Distributed Multi-Task Learning for Stochastic Bandits with Context Distribution and Stage-wise Constraints

0
✨
Sign in to get full access
Overview
- The paper presents the problem of conservative distributed multi-task learning in stochastic linear contextual bandits with heterogeneous agents.
- It extends conservative linear bandits to a distributed setting where multiple agents tackle different but related tasks while adhering to stage-wise performance constraints.
- The agents have access to a context distribution, rather than the exact context, as in many real-world applications like stock market prediction and weather forecasting.
- The authors propose a distributed upper confidence bound (UCB) algorithm, DiSC-UCB, that ensures the constraints are met and includes synchronized sharing of estimates among agents.
- The paper also considers a setting where agents are unaware of the baseline reward and provides a modified algorithm, DiSC-UCB2, that achieves the same regret and communication bounds.
- The performance of the algorithms is validated on synthetic data and real-world Movielens-100K data.
Plain English Explanation
The paper deals with the challenge of having multiple agents, each working on a slightly different but related task, while also making sure that their performance doesn't drop below a certain threshold. Imagine a team of financial analysts, each responsible for predicting the returns of a different stock, but they all need to maintain a minimum level of accuracy.
The key idea is to have a central system that coordinates the agents and ensures they stay within the performance constraints. The agents don't have full information about the context (like the current state of the market), but only a general idea of the context distribution (what the market is typically like). The paper presents an algorithm called DiSC-UCB that helps the agents navigate this uncertainty while still meeting their performance goals.
The algorithm works by carefully selecting a set of actions for each agent during each round, ensuring that the constraints are satisfied. It also facilitates the sharing of information between agents through a central server, allowing them to learn from each other's experiences.
The paper also considers a scenario where the agents don't even know the baseline reward (how well they would do without any intervention). For this case, the authors propose a modified algorithm, DiSC-UCB2, that still achieves the same strong performance guarantees.
The researchers validate their approach on both synthetic data and a real-world movie recommendation dataset, demonstrating the practical relevance and effectiveness of their methods.
Technical Explanation
The paper presents a distributed no-regret learning framework for multi-task learning in stochastic linear contextual bandits with heterogeneous agents. Each agent faces a different but related task, and they must adhere to stage-wise performance constraints.
The authors propose the DiSC-UCB algorithm, which constructs a pruned action set for each agent during each round to ensure the constraints are met. DiSC-UCB also includes synchronized sharing of estimates among agents via a central server, using well-structured synchronization steps.
The paper proves regret and communication bounds for the DiSC-UCB algorithm. It then extends the problem to a setting where agents are unaware of the baseline reward and provides the DiSC-UCB2 algorithm, which achieves the same guarantees.
The experimental validation on synthetic data and the Movielens-100K dataset demonstrates the effectiveness of the proposed algorithms in practical applications, such as stock market prediction and weather forecasting.
Critical Analysis
The paper addresses an important problem in the context of distributed learning, where multiple agents need to collaborate while adhering to performance constraints. The authors' approach of pruning the action set and synchronizing estimates across agents is a novel and promising solution.
However, the paper does not delve into the practical challenges of implementing such a system in real-world scenarios. For example, the assumption of a known context distribution may not always hold, and the agents may need to learn this distribution as well. Additionally, the communication overhead required for the synchronized updates could be a bottleneck in large-scale deployments.
Further research could explore more efficient communication protocols, as well as ways to relax the assumptions on context distribution knowledge. Investigating the robustness of the algorithms to model misspecification and other practical considerations would also be valuable.
Overall, the paper presents an interesting and well-designed approach to the problem of conservative distributed multi-task learning. The technical contributions and performance guarantees are impressive, but more work may be needed to bridge the gap between the theoretical framework and practical implementation.
Conclusion
The paper tackles the challenging problem of conservative distributed multi-task learning in stochastic linear contextual bandits. By proposing the DiSC-UCB and DiSC-UCB2 algorithms, the authors provide a principled approach to coordinating multiple agents with different but related tasks while ensuring their performance remains within acceptable bounds.
The technical insights and performance guarantees presented in the paper are valuable additions to the field of distributed learning. The experimental validation on synthetic and real-world data further demonstrates the practical relevance and effectiveness of the proposed methods.
While the paper focuses on the theoretical aspects, future research could explore more practical considerations and ways to adapt the algorithms to real-world deployments. Overall, this work contributes to the broader goal of enabling collaborative and constrained learning systems, with potential applications in areas like finance, weather prediction, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Distributed Multi-Task Learning for Stochastic Bandits with Context Distribution and Stage-wise Constraints
Jiabin Lin, Shana Moothedath
We present the problem of conservative distributed multi-task learning in stochastic linear contextual bandits with heterogeneous agents. This extends conservative linear bandits to a distributed setting where M agents tackle different but related tasks while adhering to stage-wise performance constraints. The exact context is unknown, and only a context distribution is available to the agents as in many practical applications that involve a prediction mechanism to infer context, such as stock market prediction and weather forecast. We propose a distributed upper confidence bound (UCB) algorithm, DiSC-UCB. Our algorithm constructs a pruned action set during each round to ensure the constraints are met. Additionally, it includes synchronized sharing of estimates among agents via a central server using well-structured synchronization steps. We prove the regret and communication bounds on the algorithm. We extend the problem to a setting where the agents are unaware of the baseline reward. For this setting, we provide a modified algorithm, DiSC-UCB2, and we show that the modified algorithm achieves the same regret and communication bounds. We empirically validated the performance of our algorithm on synthetic data and real-world Movielens-100K data.
Read more4/11/2024

0
Contextual Bandits for Unbounded Context Distributions
Puning Zhao, Jiafei Wu, Zhe Liu, Huiwen Wu
Nonparametric contextual bandit is an important model of sequential decision making problems. Under $alpha$-Tsybakov margin condition, existing research has established a regret bound of $tilde{O}left(T^{1-frac{alpha+1}{d+2}}right)$ for bounded supports. However, the optimal regret with unbounded contexts has not been analyzed. The challenge of solving contextual bandit problems with unbounded support is to achieve both exploration-exploitation tradeoff and bias-variance tradeoff simultaneously. In this paper, we solve the nonparametric contextual bandit problem with unbounded contexts. We propose two nearest neighbor methods combined with UCB exploration. The first method uses a fixed $k$. Our analysis shows that this method achieves minimax optimal regret under a weak margin condition and relatively light-tailed context distributions. The second method uses adaptive $k$. By a proper data-driven selection of $k$, this method achieves an expected regret of $tilde{O}left(T^{1-frac{(alpha+1)beta}{alpha+(d+2)beta}}+T^{1-beta}right)$, in which $beta$ is a parameter describing the tail strength. This bound matches the minimax lower bound up to logarithm factors, indicating that the second method is approximately optimal.
Read more8/20/2024
0
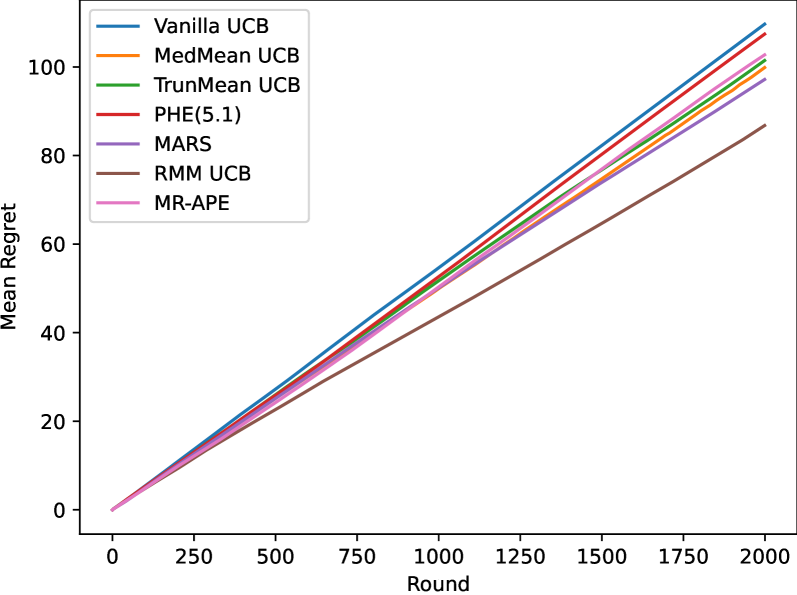
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024
0
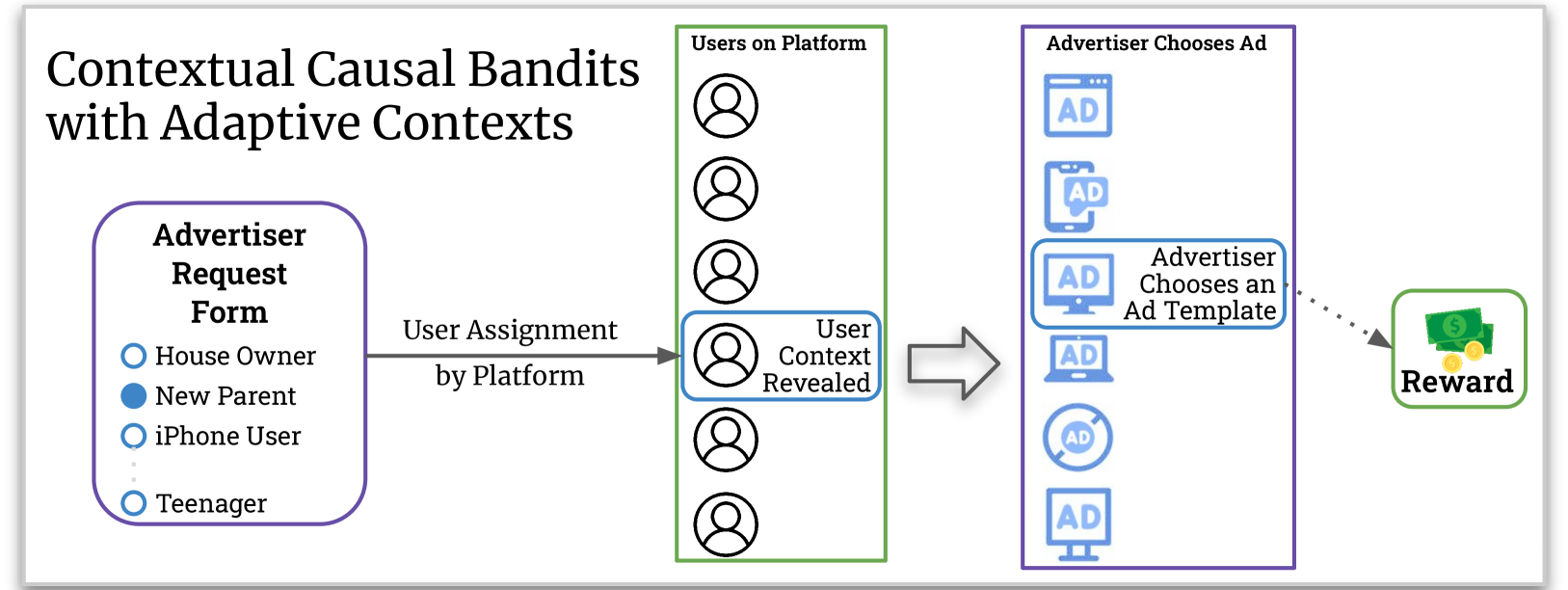
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024