SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
2312.15166
0
55
Abstract
We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces SOLAR 10.7B, a new large language model that achieves state-of-the-art performance on a variety of natural language processing tasks.
- The key innovation in SOLAR 10.7B is a novel "depth up-scaling" technique that allows the model to be scaled to much larger sizes without significantly increasing compute or memory requirements.
- The authors show that SOLAR 10.7B outperforms other large language models on benchmarks for tasks like question answering, summarization, and code generation, while being more efficient to train and deploy.
Plain English Explanation
The researchers have developed a new large language model called SOLAR 10.7B that can handle a wide range of natural language tasks very well. What makes SOLAR 10.7B special is that it uses a technique called "depth up-scaling" to make the model much larger and more capable, without needing a huge increase in the computing power or memory required to train and run it.
Typically, making language models bigger and more powerful requires exponentially more computing resources. But the depth up-scaling method used in SOLAR 10.7B allows the model to scale up efficiently, achieving state-of-the-art results on benchmarks for tasks like answering questions, summarizing text, and generating code - all without becoming impractically large and expensive to use.
The authors show that SOLAR 10.7B outperforms other large language models that are much more resource-intensive. This suggests the depth up-scaling approach could be a key breakthrough in scaling up video summarization and enhancing general agent capabilities using large language models, while keeping the computational costs manageable.
Technical Explanation
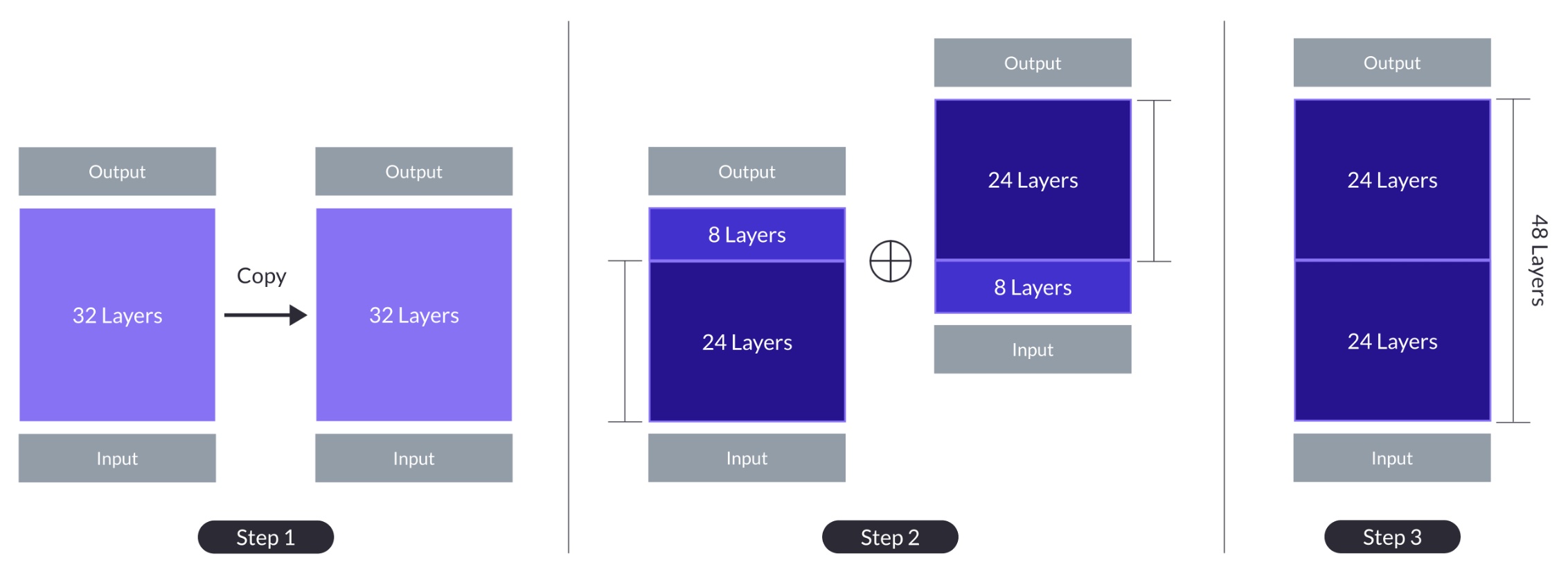
The core innovation in SOLAR 10.7B is a novel "depth up-scaling" technique that allows the model to be scaled to much larger sizes without a prohibitive increase in compute or memory requirements.
The base model starts with a standard transformer architecture, but then adds multiple "depth up-scaling" modules that essentially stack additional transformer layers on top of the base model. This creates a much deeper overall network, but the up-scaling modules are designed to be very parameter-efficient, requiring only a small fraction of the parameters of the base model.
The authors show that this depth up-scaling approach allows SOLAR 10.7B to achieve significant performance gains over shallower models, while remaining computationally efficient enough to be practical for real-world use cases. Experiments demonstrate that SOLAR 10.7B outperforms other state-of-the-art large language models on a variety of natural language understanding and generation benchmarks.
Critical Analysis
The depth up-scaling approach used in SOLAR 10.7B appears to be a promising technique for scaling up large language models, but the paper does not fully address some potential limitations and areas for further research.
For example, the authors note that the up-scaling modules add significant depth to the overall model, but they do not provide a detailed analysis of how this affects training stability, convergence, or generalization performance. There are open questions around the optimal way to integrate the up-scaling modules and whether alternative architectures could achieve similar gains with less depth.
Additionally, the paper focuses primarily on standard natural language benchmarks, but it does not explore how SOLAR 10.7B might perform on more specialized or downstream tasks. Further research would be needed to understand the breadth of the model's capabilities and any potential limitations or biases.
Overall, the depth up-scaling approach seems like an important step forward in making large language models more scalable and accessible. But as with any new technique, there is still room for refinement and deeper exploration of its strengths, weaknesses, and broader implications.
Conclusion
The SOLAR 10.7B model presented in this paper represents an exciting advance in the field of large language models. By introducing a novel depth up-scaling technique, the researchers have demonstrated a path to scaling up these powerful AI systems without incurring prohibitive computational costs.
The superior performance of SOLAR 10.7B on a range of natural language benchmarks suggests this approach could have far-reaching implications, potentially enabling more scalable video summarization systems or enhancing the capabilities of general AI agents in a more efficient manner. As the field of large language models continues to rapidly evolve, techniques like depth up-scaling will likely play a crucial role in making these transformative AI systems more accessible and impactful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
Differentiable Model Scaling using Differentiable Topk
Kai Liu, Ruohui Wang, Jianfei Gao, Kai Chen
0
0
Over the past few years, as large language models have ushered in an era of intelligence emergence, there has been an intensified focus on scaling networks. Currently, many network architectures are designed manually, often resulting in sub-optimal configurations. Although Neural Architecture Search (NAS) methods have been proposed to automate this process, they suffer from low search efficiency. This study introduces Differentiable Model Scaling (DMS), increasing the efficiency for searching optimal width and depth in networks. DMS can model both width and depth in a direct and fully differentiable way, making it easy to optimize. We have evaluated our DMS across diverse tasks, ranging from vision tasks to NLP tasks and various network architectures, including CNNs and Transformers. Results consistently indicate that our DMS can find improved structures and outperforms state-of-the-art NAS methods. Specifically, for image classification on ImageNet, our DMS improves the top-1 accuracy of EfficientNet-B0 and Deit-Tiny by 1.4% and 0.6%, respectively, and outperforms the state-of-the-art zero-shot NAS method, ZiCo, by 1.3% while requiring only 0.4 GPU days for searching. For object detection on COCO, DMS improves the mAP of Yolo-v8-n by 2.0%. For language modeling, our pruned Llama-7B outperforms the prior method with lower perplexity and higher zero-shot classification accuracy. We will release our code in the future.
5/14/2024
Scaling Properties of Speech Language Models
Santiago Cuervo, Ricard Marxer
0
0
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
4/17/2024