Distributed Training of Large Graph Neural Networks with Variable Communication Rates

0
Sign in to get full access
Overview
- This paper explores techniques for the distributed training of large Graph Neural Networks (GNNs) with variable communication rates.
- GNNs are a type of neural network that can effectively model and learn from graph-structured data, making them valuable for tasks like social network analysis, recommendation systems, and drug discovery.
- Distributed training techniques are used to scale the training of large GNN models across multiple compute nodes, but can be challenging due to the high communication requirements.
- The paper proposes methods to address this challenge by reducing the amount of data that needs to be communicated between nodes during training.
Plain English Explanation
Distributed training is a technique used to train large machine learning models like Graph Neural Networks (GNNs) across multiple computers. This allows the training to be done much faster than on a single computer. However, the computers need to communicate a lot of data between each other during the training process, which can slow things down.
The researchers in this paper developed new methods to reduce the amount of data that needs to be communicated between the computers during GNN training. This allows the training to be done more efficiently, especially for very large GNN models. The key ideas involve selectively communicating only the most important information between the computers, and adapting the communication rates based on the needs of the training process.
By making GNN training more efficient through reduced communication, this work can enable the use of larger and more powerful GNN models for tasks like social network analysis, recommendation systems, and drug discovery. This could lead to improved performance on these important real-world applications.
Technical Explanation
The paper proposes two key techniques for distributed training of large Graph Neural Networks (GNNs) with variable communication rates:
-
Adaptive Communication: The amount of data communicated between compute nodes is dynamically adjusted based on the training progress and the importance of the information being shared. This helps reduce unnecessary communication overhead.
-
Selective Communication: Only the most important parameters and gradients are selectively communicated between nodes, reducing the total volume of data that needs to be exchanged.
The paper evaluates these techniques on several large-scale GNN training tasks, including social network analysis, recommendation systems, and drug discovery. The results show significant improvements in training efficiency and scalability compared to baseline distributed training approaches.
Critical Analysis
The paper provides a thorough technical explanation of the proposed techniques and demonstrates their effectiveness through rigorous experimentation. However, a few potential limitations and areas for further research are worth noting:
-
The adaptive communication and selective communication approaches rely on heuristics and thresholds that may need careful tuning for different problem domains and model architectures. More principled methods for dynamically adjusting these parameters could further improve robustness.
-
The experiments are conducted on relatively homogeneous compute clusters. It would be valuable to evaluate the techniques on more heterogeneous compute environments, which are common in real-world distributed training setups.
-
The paper does not explore the impact of the proposed methods on the final model performance, beyond training efficiency. Further analysis is needed to ensure that the communication reduction techniques do not adversely affect the quality of the learned GNN models.
-
Extending the techniques to support asynchronous and decentralized training scenarios could broaden the applicability of the methods.
Overall, the paper presents a compelling approach to address a significant challenge in the distributed training of large-scale GNN models. The ideas and experimental results provide a solid foundation for further research and development in this important area.
Conclusion
This paper introduces novel techniques for the distributed training of large Graph Neural Networks (GNNs) with variable communication rates. By adaptively adjusting the amount of data communicated between compute nodes and selectively sharing only the most important parameters and gradients, the proposed methods can significantly improve the efficiency and scalability of GNN training.
The demonstrated benefits in training speed and resource utilization could enable the use of larger and more powerful GNN models for a wide range of applications, such as social network analysis, recommendation systems, and drug discovery. This work represents an important step forward in addressing the challenges of distributed deep learning for graph-structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distributed Training of Large Graph Neural Networks with Variable Communication Rates
Juan Cervino, Md Asadullah Turja, Hesham Mostafa, Nageen Himayat, Alejandro Ribeiro
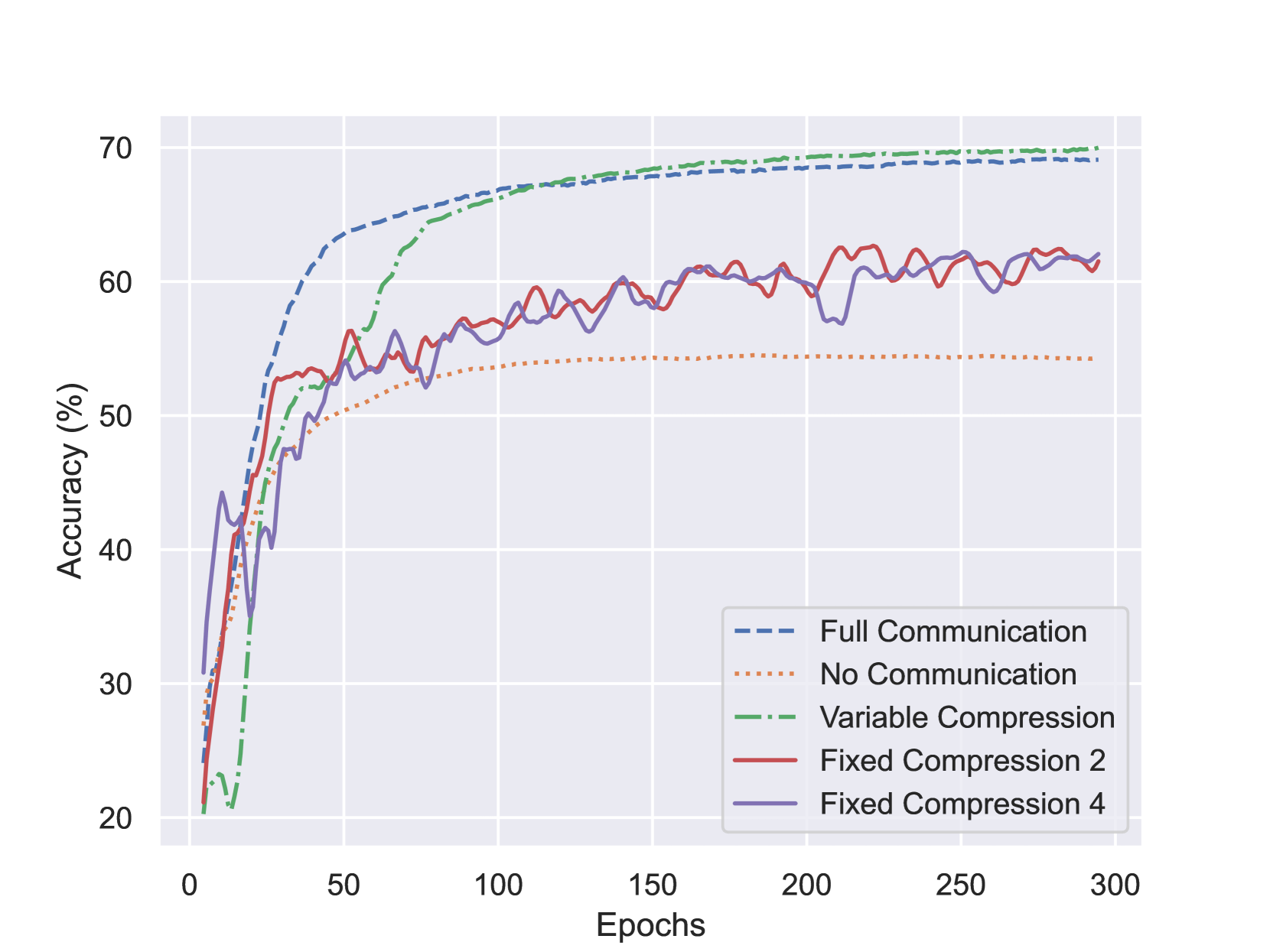
Training Graph Neural Networks (GNNs) on large graphs presents unique challenges due to the large memory and computing requirements. Distributed GNN training, where the graph is partitioned across multiple machines, is a common approach to training GNNs on large graphs. However, as the graph cannot generally be decomposed into small non-interacting components, data communication between the training machines quickly limits training speeds. Compressing the communicated node activations by a fixed amount improves the training speeds, but lowers the accuracy of the trained GNN. In this paper, we introduce a variable compression scheme for reducing the communication volume in distributed GNN training without compromising the accuracy of the learned model. Based on our theoretical analysis, we derive a variable compression method that converges to a solution equivalent to the full communication case, for all graph partitioning schemes. Our empirical results show that our method attains a comparable performance to the one obtained with full communication. We outperform full communication at any fixed compression ratio for any communication budget.
Read more6/26/2024
🖼️
0
Data-Aware Gradient Compression for DML in Communication-Constrained Mobile Computing
Rongwei Lu, Yutong Jiang, Yinan Mao, Chen Tang, Bin Chen, Laizhong Cui, Zhi Wang
Distributed machine learning (DML) in mobile environments faces significant communication bottlenecks. Gradient compression has proven as an effective solution to this issue, offering substantial benefits in environments with limited bandwidth and metered data. Yet, it encounters severe performance drops in non-IID environments due to a one-size-fits-all compression approach, which does not account for the varying data volumes across workers. Assigning varying compression ratios to workers with distinct data distributions and volumes is therefore a promising solution. This work derives the convergence rate of distributed SGD with non-uniform compression, which reveals the intricate relationship between model convergence and the compression ratios applied to individual workers. Accordingly, we frame the relative compression ratio assignment as an $n$-variable chi-squared nonlinear optimization problem, constrained by a limited communication budget. We propose DAGC-R, which assigns conservative compression to workers handling larger data volumes. Recognizing the computational limitations of mobile devices, we propose the DAGC-A, which is computationally less demanding and enhances the robustness of compression in non-IID scenarios. Our experiments confirm that the DAGC-A and DAGC-R can speed up the training speed by up to $16.65%$ and $25.43%$ compared to the uniform compression respectively, when dealing with highly imbalanced data volume distribution and restricted communication.
Read more9/4/2024
🧠
0
An Experimental Comparison of Partitioning Strategies for Distributed Graph Neural Network Training
Nikolai Merkel, Daniel Stoll, Ruben Mayer, Hans-Arno Jacobsen
Recently, graph neural networks (GNNs) have gained much attention as a growing area of deep learning capable of learning on graph-structured data. However, the computational and memory requirements for training GNNs on large-scale graphs make it necessary to distribute the training. A prerequisite for distributed GNN training is to partition the input graph into smaller parts that are distributed among multiple machines of a compute cluster. Although graph partitioning has been studied with regard to graph analytics and graph databases, its effect on GNN training performance is largely unexplored. As a consequence, it is unclear whether investing computational efforts into high-quality graph partitioning would pay off in GNN training scenarios. In this paper, we study the effectiveness of graph partitioning for distributed GNN training. Our study aims to understand how different factors such as GNN parameters, mini-batch size, graph type, features size, and scale-out factor influence the effectiveness of graph partitioning. We conduct experiments with two different GNN systems using vertex and edge partitioning. We found that high-quality graph partitioning is a very effective optimization to speed up GNN training and to reduce memory consumption. Furthermore, our results show that invested partitioning time can quickly be amortized by reduced GNN training time, making it a relevant optimization for most GNN scenarios. Compared to research on distributed graph processing, our study reveals that graph partitioning plays an even more significant role in distributed GNN training, which motivates further research on the graph partitioning problem.
Read more8/13/2024

0
Communication Optimization for Distributed Training: Architecture, Advances, and Opportunities
Yunze Wei, Tianshuo Hu, Cong Liang, Yong Cui
The past few years have witnessed the flourishing of large-scale deep neural network models with ever-growing parameter numbers. Training such large-scale models typically requires massive memory and computing resources, necessitating distributed training. As GPU performance has rapidly evolved in recent years, computation time has shrunk, making communication a larger portion of the overall training time. Consequently, optimizing communication for distributed training has become crucial. In this article, we briefly introduce the general architecture of distributed deep neural network training and analyze relationships among Parallelization Strategy, Collective Communication Library, and Network from the perspective of communication optimization, which forms a three-layer paradigm. We then review current representative research advances within this three-layer paradigm. We find that layers in the current three-layer paradigm are relatively independent and there is a rich design space for cross-layer collaborative optimization in distributed training scenarios. Therefore, we advocate Vertical and Horizontal co-designs which extend the three-layer paradigm to a five-layer paradigm. We also advocate Intra-Inter and Host-Net co-designs to further utilize the potential of heterogeneous resources. We hope this article can shed some light on future research on communication optimization for distributed training.
Read more8/30/2024