Distilling the Knowledge in Data Pruning

0
Sign in to get full access
Overview
- This paper explores a novel approach to data pruning, which involves selectively removing data samples to improve the performance of machine learning models.
- The key idea is to "distill" the knowledge from the original, full-size model into a smaller, pruned model by training the pruned model to mimic the behavior of the original model.
- This can lead to significant improvements in the performance of the pruned model compared to traditional pruning methods.
Plain English Explanation
The researchers have developed a new way to make machine learning models smaller and more efficient, without sacrificing too much performance. The basic idea is to start with a large, powerful machine learning model that has been trained on a lot of data. Then, they selectively remove some of the data samples that the model was trained on - a process called "data pruning".
However, instead of just removing the data samples randomly, they use a special technique called "knowledge distillation" to distill the important knowledge from the original, large model into a smaller, pruned model. This helps the smaller model learn to behave a lot like the original model, even though it was trained on less data.
The key benefit of this approach is that the pruned model can achieve similar performance to the original model, but with far fewer parameters and less computational requirements. This can be very useful for deploying machine learning models on resource-constrained devices like phones or embedded systems.
Technical Explanation
The core of the researchers' approach is to use knowledge distillation to transfer the knowledge from a large, powerful "teacher" model to a smaller, more efficient "student" model. Specifically, they train the student model to mimic the probability distributions outputted by the teacher model, rather than just learning to predict the ground truth labels directly.
This allows the student model to capture more of the nuanced knowledge encoded in the teacher model, going beyond just memorizing the correct labels. The researchers show that this "knowledge distillation" process is key to enabling effective data pruning - by carefully selecting which data samples to remove, they can significantly reduce the size of the model without incurring large performance penalties.
Their pruning algorithm works by iteratively removing the data samples that the student model finds easiest to predict, based on the entropy of the student model's output probabilities. This focuses the student model's training on the more informative and challenging samples, allowing it to learn a more generalizable representation.
Through extensive experiments on image classification benchmarks, the researchers demonstrate that their knowledge distillation-based pruning approach can outperform traditional pruning methods by a significant margin, achieving much higher accuracy for a given model size.
Critical Analysis
The researchers present a compelling approach to data pruning that leverages knowledge distillation to preserve model performance. However, a few potential limitations and areas for further exploration are worth considering:
-
Computational Overhead: While the final pruned models are more efficient, the knowledge distillation process itself adds computational overhead during training. The researchers do not provide a detailed analysis of the training time and resource requirements compared to simpler pruning methods.
-
Domain Generalization: The experiments focus on standard image classification benchmarks. It would be valuable to evaluate the approach on a wider range of tasks and datasets to assess its robustness and generalization capabilities.
-
Interpretability: The knowledge distillation process can be viewed as a "black box" - it's not always clear which aspects of the teacher model's knowledge are being most effectively transferred to the student. Exploring more interpretable pruning methods could be a fruitful area for future work.
-
Interaction with Other Techniques: The researchers' approach could potentially be combined with other model compression and efficiency techniques, such as low-rank factorization or architecture search. Investigating these synergies could lead to even more efficient model designs.
Overall, the paper presents a novel and promising approach to data pruning that merits further exploration and refinement. The key insight of leveraging knowledge distillation to guide the pruning process is a significant contribution to the field of model compression and efficiency.
Conclusion
This paper introduces a novel data pruning technique that combines knowledge distillation with selective data removal to produce smaller, more efficient machine learning models without sacrificing too much performance. By training a student model to mimic the behavior of a larger, more powerful teacher model, the researchers are able to distill the most important knowledge into a compact representation.
The results demonstrate that this knowledge distillation-based pruning approach can outperform traditional pruning methods, leading to models that are significantly smaller but maintain strong predictive accuracy. This has important implications for deploying machine learning models on resource-constrained devices, where model size and efficiency are critical concerns.
While the paper focuses on image classification tasks, the general principles of the technique could potentially be applied to a wide range of machine learning problems. Further research exploring the interaction with other model compression techniques and the generalization to new domains could help expand the reach and impact of this innovative pruning method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distilling the Knowledge in Data Pruning
Emanuel Ben-Baruch, Adam Botach, Igor Kviatkovsky, Manoj Aggarwal, G'erard Medioni
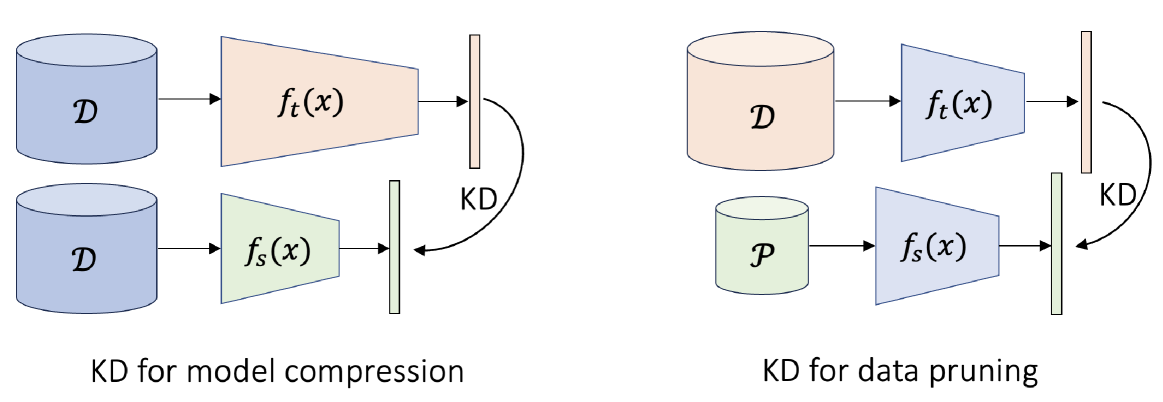
With the increasing size of datasets used for training neural networks, data pruning becomes an attractive field of research. However, most current data pruning algorithms are limited in their ability to preserve accuracy compared to models trained on the full data, especially in high pruning regimes. In this paper we explore the application of data pruning while incorporating knowledge distillation (KD) when training on a pruned subset. That is, rather than relying solely on ground-truth labels, we also use the soft predictions from a teacher network pre-trained on the complete data. By integrating KD into training, we demonstrate significant improvement across datasets, pruning methods, and on all pruning fractions. We first establish a theoretical motivation for employing self-distillation to improve training on pruned data. Then, we empirically make a compelling and highly practical observation: using KD, simple random pruning is comparable or superior to sophisticated pruning methods across all pruning regimes. On ImageNet for example, we achieve superior accuracy despite training on a random subset of only 50% of the data. Additionally, we demonstrate a crucial connection between the pruning factor and the optimal knowledge distillation weight. This helps mitigate the impact of samples with noisy labels and low-quality images retained by typical pruning algorithms. Finally, we make an intriguing observation: when using lower pruning fractions, larger teachers lead to accuracy degradation, while surprisingly, employing teachers with a smaller capacity than the student's may improve results. Our code will be made available.
Read more8/15/2024
0
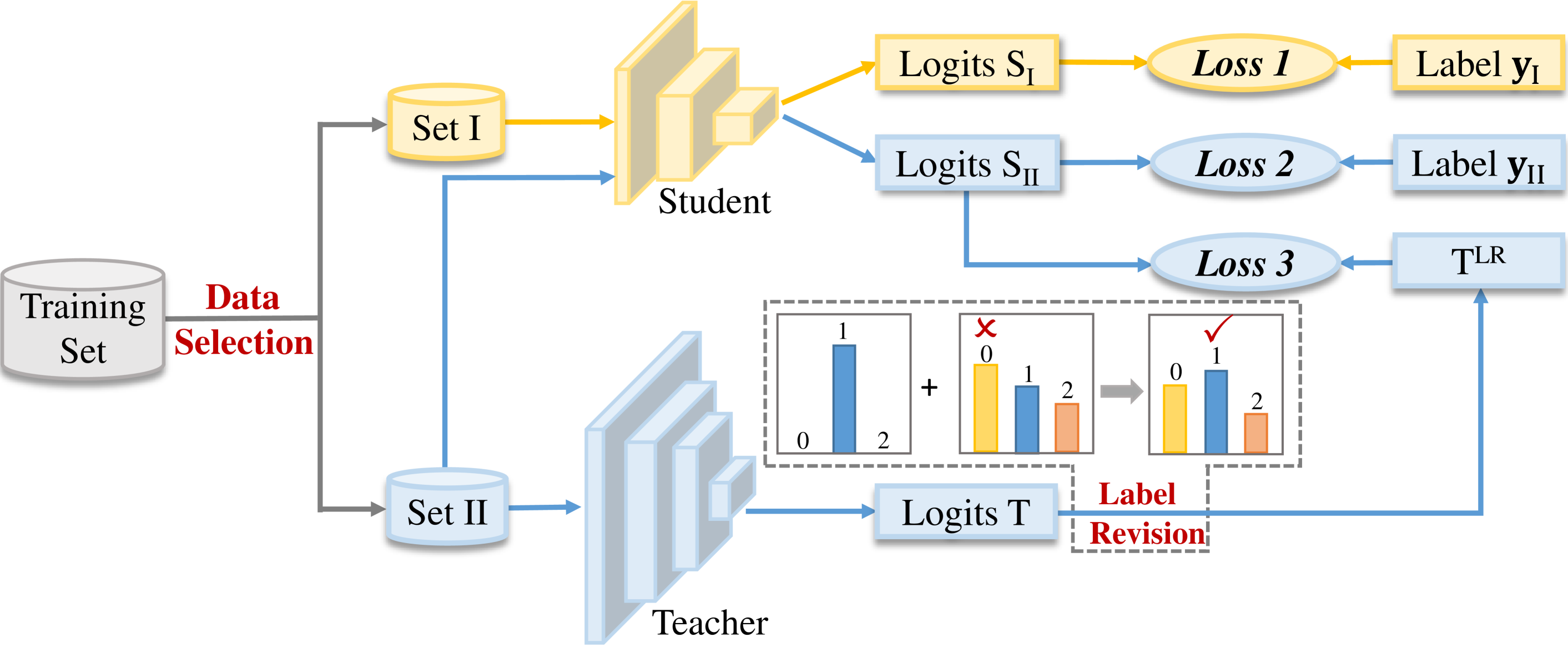
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Read more4/8/2024

0
Small Scale Data-Free Knowledge Distillation
He Liu, Yikai Wang, Huaping Liu, Fuchun Sun, Anbang Yao
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
Read more6/13/2024

0
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
Nikhil Khani, Shuo Yang, Aniruddh Nath, Yang Liu, Pendo Abbo, Li Wei, Shawn Andrews, Maciej Kula, Jarrod Kahn, Zhe Zhao, Lichan Hong, Ed Chi
Knowledge Distillation (KD) is a powerful approach for compressing a large model into a smaller, more efficient model, particularly beneficial for latency-sensitive applications like recommender systems. However, current KD research predominantly focuses on Computer Vision (CV) and NLP tasks, overlooking unique data characteristics and challenges inherent to recommender systems. This paper addresses these overlooked challenges, specifically: (1) mitigating data distribution shifts between teacher and student models, (2) efficiently identifying optimal teacher configurations within time and budgetary constraints, and (3) enabling computationally efficient and rapid sharing of teacher labels to support multiple students. We present a robust KD system developed and rigorously evaluated on multiple large-scale personalized video recommendation systems within Google. Our live experiment results demonstrate significant improvements in student model performance while ensuring consistent and reliable generation of high quality teacher labels from a continuous data stream of data.
Read more8/28/2024