Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning

0
➖
Sign in to get full access
Overview
- Thompson sampling (TS) is a robust technique for contextual bandit problems, but requires complex posterior inference and optimization, making it difficult to deploy in real-world systems.
- The researchers propose a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation, enabling fast decision-making and easy deployment.
- The algorithm learns a new explicit policy by iteratively updating and imitating the TS policy using batched data.
- The imitation policy achieves comparable performance to batch TS while reducing decision-time latency by over an order of magnitude.
- The algorithm has been successfully deployed in multiple video upload systems at Meta, resulting in significant improvements in video quality and watch time.
Plain English Explanation
The paper describes a new way to use Thompson sampling, a powerful technique for making decisions in contextual bandit problems. Thompson sampling is good at finding the best actions to take, but it requires complex mathematical calculations that can slow down decision-making.
To make Thompson sampling easier to use, the researchers developed a new algorithm that takes the complicated Thompson sampling policy and distills it into a simpler, explicit policy. This explicit policy can make decisions much faster, without needing to do all the complex math. The algorithm does this by repeatedly learning from batches of data collected under the imitation policy, gradually improving the imitation to better match the original Thompson sampling policy.
The result is a decision-making system that performs about as well as the original Thompson sampling, but runs over 10 times faster. This allows the algorithm to be easily deployed in real-world systems like video upload platforms, where fast response times are crucial.
The researchers tested their algorithm at Meta (the company that owns Facebook) and found that it significantly improved video quality and watch time, showing that it can have a real-world impact. The combination of strong performance and fast, simple deployment makes this a promising approach for applying advanced decision-making techniques in practical applications.
Technical Explanation
The key technical innovation in this paper is the development of an imitation learning-based algorithm that distills a Thompson sampling (TS) policy into an explicit policy representation. This allows for fast decision-making and easy deployment in real-world systems.
The core of the approach is an iterative process of collecting batched data under the imitation policy, and then using that data to update the TS policy and learn a new imitation policy that better matches it. This cycle continues, with the imitation policy gradually improving to closely mimic the TS policy.
Empirically, the researchers show that the final imitation policy achieves performance comparable to batch TS, while providing over an order of magnitude reduction in decision-time latency. This enables the algorithm to be successfully deployed in video upload systems at Meta, where low latency and ease of implementation are critical.
Through a randomized controlled trial, the researchers demonstrate that the deployed system resulted in significant improvements in video quality and watch time, highlighting the real-world impact of their approach.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. First, the imitation learning approach relies on being able to collect high-quality batched data under the imitation policy, which may be challenging in some real-world settings. Additionally, the iterative updates to the TS policy and imitation policy could potentially lead to instability or divergence, which the paper does not fully explore.
Another potential issue is that the researchers do not provide a theoretical analysis of the convergence or regret bounds of their algorithm, instead relying on empirical performance. Providing such theoretical guarantees could strengthen the foundations of the approach.
Furthermore, the paper focuses on the deployment in video upload systems at Meta, but it is unclear how well the algorithm would generalize to other types of contextual bandit problems or deployment environments. Evaluating the algorithm's performance in a wider range of scenarios could help assess its broader applicability.
Despite these limitations, the paper presents a novel and practical solution to the challenge of deploying Thompson sampling in real-world systems. The significant performance improvements and successful deployment at Meta suggest that this approach could have a meaningful impact in the field of contextual bandits and decision-making under uncertainty.
Conclusion
This paper introduces an imitation-learning-based algorithm that distills a Thompson sampling policy into an explicit policy representation, enabling fast decision-making and easy deployment in real-world systems. By iteratively updating the TS policy and learning a new imitation policy, the researchers achieve comparable performance to batch TS while dramatically reducing decision-time latency.
The successful deployment of this algorithm in multiple video upload systems at Meta, resulting in improved video quality and watch time, demonstrates the practical significance of this work. While the paper acknowledges some limitations, it provides a promising approach for applying advanced decision-making techniques, like Thompson sampling, in latency-sensitive and easily-deployable applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Hongseok Namkoong, Samuel Daulton, Eytan Bakshy
Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many online platforms where latency and ease of deployment are of concern. We operationalize TS by proposing a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation, allowing fast decision-making and easy deployment in mobile and server-based environments. Using batched data collected under the imitation policy, our algorithm iteratively performs offline updates to the TS policy, and learns a new explicit policy representation to imitate it. Empirically, our imitation policy achieves performance comparable to batch TS while allowing more than an order of magnitude reduction in decision-time latency. Buoyed by low latency and simplicity of implementation, our algorithm has been successfully deployed in multiple video upload systems for Meta. Using a randomized controlled trial, we show our algorithm resulted in significant improvements in video quality and watch time.
Read more7/23/2024
🤯
0
VITS : Variational Inference Thomson Sampling for contextual bandits
Pierre Clavier, Tom Huix, Alain Durmus
In this paper, we introduce and analyze a variant of the Thompson sampling (TS) algorithm for contextual bandits. At each round, traditional TS requires samples from the current posterior distribution, which is usually intractable. To circumvent this issue, approximate inference techniques can be used and provide samples with distribution close to the posteriors. However, current approximate techniques yield to either poor estimation (Laplace approximation) or can be computationally expensive (MCMC methods, Ensemble sampling...). In this paper, we propose a new algorithm, Varational Inference Thompson sampling VITS, based on Gaussian Variational Inference. This scheme provides powerful posterior approximations which are easy to sample from, and is computationally efficient, making it an ideal choice for TS. In addition, we show that VITS achieves a sub-linear regret bound of the same order in the dimension and number of round as traditional TS for linear contextual bandit. Finally, we demonstrate experimentally the effectiveness of VITS on both synthetic and real world datasets.
Read more7/23/2024
0
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
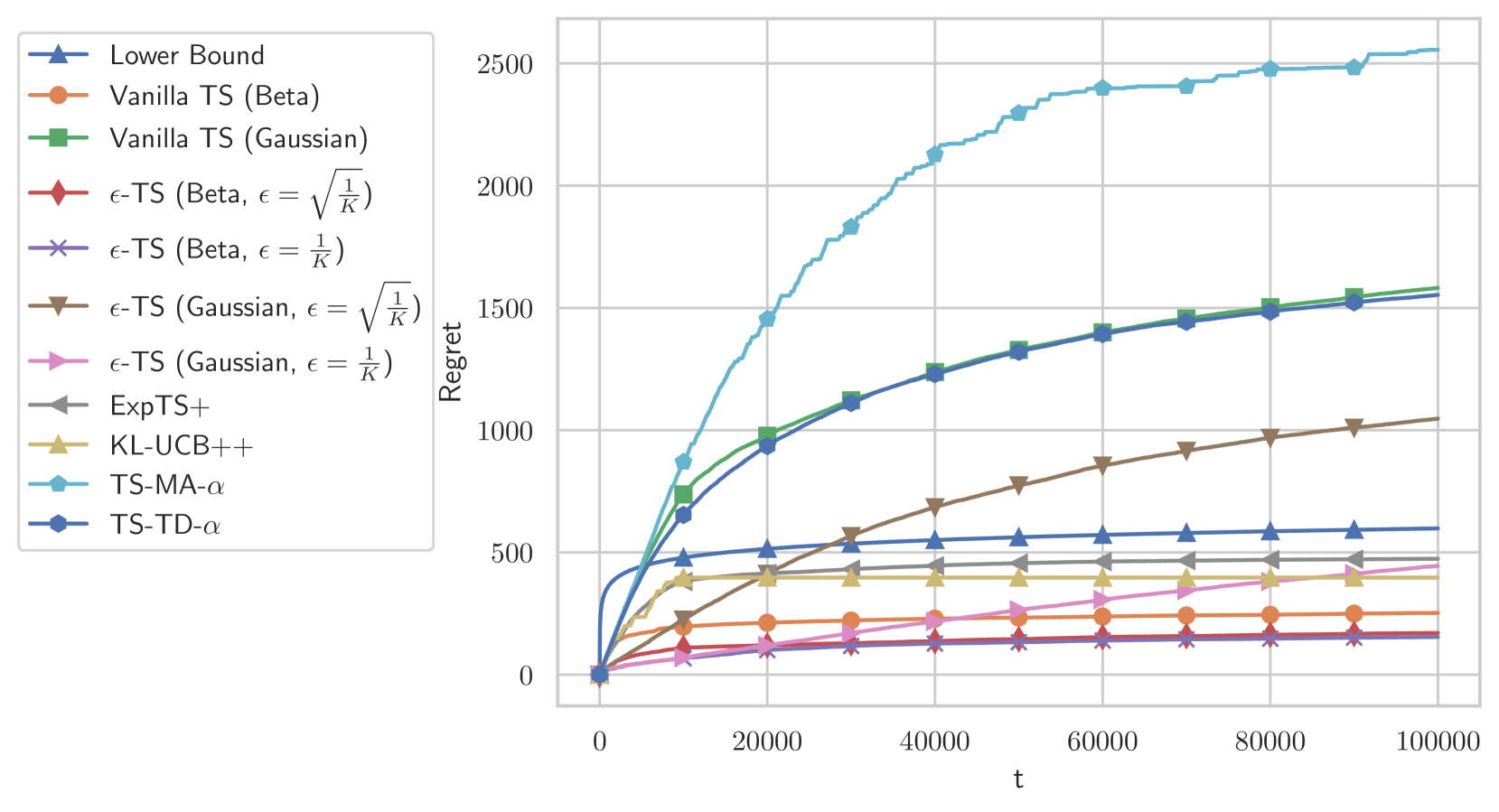
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Read more5/3/2024

0
More Efficient Randomized Exploration for Reinforcement Learning via Approximate Sampling
Haque Ishfaq, Yixin Tan, Yu Yang, Qingfeng Lan, Jianfeng Lu, A. Rupam Mahmood, Doina Precup, Pan Xu
Thompson sampling (TS) is one of the most popular exploration techniques in reinforcement learning (RL). However, most TS algorithms with theoretical guarantees are difficult to implement and not generalizable to Deep RL. While the emerging approximate sampling-based exploration schemes are promising, most existing algorithms are specific to linear Markov Decision Processes (MDP) with suboptimal regret bounds, or only use the most basic samplers such as Langevin Monte Carlo. In this work, we propose an algorithmic framework that incorporates different approximate sampling methods with the recently proposed Feel-Good Thompson Sampling (FGTS) approach (Zhang, 2022; Dann et al., 2021), which was previously known to be computationally intractable in general. When applied to linear MDPs, our regret analysis yields the best known dependency of regret on dimensionality, surpassing existing randomized algorithms. Additionally, we provide explicit sampling complexity for each employed sampler. Empirically, we show that in tasks where deep exploration is necessary, our proposed algorithms that combine FGTS and approximate sampling perform significantly better compared to other strong baselines. On several challenging games from the Atari 57 suite, our algorithms achieve performance that is either better than or on par with other strong baselines from the deep RL literature.
Read more6/19/2024