Voxel-Based Point Cloud Localization for Smart Spaces Management
2406.15110
0
0
🧪
Abstract
This paper proposes a voxel-based approach for creating a digital twin of an urban environment that is capable of efficiently managing smart spaces. The paper explains the registration and localization procedure of the point cloud dataset, which uses the KISS ICP for scan point cloud combination and the RANSAC method for the initial alignment of the combined point cloud. The mobile mapping point cloud using Riegl VMX-250 serves as the reference map, and Velodyne scans are used for localization purposes. The point-to-plane iterative closest-point method is then employed to refine the alignment. The paper evaluates the efficacy of the proposed method by calculating the errors between the estimated and ground truth positions. The results indicate that the voxel-based approach is capable of accurately estimating the position of the sensor platform, which are applicable for various use cases. A specific use case in the context is smart parking space management, which is described and initial visualization results are shown.
Create account to get full access
Overview
- Proposes a voxel-based approach for creating a digital twin of an urban environment to efficiently manage smart spaces
- Explains the registration and localization procedure of the point cloud dataset using KISS ICP, RANSAC, and point-to-plane ICP
- Evaluates the accuracy of the proposed method for sensor platform position estimation, applicable to use cases like smart parking space management
Plain English Explanation
The paper describes a method for creating a detailed digital model, or "digital twin," of an urban area that can be used to better manage smart city technologies and infrastructure. The key idea is to use 3D point cloud data, collected from laser scanners mounted on vehicles, to accurately map the environment.
The registration and localization procedure involves combining multiple scans of the area into a single 3D model. This is done using algorithms like KISS ICP to align the scans and RANSAC to handle any initial misalignment. The resulting 3D model can then be used to precisely locate the position of sensors or vehicles moving through the environment.
The paper evaluates the accuracy of this positioning by comparing the estimated locations to ground truth data. The results show the voxel-based approach can accurately track the position of the sensor platform, which is important for applications like smart parking management where knowing the location of vehicles is key.
Technical Explanation
The paper proposes a voxel-based approach for creating a digital twin of an urban environment that can be used for efficient management of smart spaces. The registration and localization procedure for the point cloud dataset involves using the KISS ICP algorithm for scan point cloud combination and the RANSAC method for initial alignment of the combined point cloud.
The mobile mapping point cloud collected using a Riegl VMX-250 system serves as the reference map, while Velodyne scans are used for localization purposes. The point-to-plane iterative closest-point (ICP) method is then employed to further refine the alignment of the scans.
The efficacy of the proposed method is evaluated by calculating the errors between the estimated and ground truth positions of the sensor platform. The results indicate that the voxel-based approach can accurately estimate the position of the sensor platform, which is applicable for various use cases such as smart parking space management.
Critical Analysis
The paper provides a comprehensive approach for creating a digital twin of an urban environment using 3D point cloud data. The use of established algorithms like KISS ICP and RANSAC for the registration and localization procedure seems well-justified and the evaluation of the positioning accuracy is thorough.
However, the paper does not address potential limitations or challenges of the proposed method, such as the impact of environmental factors (e.g., weather conditions, occlusions) on the accuracy of the 3D mapping and localization. Additionally, the computational complexity and processing time of the voxel-based approach are not discussed, which could be important considerations for real-time applications.
Further research could explore ways to improve the robustness and efficiency of the digital twin creation process, such as by investigating zero-shot detection of buildings from mobile LiDAR data or multi-modal point cloud feature extraction to enhance the accuracy and versatility of the system.
Conclusion
This paper presents a voxel-based approach for creating a digital twin of an urban environment that can be used to efficiently manage smart spaces. The key contributions include the registration and localization procedure for the point cloud dataset, which enables accurate positioning of sensor platforms within the 3D model.
The evaluation of the proposed method demonstrates its potential for applications like smart parking management, where knowing the location of vehicles is crucial. While the technical details are well-explained, future research could explore ways to improve the robustness and efficiency of the digital twin creation process, as well as address potential limitations and challenges not covered in this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Instance-free Text to Point Cloud Localization with Relative Position Awareness
Lichao Wang, Zhihao Yuan, Jinke Ren, Shuguang Cui, Zhen Li
0
0
Text-to-point-cloud cross-modal localization is an emerging vision-language task critical for future robot-human collaboration. It seeks to localize a position from a city-scale point cloud scene based on a few natural language instructions. In this paper, we address two key limitations of existing approaches: 1) their reliance on ground-truth instances as input; and 2) their neglect of the relative positions among potential instances. Our proposed model follows a two-stage pipeline, including a coarse stage for text-cell retrieval and a fine stage for position estimation. In both stages, we introduce an instance query extractor, in which the cells are encoded by a 3D sparse convolution U-Net to generate the multi-scale point cloud features, and a set of queries iteratively attend to these features to represent instances. In the coarse stage, a row-column relative position-aware self-attention (RowColRPA) module is designed to capture the spatial relations among the instance queries. In the fine stage, a multi-modal relative position-aware cross-attention (RPCA) module is developed to fuse the text and point cloud features along with spatial relations for improving fine position estimation. Experiment results on the KITTI360Pose dataset demonstrate that our model achieves competitive performance with the state-of-the-art models without taking ground-truth instances as input.
4/30/2024
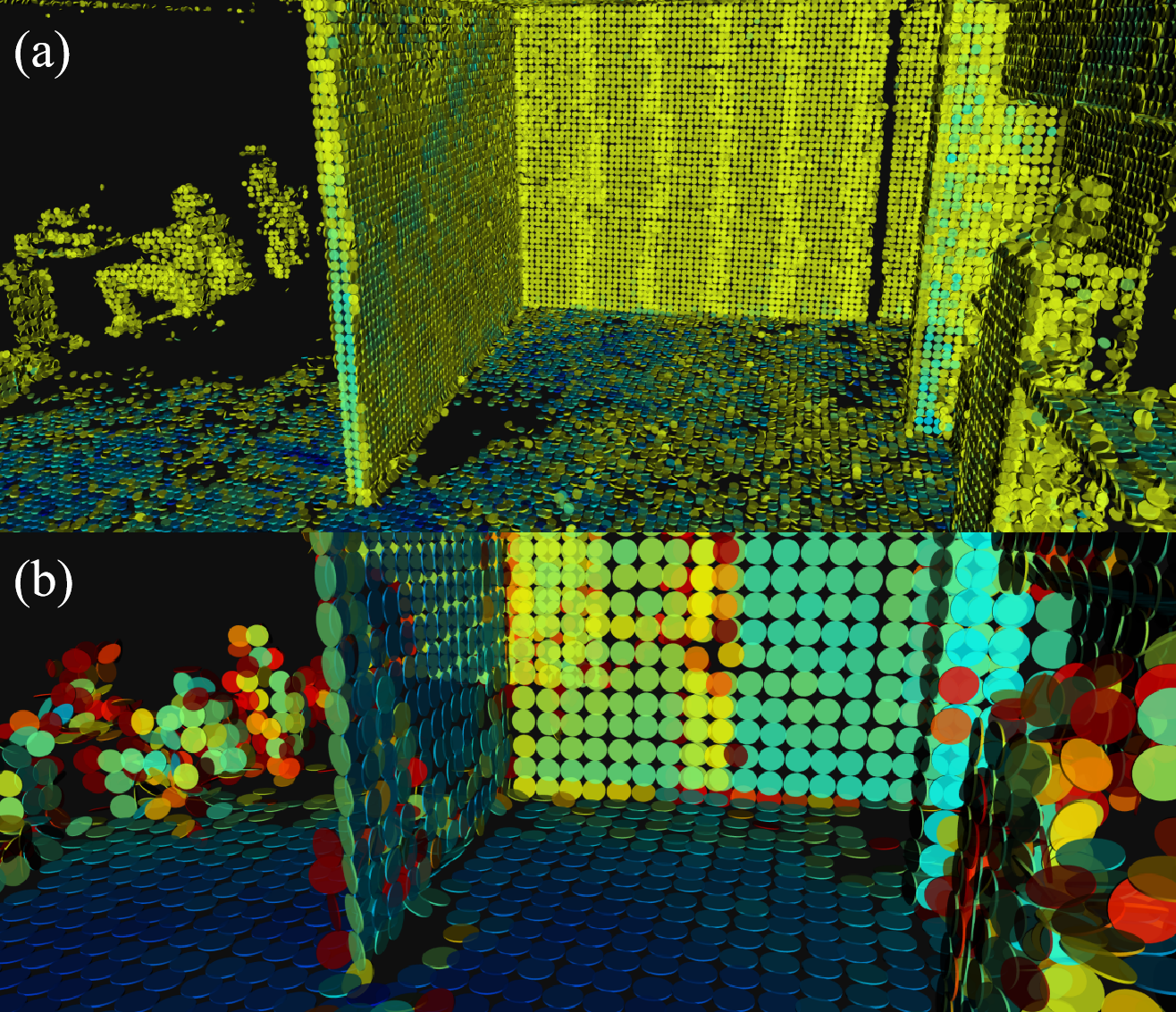
C$^3$P-VoxelMap: Compact, Cumulative and Coalescible Probabilistic Voxel Mapping
Xu Yang, Wenhao Li, Qijie Ge, Lulu Suo, Weijie Tang, Zhengyu Wei, Longxiang Huang, Bo Wang
0
0
This work presents a compact, cumulative and coalescible probabilistic voxel mapping method to enhance performance, accuracy and memory efficiency in LiDAR odometry. Probabilistic voxel mapping requires storing past point clouds and re-iterating on them to update the uncertainty every iteration, which consumes large memory space and CPU cycles. To solve this problem, we propose a two-folded strategy. First, we introduce a compact point-free representation for probabilistic voxels and derive a cumulative update of the planar uncertainty without caching original point clouds. Our voxel structure only keeps track of a predetermined set of statistics for points that lie inside it. This method reduces the runtime complexity from $O(MN)$ to $O(N)$ and the space complexity from $O(N)$ to $O(1)$ where $M$ is the number of iterations and $N$ is the number of points. Second, to further minimize memory usage and enhance mapping accuracy, we provide a strategy to dynamically merge voxels associated with the same physical planes by taking advantage of the geometric features in the real world. Rather than scanning for these coalescible voxels constantly at every iteration, our merging strategy accumulates voxels in a locality-sensitive hash and triggers merging lazily. On-demand merging not only reduces memory footprint with minimal computational overhead but also improves localization accuracy thanks to cross-voxel denoising. Experiments exhibit 20% higher accuracy, 20% faster performance and 70% lower memory consumption than the state-of-the-art.
6/4/2024
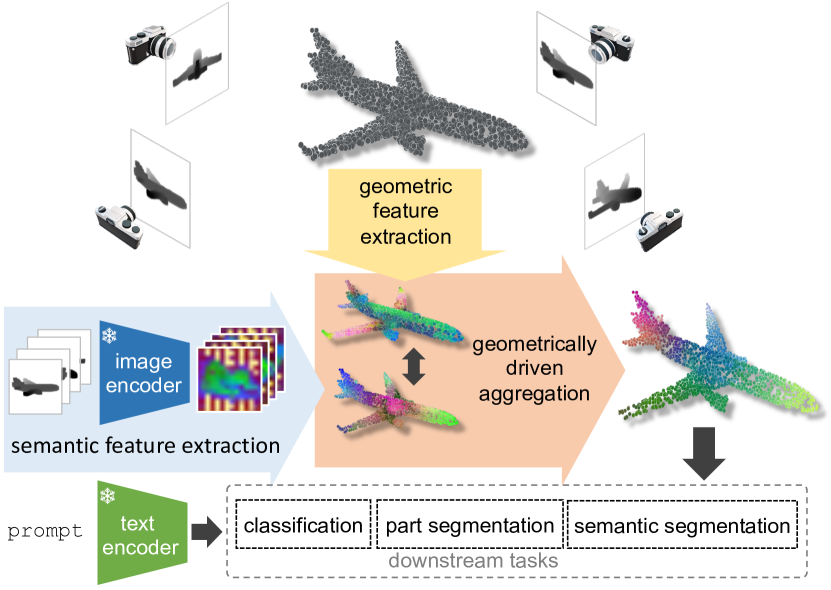
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
0
0
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
4/16/2024
✨
PV-SSD: A Multi-Modal Point Cloud Feature Fusion Method for Projection Features and Variable Receptive Field Voxel Features
Yongxin Shao, Aihong Tan, Zhetao Sun, Enhui Zheng, Tianhong Yan, Peng Liao
0
0
LiDAR-based 3D object detection and classification is crucial for autonomous driving. However, real-time inference from extremely sparse 3D data is a formidable challenge. To address this problem, a typical class of approaches transforms the point cloud cast into a regular data representation (voxels or projection maps). Then, it performs feature extraction with convolutional neural networks. However, such methods often result in a certain degree of information loss due to down-sampling or over-compression of feature information. This paper proposes a multi-modal point cloud feature fusion method for projection features and variable receptive field voxel features (PV-SSD) based on projection and variable voxelization to solve the information loss problem. We design a two-branch feature extraction structure with a 2D convolutional neural network to extract the point cloud's projection features in bird's-eye view to focus on the correlation between local features. A voxel feature extraction branch is used to extract local fine-grained features. Meanwhile, we propose a voxel feature extraction method with variable sensory fields to reduce the information loss of voxel branches due to downsampling. It avoids missing critical point information by selecting more useful feature points based on feature point weights for the detection task. In addition, we propose a multi-modal feature fusion module for point clouds. To validate the effectiveness of our method, we tested it on the KITTI dataset and ONCE dataset.
4/9/2024