A Single Transformer for Scalable Vision-Language Modeling

0

Sign in to get full access
Overview
- This paper introduces a novel approach to building scalable vision-language models using a single Transformer architecture.
- The researchers address the limitations of existing vision-language models, which often require complex, multi-stage pipelines that constrain scalability.
- The proposed model, called VITAMIN-L, aims to overcome these challenges by integrating computer vision and natural language processing into a unified Transformer-based framework.
Plain English Explanation
The paper presents a new way to create powerful models that can understand and work with both images and text using a single neural network architecture. Existing vision-language models often rely on complex, multi-step processes that make them difficult to scale up and apply to larger datasets or more complex tasks.
The researchers introduce VITAMIN-L, a Transformer-based model that combines computer vision and natural language processing into a single, integrated system. By using a single model, the researchers aim to address the scalability limitations of previous approaches and enable more efficient and effective vision-language capabilities.
The key idea is to leverage the strengths of Transformer architectures, which have been successful in both language and vision tasks, to build a versatile and scalable model that can handle a wide range of vision-language challenges. This approach could lead to more powerful and flexible AI systems that can seamlessly integrate and reason about visual and textual information.
Technical Explanation
The paper introduces VITAMIN-L, a Transformer-based architecture that aims to overcome the scalability limitations of existing vision-language models. The researchers argue that most current approaches rely on complex, multi-stage pipelines that constrain their ability to scale and adapt to new tasks and datasets.
To address this, the researchers propose a unified Transformer-based model that can jointly process and reason about visual and textual inputs. The model consists of a shared Transformer backbone that operates on a common representation space, allowing it to efficiently leverage information from both modalities.
The authors conduct extensive experiments to evaluate the performance of VITAMIN-L on a range of vision-language tasks, including image-text retrieval, visual question answering, and visual reasoning. The results demonstrate the model's strong performance and ability to scale to larger datasets and more complex challenges compared to previous approaches.
The paper also provides insights into the key factors that contribute to the success of VITAMIN-L, such as the importance of joint training, the benefits of a shared Transformer backbone, and the impact of different input representations and pretraining strategies.
Critical Analysis
The paper presents a compelling approach to building scalable and versatile vision-language models using a single Transformer-based architecture. The researchers make a strong case for the limitations of existing multi-stage pipelines and the potential advantages of a more integrated, end-to-end approach.
However, the paper does not extensively address potential downsides or limitations of the VITAMIN-L model. For example, the authors do not discuss the computational and memory requirements of the model, which could be a concern when scaling to larger datasets or more complex tasks.
Additionally, the paper does not explore the interpretability or explainability of the VITAMIN-L model, which is an important consideration for many real-world applications. The ability to understand and explain the model's decision-making process could be crucial for building trust and ensuring responsible deployment.
Further research could also investigate the generalization capabilities of the VITAMIN-L model, such as its performance on out-of-distribution or multimodal tasks that go beyond the specific benchmarks considered in this paper. Exploring the model's robustness and adaptability to diverse data and challenges would be valuable for assessing its practical utility.
Conclusion
This paper presents a novel approach to building scalable and versatile vision-language models using a single Transformer-based architecture. The proposed VITAMIN-L model addresses the limitations of existing multi-stage pipelines by integrating computer vision and natural language processing into a unified framework.
The results demonstrate the strong performance of VITAMIN-L on a range of vision-language tasks, suggesting that this approach could lead to more efficient and effective AI systems that can seamlessly work with both visual and textual information. The insights provided in the paper also contribute to our understanding of the key factors that enable successful vision-language modeling.
While the paper does not extensively explore certain limitations or potential issues, the proposed VITAMIN-L model represents an important step forward in the pursuit of scalable and versatile vision-language capabilities, with implications for a wide range of applications in artificial intelligence and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Single Transformer for Scalable Vision-Language Modeling
Yangyi Chen, Xingyao Wang, Hao Peng, Heng Ji
We present SOLO, a single transformer for Scalable visiOn-Language mOdeling. Current large vision-language models (LVLMs) such as LLaVA mostly employ heterogeneous architectures that connect pre-trained visual encoders with large language models (LLMs) to facilitate visual recognition and complex reasoning. Although achieving remarkable performance with relatively lightweight training, we identify four primary scalability limitations: (1) The visual capacity is constrained by pre-trained visual encoders, which are typically an order of magnitude smaller than LLMs. (2) The heterogeneous architecture complicates the use of established hardware and software infrastructure. (3) Study of scaling laws on such architecture must consider three separate components - visual encoder, connector, and LLMs, which complicates the analysis. (4) The use of existing visual encoders typically requires following a pre-defined specification of image inputs pre-processing, for example, by reshaping inputs to fixed-resolution square images, which presents difficulties in processing and training on high-resolution images or those with unusual aspect ratio. A unified single Transformer architecture, like SOLO, effectively addresses these scalability concerns in LVLMs; however, its limited adoption in the modern context likely stems from the absence of reliable training recipes that balance both modalities and ensure stable training for billion-scale models. In this paper, we introduce the first open-source training recipe for developing SOLO, an open-source 7B LVLM using moderate academic resources. The training recipe involves initializing from LLMs, sequential pre-training on ImageNet and web-scale data, and instruction fine-tuning on our curated high-quality datasets. On extensive evaluation, SOLO demonstrates performance comparable to LLaVA-v1.5-7B, particularly excelling in visual mathematical reasoning.
Read more7/10/2024
0
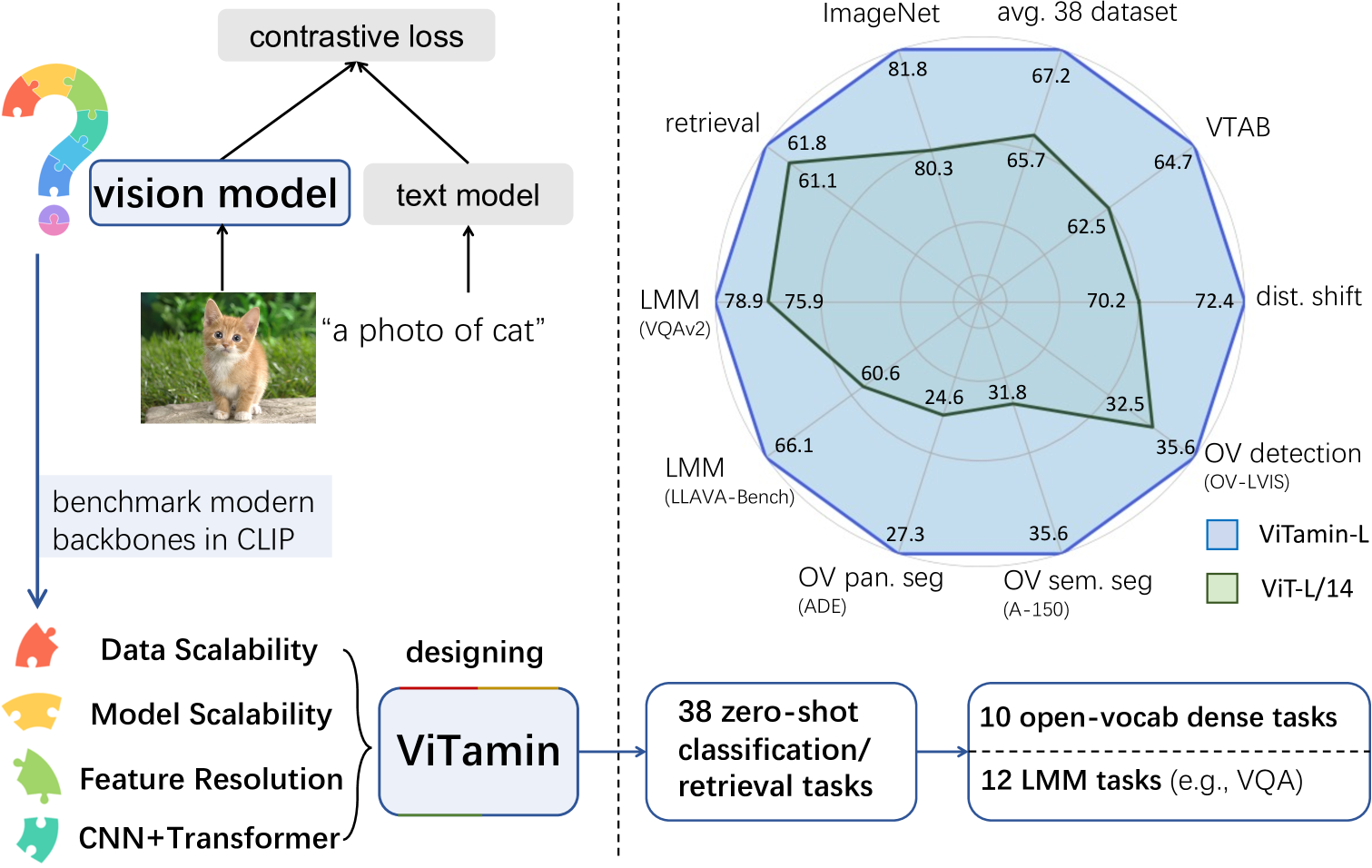
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
Read more4/5/2024

0
Are Bigger Encoders Always Better in Vision Large Models?
Bozhou Li, Hao Liang, Zimo Meng, Wentao Zhang
In recent years, multimodal large language models (MLLMs) have shown strong potential in real-world applications. They are developing rapidly due to their remarkable ability to comprehend multimodal information and their inherent powerful cognitive and reasoning capabilities. Among MLLMs, vision language models (VLM) stand out for their ability to understand vision information. However, the scaling trend of VLMs under the current mainstream paradigm has not been extensively studied. Whether we can achieve better performance by training even larger models is still unclear. To address this issue, we conducted experiments on the pretraining stage of MLLMs. We conduct our experiment using different encoder sizes and large language model (LLM) sizes. Our findings indicate that merely increasing the size of encoders does not necessarily enhance the performance of VLMs. Moreover, we analyzed the effects of LLM backbone parameter size and data quality on the pretraining outcomes. Additionally, we explored the differences in scaling laws between LLMs and VLMs.
Read more8/2/2024
0
HSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Shuyi Ouyang, Hongyi Wang, Ziwei Niu, Zhenjia Bai, Shiao Xie, Yingying Xu, Ruofeng Tong, Yen-Wei Chen, Lanfen Lin
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.
Read more7/24/2024