DIVESPOT: Depth Integrated Volume Estimation of Pile of Things Based on Point Cloud

0
Sign in to get full access
Overview
- Introduces a method called DIVESPOT for estimating the volume of piles of objects based on 3D point cloud data
- Aims to provide accurate volume estimates without the need for complex 3D reconstruction
- Proposes a novel depth-integrated voxel-based approach to capture the shape and size of piles
Plain English Explanation
The paper presents a technique called DIVESPOT (Depth Integrated Volume Estimation of Pile of Things) that can estimate the volume of piles of objects using 3D point cloud data. Rather than attempting to fully reconstruct the 3D shape of the pile, DIVESPOT takes a more efficient approach by using a voxel-based method to capture the overall size and structure of the pile.
The key idea is to create a 3D grid of voxels (3D pixels) and then integrate the depth information from the point cloud data to determine the occupancy and height of each voxel. This allows DIVESPOT to build up a compact representation of the pile's shape without needing to perform a complete 3D reconstruction, which can be computationally intensive.
By focusing on the overall volume and shape of the pile rather than its exact geometry, DIVESPOT is able to provide accurate volume estimates more efficiently. This could be useful in applications like inventory management, where quickly estimating the volume of a pile of goods is more important than having a detailed 3D model.
Technical Explanation
The DIVESPOT method works by first converting the 3D point cloud data into a voxel grid. It does this in a way that is similar to the techniques used in papers like ,[object Object]. The height of each voxel is then determined by integrating the depth information from the point cloud, capturing the overall shape and size of the pile without needing to perform a full 3D reconstruction.
The authors also introduce a novel "depth-integrated" approach that allows DIVESPOT to better handle occlusions and incomplete point cloud data. This is important because real-world point clouds often have missing data due to sensor limitations or occlusions from the objects themselves.
DIVESPOT was evaluated on both simulated and real-world piles of objects, demonstrating its ability to provide accurate volume estimates compared to ground truth data. The results show that DIVESPOT can achieve high accuracy while being more efficient than approaches that require detailed 3D modeling.
Critical Analysis
The paper provides a compelling approach to efficiently estimating the volume of piles of objects using 3D point cloud data. The DIVESPOT method appears to be a practical solution that balances accuracy and computational efficiency, which could make it useful for real-world applications.
However, the paper does not extensively explore the limitations of the technique. For example, it is not clear how DIVESPOT would perform on highly irregular or complex pile shapes, or how sensitive the results are to the quality and resolution of the input point cloud data. Further research could investigate these edge cases and explore ways to improve the robustness of the method, similar to the work done in ,[object Object].
Additionally, while the paper demonstrates the accuracy of DIVESPOT, it does not provide much insight into the real-world implications or potential use cases for this technology. A more thorough discussion of how this method could be applied in practice and the potential benefits it could provide would strengthen the overall contribution of the research.
Conclusion
The DIVESPOT method presented in this paper offers a novel approach to estimating the volume of piles of objects using 3D point cloud data. By focusing on the overall shape and size of the pile rather than attempting a full 3D reconstruction, DIVESPOT is able to provide accurate volume estimates in a computationally efficient manner.
This technique could have practical applications in inventory management, logistics, and other domains where quickly and accurately measuring the volume of piles of goods is important. While the paper leaves some open questions about the method's limitations and real-world implications, it represents a valuable contribution to the field of 3D perception and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DIVESPOT: Depth Integrated Volume Estimation of Pile of Things Based on Point Cloud
Yiran Ling, Rongqiang Zhao, Yixuan Shen, Dongbo Li, Jing Jin, Jie Liu
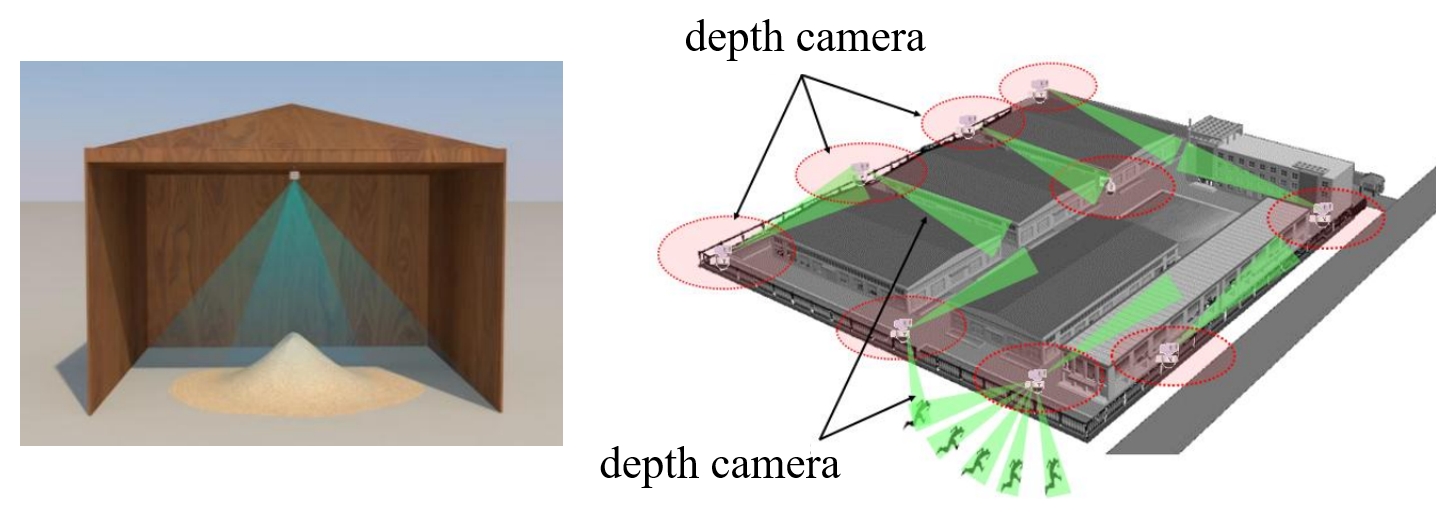
Non-contact volume estimation of pile-type objects has considerable potential in industrial scenarios, including grain, coal, mining, and stone materials. However, using existing method for these scenarios is challenged by unstable measurement poses, significant light interference, the difficulty of training data collection, and the computational burden brought by large piles. To address the above issues, we propose the Depth Integrated Volume EStimation of Pile Of Things (DIVESPOT) based on point cloud technology in this study. For the challenges of unstable measurement poses, the point cloud pose correction and filtering algorithm is designed based on the Random Sample Consensus (RANSAC) and the Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN). To cope with light interference and to avoid the relying on training data, the height-distribution-based ground feature extraction algorithm is proposed to achieve RGB-independent. To reduce the computational burden, the storage space optimizing strategy is developed, such that accurate estimation can be acquired by using compressed voxels. Experimental results demonstrate that the DIVESPOT method enables non-data-driven, RGB-independent segmentation of pile point clouds, maintaining a volume calculation relative error within 2%. Even with 90% compression of the voxel mesh, the average error of the results can be under 3%.
Read more7/9/2024

0
Uplifting Range-View-based 3D Semantic Segmentation in Real-Time with Multi-Sensor Fusion
Shiqi Tan, Hamidreza Fazlali, Yixuan Xu, Yuan Ren, Bingbing Liu
Range-View(RV)-based 3D point cloud segmentation is widely adopted due to its compact data form. However, RV-based methods fall short in providing robust segmentation for the occluded points and suffer from distortion of projected RGB images due to the sparse nature of 3D point clouds. To alleviate these problems, we propose a new LiDAR and Camera Range-view-based 3D point cloud semantic segmentation method (LaCRange). Specifically, a distortion-compensating knowledge distillation (DCKD) strategy is designed to remedy the adverse effect of RV projection of RGB images. Moreover, a context-based feature fusion module is introduced for robust and preservative sensor fusion. Finally, in order to address the limited resolution of RV and its insufficiency of 3D topology, a new point refinement scheme is devised for proper aggregation of features in 2D and augmentation of point features in 3D. We evaluated the proposed method on large-scale autonomous driving datasets ie SemanticKITTI and nuScenes. In addition to being real-time, the proposed method achieves state-of-the-art results on nuScenes benchmark
Read more7/16/2024
🧪
0
Voxel-Based Point Cloud Localization for Smart Spaces Management
F. S. Mortazavi, O. Shkedova, U. Feuerhake, C. Brenner, M. Sester
This paper proposes a voxel-based approach for creating a digital twin of an urban environment that is capable of efficiently managing smart spaces. The paper explains the registration and localization procedure of the point cloud dataset, which uses the KISS ICP for scan point cloud combination and the RANSAC method for the initial alignment of the combined point cloud. The mobile mapping point cloud using Riegl VMX-250 serves as the reference map, and Velodyne scans are used for localization purposes. The point-to-plane iterative closest-point method is then employed to refine the alignment. The paper evaluates the efficacy of the proposed method by calculating the errors between the estimated and ground truth positions. The results indicate that the voxel-based approach is capable of accurately estimating the position of the sensor platform, which are applicable for various use cases. A specific use case in the context is smart parking space management, which is described and initial visualization results are shown.
Read more6/24/2024
0
LightOctree: Lightweight 3D Spatially-Coherent Indoor Lighting Estimation
Xuecan Wang, Shibang Xiao, Xiaohui Liang
We present a lightweight solution for estimating spatially-coherent indoor lighting from a single RGB image. Previous methods for estimating illumination using volumetric representations have overlooked the sparse distribution of light sources in space, necessitating substantial memory and computational resources for achieving high-quality results. We introduce a unified, voxel octree-based illumination estimation framework to produce 3D spatially-coherent lighting. Additionally, a differentiable voxel octree cone tracing rendering layer is proposed to eliminate regular volumetric representation throughout the entire process and ensure the retention of features across different frequency domains. This reduction significantly decreases spatial usage and required floating-point operations without substantially compromising precision. Experimental results demonstrate that our approach achieves high-quality coherent estimation with minimal cost compared to previous methods.
Read more4/8/2024