DLO: Dynamic Layer Operation for Efficient Vertical Scaling of LLMs

0

Sign in to get full access
Overview
• This paper presents a novel technique called Dynamic Layer Operation (DLO) for efficiently scaling large language models (LLMs) by dynamically adjusting the number of active layers during inference.
• DLO aims to address the challenge of vertical scaling, where the model size and computational requirements grow rapidly as LLMs become larger.
• The key idea behind DLO is to selectively activate only the necessary layers of the LLM based on the input complexity, allowing for more efficient resource utilization and reduced computational costs.
Plain English Explanation
• Large language models (LLMs) have become increasingly powerful, but they also require a lot of computing power and memory to run. As these models get bigger, the computational requirements can become a significant challenge.
• The researchers in this paper developed a technique called Dynamic Layer Operation (DLO) to address this problem. The basic idea is to only use the layers of the model that are actually needed for a given input, rather than running the entire model every time.
• For example, if you're asking the model a simple question, you might only need the first few layers to generate a response. But if you're asking a more complex question, the model might need to activate more layers to fully understand the input and generate a high-quality output.
• By dynamically adjusting the number of active layers, DLO allows the model to operate more efficiently, using less computing power and memory than running the entire model every time. This can be especially useful for deploying LLMs in resource-constrained environments or for scaling up the size of LLMs without drastically increasing the computational requirements.
Technical Explanation
• The key innovation in this paper is the Dynamic Layer Operation (DLO) mechanism, which selectively activates the necessary layers of the LLM based on the input complexity.
• The authors propose a gating mechanism that determines how many layers should be active for a given input. This gating mechanism is trained alongside the main LLM model, allowing it to learn the optimal layer activation patterns for different types of inputs.
• The researchers evaluate DLO on several benchmark tasks, including language modeling and question answering. They show that DLO can achieve similar performance to a full LLM while using significantly fewer computational resources, particularly for less complex inputs.
• This work builds on previous research on dynamic layer activation and efficient scaling of large models, highlighting the potential for using simpler approaches to scale up language and vision models.
Critical Analysis
• One potential limitation of the DLO approach is that it may not be as effective for tasks that require a more holistic understanding of the input, where activating all layers of the LLM is essential for high performance.
• The authors acknowledge this and suggest that DLO could be combined with other techniques, such as layer-wise adaptive inference, to achieve even greater efficiency while maintaining model performance.
• Additionally, the gating mechanism used in DLO adds some computational overhead, which may offset the benefits of reduced layer activation in certain scenarios. The authors discuss ways to optimize the gating mechanism to further improve the efficiency gains.
• Overall, the DLO approach presents a promising direction for addressing the computational challenges of scaling up LLMs, but further research is needed to explore its limitations and potential improvements.
Conclusion
• The Dynamic Layer Operation (DLO) technique developed in this paper offers a novel way to efficiently scale large language models (LLMs) by dynamically adjusting the number of active layers during inference.
• By selectively activating only the necessary layers based on input complexity, DLO can achieve similar performance to a full LLM while using significantly fewer computational resources, making it a valuable tool for deploying LLMs in resource-constrained environments and scaling up model size without incurring prohibitive computational costs.
• While DLO has some limitations and areas for further optimization, this work highlights the potential for using simpler approaches to scale up language and vision models and opens up new research directions in efficient model scaling and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DLO: Dynamic Layer Operation for Efficient Vertical Scaling of LLMs
Zhen Tan, Daize Dong, Xinyu Zhao, Jie Peng, Yu Cheng, Tianlong Chen
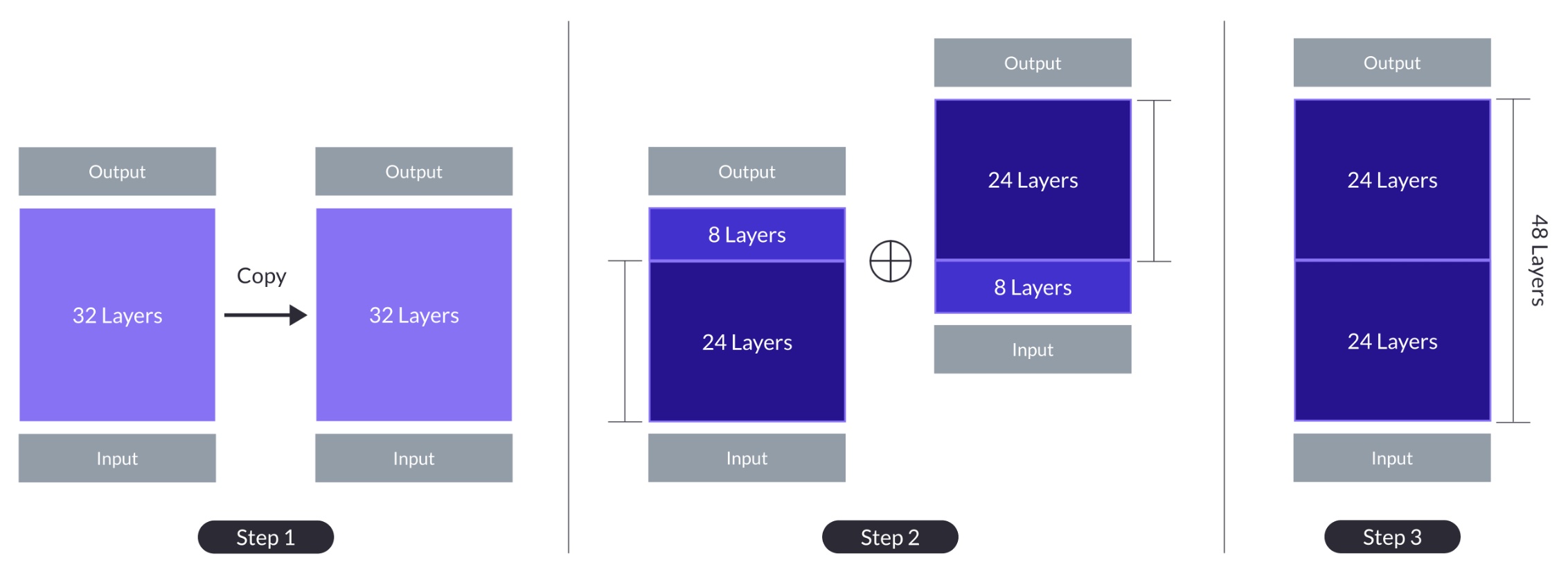
In this paper, we introduce Dynamic Layer Operations (DLO), a novel approach for vertically scaling transformer-based Large Language Models (LLMs) by dynamically expanding, activating, or skipping layers using a sophisticated routing policy based on layerwise feature similarity. Unlike traditional Mixture-of-Experts (MoE) methods that focus on extending the model width, our approach targets model depth, addressing the redundancy observed across layer representations for various input samples. Our framework is integrated with the Supervised Fine-Tuning (SFT) stage, eliminating the need for resource-intensive Continual Pre-Training (CPT). Experimental results demonstrate that DLO not only outperforms the original unscaled models but also achieves comparable results to densely expanded models with significantly improved efficiency. Our work offers a promising direction for building efficient yet powerful LLMs. We will release our implementation and model weights upon acceptance.
Read more7/17/2024
0
DLoRA: Distributed Parameter-Efficient Fine-Tuning Solution for Large Language Model
Chao Gao, Sai Qian Zhang
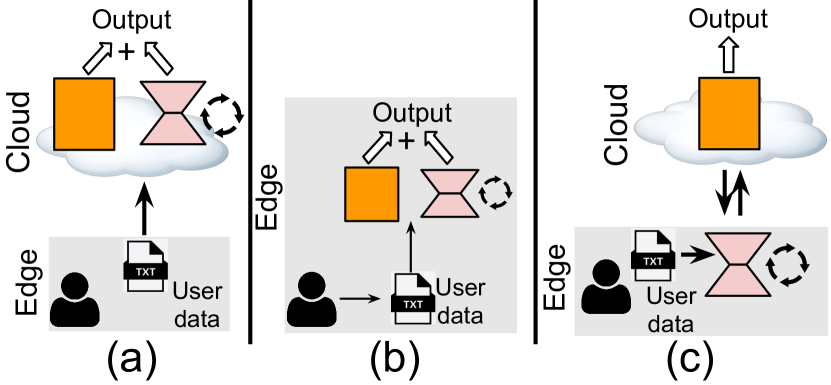
To enhance the performance of large language models (LLM) on downstream tasks, one solution is to fine-tune certain LLM parameters and make it better align with the characteristics of the training dataset. This process is commonly known as parameter-efficient fine-tuning (PEFT). Due to the scale of LLM, PEFT operations are usually executed in the public environment (e.g., cloud server). This necessitates the sharing of sensitive user data across public environments, thereby raising potential privacy concerns. To tackle these challenges, we propose a distributed PEFT framework called DLoRA. DLoRA enables scalable PEFT operations to be performed collaboratively between the cloud and user devices. Coupled with the proposed Kill and Revive algorithm, the evaluation results demonstrate that DLoRA can significantly reduce the computation and communication workload over the user devices while achieving superior accuracy and privacy protection.
Read more4/9/2024
16
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, Sunghun Kim
We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Read more4/5/2024

0
Dynamic Switch Layers For Unsupervised Learning
Haiguang Li, Usama Pervaiz, Micha{l} Matuszak, Robert Kamara, Gilles Roux, Trausti Thormundsson, Joseph Antognini
On-device machine learning (ODML) enables intelligent applications on resource-constrained devices. However, power consumption poses a major challenge, forcing a trade-off between model accuracy and power efficiency that often limits model complexity. The previously established Gated Compression (GC) layers offer a solution, enabling power efficiency without sacrificing model performance by selectively gating samples that lack signals of interest. However, their reliance on ground truth labels limits GC layers to supervised tasks. This work introduces the Dynamic Switch Layer (DSL), extending the benefits of GC layers to unsupervised learning scenarios, and maintaining power efficiency without the need for labeled data. The DSL builds upon the GC architecture, leveraging a dynamic pathway selection, and adapting model complexity in response to the innate structure of the data. We integrate the DSL into the SoundStream architecture and demonstrate that by routing up to 80% of samples through a lightweight pass we achieve a 12.3x reduction in the amount of computation performed and a 20.9x reduction in model size. This reduces the on-device inference latency by up to 26.5% and improves power efficiency by up to 21.4% without impacting model performance.
Read more4/9/2024