-world entities. Traditional methods often rely on manually engineered features and rule-based systems, which struggle with diverse and unstructured data. The emergence of Large Language Models (LLMs) such as GPT-4 offers transformative potential for EM, leveraging their advanced semantic understanding and contextual capabilities. This vision paper explores the application of LLMs to EM, discussing their advantages, challenges, and future research directions. Additionally, we review related work on applying weak supervision and unsupervised approaches to EM, highlighting how LLMs can enhance these methods.
6/3/2024
Towards Complex Ontology Alignment using Large Language Models
Reihaneh Amini, Sanaz Saki Norouzi, Pascal Hitzler, Reza Amini
0
0
Ontology alignment, a critical process in the Semantic Web for detecting relationships between different ontologies, has traditionally focused on identifying so-called simple 1-to-1 relationships through class labels and properties comparison. The more practically useful exploration of more complex alignments remains a hard problem to automate, and as such is largely underexplored, i.e. in application practice it is usually done manually by ontology and domain experts. Recently, the surge in Natural Language Processing (NLP) capabilities, driven by advancements in Large Language Models (LLMs), presents new opportunities for enhancing ontology engineering practices, including ontology alignment tasks. This paper investigates the application of LLM technologies to tackle the complex ontology alignment challenge. Leveraging a prompt-based approach and integrating rich ontology content so-called modules our work constitutes a significant advance towards automating the complex alignment task.
4/17/2024
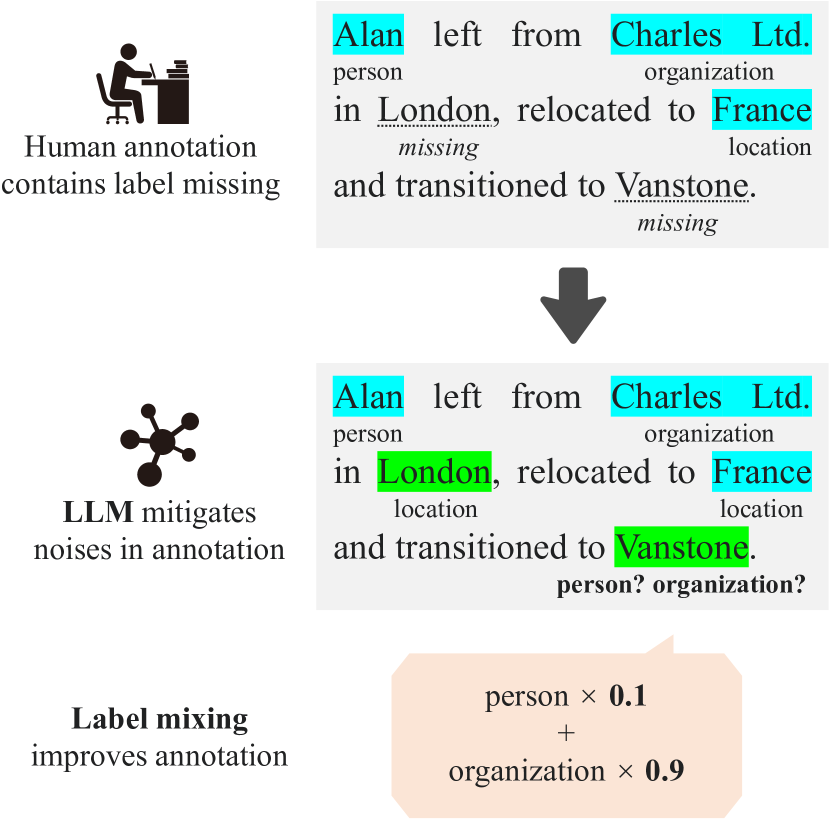
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024