VITS : Variational Inference Thomson Sampling for contextual bandits

0
🤯
Sign in to get full access
Overview
- Introduces a new algorithm called Variational Inference Thompson Sampling (VITS) for contextual bandits
- VITS uses Gaussian Variational Inference to provide efficient posterior approximations for the Thompson Sampling algorithm
- Demonstrates VITS achieves sub-linear regret bounds comparable to traditional Thompson Sampling
- Empirically shows VITS outperforms other approximate inference methods on both synthetic and real-world datasets
Plain English Explanation
The paper discusses a new algorithm called Variational Inference Thompson Sampling (VITS) for solving contextual bandits problems. Contextual bandits are a type of machine learning problem where an agent needs to choose the best "arm" (action) to pull based on some context about the current situation.
The traditional Thompson Sampling (TS) algorithm is a popular approach for contextual bandits, but it requires sampling from the current posterior distribution, which can be computationally expensive. To address this, the paper proposes using Gaussian Variational Inference to efficiently approximate the posterior distribution. This allows for quick sampling and makes the VITS algorithm computationally efficient.
The key advantage of VITS is that it provides powerful posterior approximations that are easy to sample from, while still maintaining strong theoretical guarantees. Specifically, the paper shows VITS achieves a sub-linear regret bound – meaning its performance gets closer and closer to the optimal strategy as the number of rounds increases – at the same rate as traditional Thompson Sampling.
The paper also demonstrates experimentally that VITS outperforms other approximate inference methods, such as Laplace approximation or Markov Chain Monte Carlo, on both synthetic and real-world datasets. This suggests VITS is a practical and effective algorithm for tackling contextual bandit problems.
Technical Explanation
The paper introduces the Variational Inference Thompson Sampling (VITS) algorithm, which combines the Thompson Sampling approach for contextual bandits with Gaussian Variational Inference to efficiently approximate the required posterior distributions.
Traditional Thompson Sampling requires sampling from the current posterior distribution over the model parameters. However, computing this posterior is often intractable, so approximate inference techniques are needed. The paper argues that existing approximation methods, such as Laplace approximation or MCMC, either yield poor posterior estimates or are computationally expensive.
To address this, VITS uses Gaussian Variational Inference, which provides a flexible and efficient way to approximate the required posteriors. Variational inference transforms the posterior estimation problem into an optimization task, allowing for quick sampling from the resulting approximate distributions.
The paper analyzes the theoretical properties of VITS, proving that it achieves a sub-linear regret bound of the same order as traditional Thompson Sampling for linear contextual bandits. This means VITS's performance converges to the optimal strategy at the same rate as the original TS algorithm.
Experimentally, the authors compare VITS to other approximate TS methods on both synthetic and real-world datasets, including Laplace approximation and MCMC-based approaches. The results demonstrate the effectiveness of the VITS algorithm, showing it outperforms the alternatives in terms of cumulative regret.
Critical Analysis
The paper provides a compelling solution to the challenge of approximating posterior distributions for Thompson Sampling in contextual bandits. By leveraging Gaussian Variational Inference, VITS is able to maintain strong theoretical guarantees while being computationally efficient.
One potential limitation is that the theoretical analysis focuses on the linear contextual bandit setting. While the experiments show VITS also performs well in more general scenarios, it would be valuable to understand its theoretical properties in non-linear or more complex environments.
Additionally, the paper does not discuss how VITS might scale to very high-dimensional or large-scale problems. The computational efficiency of the variational inference approach is a strength, but further research may be needed to understand its performance on truly massive datasets or complex models.
It would also be interesting to see how VITS compares to other recent advancements in Thompson Sampling, such as feel-good Thompson Sampling for contextual dueling bandits or generalized best-of-both-worlds algorithms. Exploring the relative strengths and weaknesses of these different approaches could lead to further improvements in the field of contextual bandits.
Overall, the VITS algorithm presented in this paper is a valuable contribution, demonstrating how principled approximation techniques can be leveraged to make Thompson Sampling more practical and effective in real-world applications.
Conclusion
This paper introduces the Variational Inference Thompson Sampling (VITS) algorithm, which combines the power of Thompson Sampling for contextual bandits with the computational efficiency of Gaussian Variational Inference. By providing a flexible and robust way to approximate the required posterior distributions, VITS maintains strong theoretical guarantees while being faster and more practical than alternative approaches.
The key innovation of VITS is its use of variational inference to sidestep the intractable posterior computations in traditional Thompson Sampling. This allows for quick sampling from the approximate posteriors, making VITS a compelling choice for real-world contextual bandit problems. The paper's theoretical and empirical results indicate VITS is a valuable addition to the toolbox of machine learning researchers and practitioners working on sequential decision-making under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
VITS : Variational Inference Thomson Sampling for contextual bandits
Pierre Clavier, Tom Huix, Alain Durmus
In this paper, we introduce and analyze a variant of the Thompson sampling (TS) algorithm for contextual bandits. At each round, traditional TS requires samples from the current posterior distribution, which is usually intractable. To circumvent this issue, approximate inference techniques can be used and provide samples with distribution close to the posteriors. However, current approximate techniques yield to either poor estimation (Laplace approximation) or can be computationally expensive (MCMC methods, Ensemble sampling...). In this paper, we propose a new algorithm, Varational Inference Thompson sampling VITS, based on Gaussian Variational Inference. This scheme provides powerful posterior approximations which are easy to sample from, and is computationally efficient, making it an ideal choice for TS. In addition, we show that VITS achieves a sub-linear regret bound of the same order in the dimension and number of round as traditional TS for linear contextual bandit. Finally, we demonstrate experimentally the effectiveness of VITS on both synthetic and real world datasets.
Read more7/23/2024
➖
0
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Hongseok Namkoong, Samuel Daulton, Eytan Bakshy
Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many online platforms where latency and ease of deployment are of concern. We operationalize TS by proposing a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation, allowing fast decision-making and easy deployment in mobile and server-based environments. Using batched data collected under the imitation policy, our algorithm iteratively performs offline updates to the TS policy, and learns a new explicit policy representation to imitate it. Empirically, our imitation policy achieves performance comparable to batch TS while allowing more than an order of magnitude reduction in decision-time latency. Buoyed by low latency and simplicity of implementation, our algorithm has been successfully deployed in multiple video upload systems for Meta. Using a randomized controlled trial, we show our algorithm resulted in significant improvements in video quality and watch time.
Read more7/23/2024
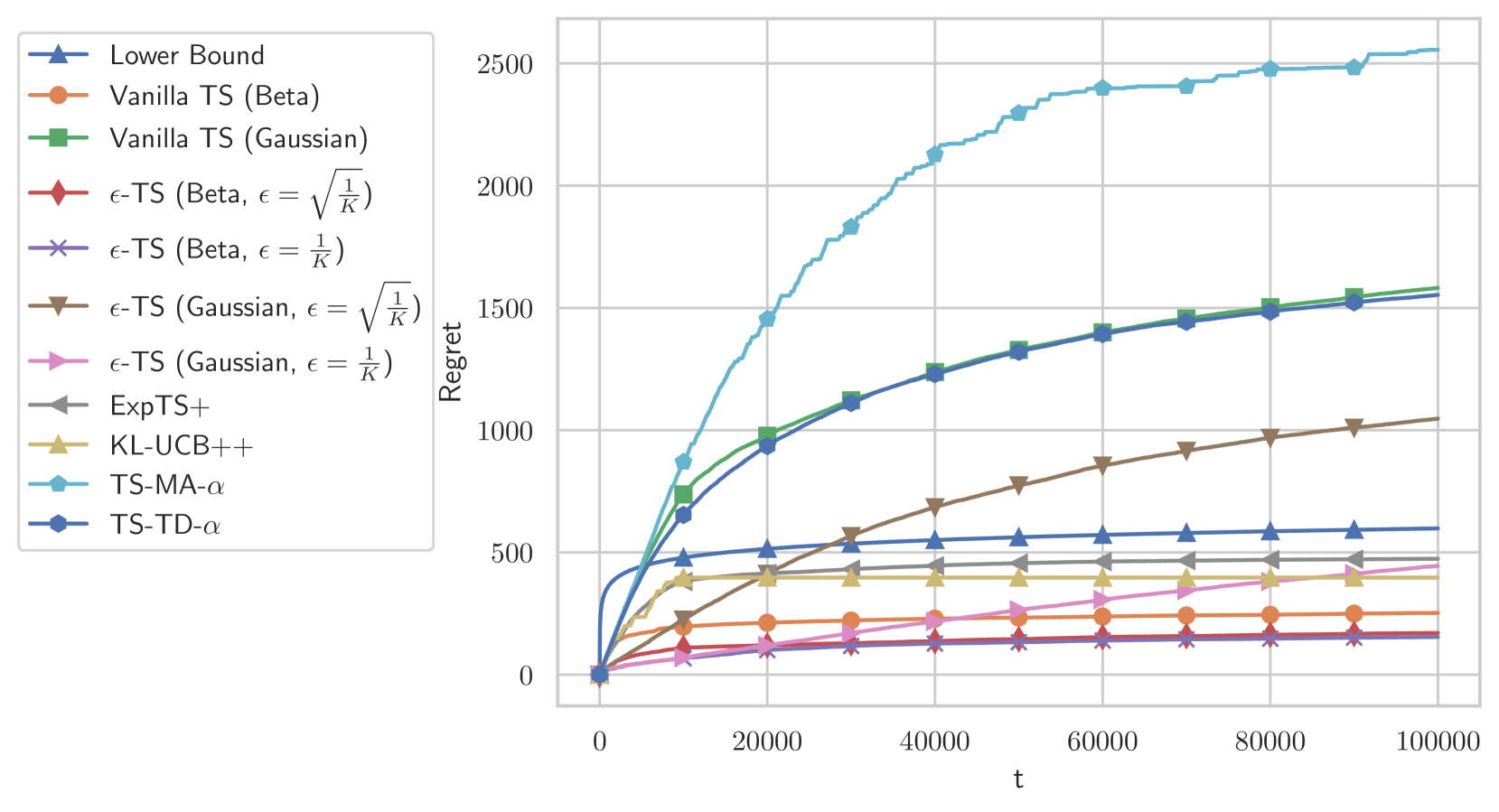
0
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Read more5/3/2024

0
Bayesian Bandit Algorithms with Approximate Inference in Stochastic Linear Bandits
Ziyi Huang, Henry Lam, Haofeng Zhang
Bayesian bandit algorithms with approximate Bayesian inference have been widely used in real-world applications. Nevertheless, their theoretical justification is less investigated in the literature, especially for contextual bandit problems. To fill this gap, we propose a general theoretical framework to analyze stochastic linear bandits in the presence of approximate inference and conduct regret analysis on two Bayesian bandit algorithms, Linear Thompson sampling (LinTS) and the extension of Bayesian Upper Confidence Bound, namely Linear Bayesian Upper Confidence Bound (LinBUCB). We demonstrate that both LinTS and LinBUCB can preserve their original rates of regret upper bound but with a sacrifice of larger constant terms when applied with approximate inference. These results hold for general Bayesian inference approaches, under the assumption that the inference error measured by two different $alpha$-divergences is bounded. Additionally, by introducing a new definition of well-behaved distributions, we show that LinBUCB improves the regret rate of LinTS from $tilde{O}(d^{3/2}sqrt{T})$ to $tilde{O}(dsqrt{T})$, matching the minimax optimal rate. To our knowledge, this work provides the first regret bounds in the setting of stochastic linear bandits with bounded approximate inference errors.
Read more6/21/2024