Distribution-Free Fair Federated Learning with Small Samples

0

Sign in to get full access
Overview
- This paper proposes a new approach for fair federated learning with small data samples.
- The key ideas are to avoid making assumptions about the data distribution and to ensure fairness for different groups.
- The authors demonstrate the effectiveness of their method through experiments on real-world datasets.
Plain English Explanation
Federated learning is a way for multiple organizations to train a shared machine learning model without directly sharing their private data. This can be helpful when data is sensitive or distributed across different locations. However, it can be challenging to ensure the resulting model is fair, meaning it treats different groups of people equally.
The authors of this paper introduce a new federated learning approach that addresses this fairness challenge. Rather than making assumptions about the distribution of the data, their method adapts to the specific characteristics of each participating organization's dataset. This allows the model to be fair even when the data comes from diverse sources.
The core idea is to learn a shared model that performs well on average across all the participating organizations, while also ensuring that the model does not discriminate against any particular group. This is achieved through a specialized optimization procedure that balances the overall model performance with fairness considerations.
The researchers demonstrate the effectiveness of their approach using real-world datasets. They show that their method can produce fair models even when the participating organizations have small amounts of data, which is a common scenario in federated learning. This makes the technique particularly useful for practical applications where data privacy and fairness are important.
Technical Explanation
The paper introduces a new federated learning algorithm that can achieve fair models without making assumptions about the data distribution. The key innovations are:
-
Distribution-Free Fairness: Instead of assuming a specific data distribution, the proposed method adapts to the characteristics of each participating organization's dataset. This allows the algorithm to ensure fairness without relying on restrictive assumptions.
-
Small-Sample Fairness: The authors show that their approach can produce fair models even when the local datasets are small, which is a common challenge in federated learning scenarios.
-
Optimization Procedure: The algorithm jointly optimizes for overall model performance and fairness across different groups. This is achieved through a specialized loss function and update rules.
The paper evaluates the proposed method on multiple real-world datasets and demonstrates its advantages over existing federated learning approaches in terms of both accuracy and fairness.
Critical Analysis
The paper presents a well-designed and technically sound solution to the problem of ensuring fairness in federated learning with small data samples. The authors acknowledge the limitations of their approach, such as the need for additional communication rounds and the potential for biased data in the participating organizations.
One potential area for further research could be exploring ways to reduce the communication overhead of the algorithm, as this can be a significant concern in practical federated learning deployments. Additionally, the paper does not address the issue of model updates over time, which may be important for maintaining fairness as the data and environment evolve.
Overall, the proposed method represents a meaningful contribution to the field of federated learning and fair machine learning. The authors have succeeded in developing a technique that can produce fair models without relying on restrictive assumptions about the data distribution, which is a significant advancement in the state of the art.
Conclusion
This paper presents a novel federated learning algorithm that can achieve fair models without making assumptions about the data distribution. The key innovations are the ability to adapt to the characteristics of each participating organization's dataset and the joint optimization of overall model performance and fairness across different groups.
The researchers demonstrate the effectiveness of their approach through experiments on real-world datasets, showing that it can produce fair models even when the local datasets are small. This makes the technique particularly valuable for practical applications where data privacy and fairness are important considerations.
The paper represents a significant contribution to the field of federated learning and fair machine learning, and the proposed method has the potential to have a meaningful impact on the development of equitable and inclusive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distribution-Free Fair Federated Learning with Small Samples
Qichuan Yin, Zexian Wang, Junzhou Huang, Huaxiu Yao, Linjun Zhang
As federated learning gains increasing importance in real-world applications due to its capacity for decentralized data training, addressing fairness concerns across demographic groups becomes critically important. However, most existing machine learning algorithms for ensuring fairness are designed for centralized data environments and generally require large-sample and distributional assumptions, underscoring the urgent need for fairness techniques adapted for decentralized and heterogeneous systems with finite-sample and distribution-free guarantees. To address this issue, this paper introduces FedFaiREE, a post-processing algorithm developed specifically for distribution-free fair learning in decentralized settings with small samples. Our approach accounts for unique challenges in decentralized environments, such as client heterogeneity, communication costs, and small sample sizes. We provide rigorous theoretical guarantees for both fairness and accuracy, and our experimental results further provide robust empirical validation for our proposed method.
Read more9/16/2024

0
Federated Fairness Analytics: Quantifying Fairness in Federated Learning
Oscar Dilley, Juan Marcelo Parra-Ullauri, Rasheed Hussain, Dimitra Simeonidou
Federated Learning (FL) is a privacy-enhancing technology for distributed ML. By training models locally and aggregating updates - a federation learns together, while bypassing centralised data collection. FL is increasingly popular in healthcare, finance and personal computing. However, it inherits fairness challenges from classical ML and introduces new ones, resulting from differences in data quality, client participation, communication constraints, aggregation methods and underlying hardware. Fairness remains an unresolved issue in FL and the community has identified an absence of succinct definitions and metrics to quantify fairness; to address this, we propose Federated Fairness Analytics - a methodology for measuring fairness. Our definition of fairness comprises four notions with novel, corresponding metrics. They are symptomatically defined and leverage techniques originating from XAI, cooperative game-theory and networking engineering. We tested a range of experimental settings, varying the FL approach, ML task and data settings. The results show that statistical heterogeneity and client participation affect fairness and fairness conscious approaches such as Ditto and q-FedAvg marginally improve fairness-performance trade-offs. Using our techniques, FL practitioners can uncover previously unobtainable insights into their system's fairness, at differing levels of granularity in order to address fairness challenges in FL. We have open-sourced our work at: https://github.com/oscardilley/federated-fairness.
Read more8/16/2024
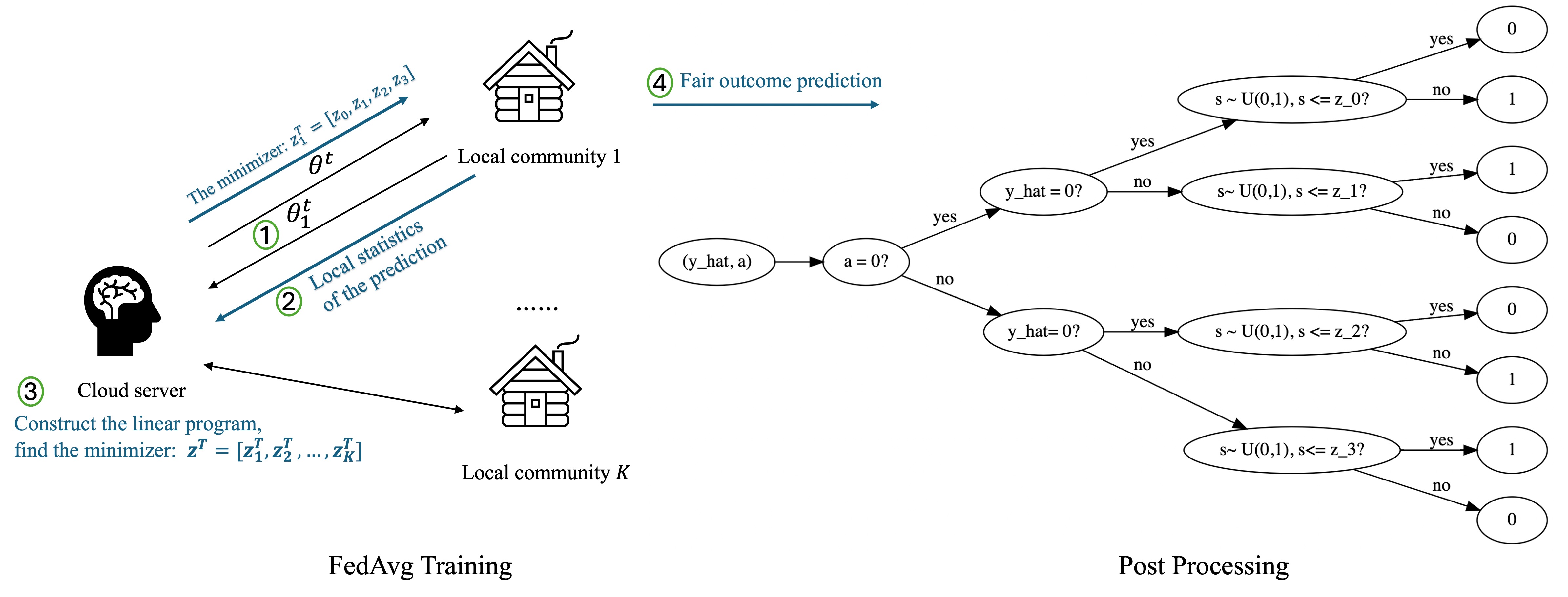
0
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
Yuying Duan, Yijun Tian, Nitesh Chawla, Michael Lemmon
Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.
Read more5/29/2024
🌐
0
Fairness Without Demographics in Human-Centered Federated Learning
Shaily Roy, Harshit Sharma, Asif Salekin
Federated learning (FL) enables collaborative model training while preserving data privacy, making it suitable for decentralized human-centered AI applications. However, a significant research gap remains in ensuring fairness in these systems. Current fairness strategies in FL require knowledge of bias-creating/sensitive attributes, clashing with FL's privacy principles. Moreover, in human-centered datasets, sensitive attributes may remain latent. To tackle these challenges, we present a novel bias mitigation approach inspired by Fairness without Demographics in machine learning. The presented approach achieves fairness without needing knowledge of sensitive attributes by minimizing the top eigenvalue of the Hessian matrix during training, ensuring equitable loss landscapes across FL participants. Notably, we introduce a novel FL aggregation scheme that promotes participating models based on error rates and loss landscape curvature attributes, fostering fairness across the FL system. This work represents the first approach to attaining Fairness without Demographics in human-centered FL. Through comprehensive evaluation, our approach demonstrates effectiveness in balancing fairness and efficacy across various real-world applications, FL setups, and scenarios involving single and multiple bias-inducing factors, representing a significant advancement in human-centered FL.
Read more5/17/2024