TroL: Traversal of Layers for Large Language and Vision Models

0
Sign in to get full access
Overview
- This paper introduces TroL, a novel traversal technique for efficiently accessing different layers of large language and vision models.
- TroL aims to improve the inference efficiency of these models by enabling selective access to specific layers, reducing the computational cost and memory footprint.
- The paper explores the use of TroL with various large-scale models, including SOLAR-107B, Collavo, and VisionLLM v2.
Plain English Explanation
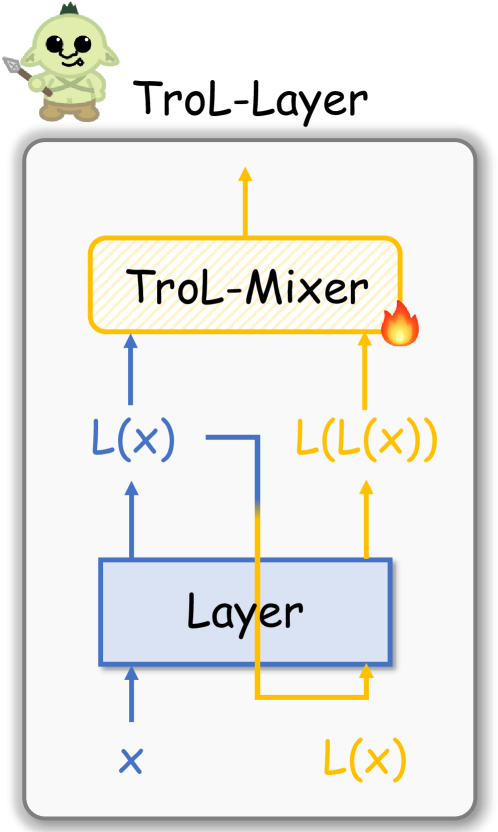
The paper discusses a new technique called TroL, which stands for "Traversal of Layers." This technique is designed to help improve the efficiency of large language and vision models, which are complex AI systems that can perform tasks like text generation, image recognition, and multimodal reasoning.
The key idea behind TroL is that these large models have many different layers, each with its own specialized function. Rather than always running the entire model from start to finish, TroL allows you to selectively access and use only the specific layers you need for a particular task. This can save a lot of time and computing power, making the models more efficient to use.
The paper shows how TroL can be applied to several different large-scale models, including SOLAR-107B, Collavo, and VisionLLM v2. The experiments show that TroL can significantly improve the inference speed and memory usage of these models, without significantly impacting their performance on key tasks.
Technical Explanation
The paper introduces a novel traversal technique called TroL (Traversal of Layers) that enables efficient access to different layers of large language and vision models. The key idea behind TroL is to selectively activate only the necessary layers of a model, rather than running the entire model from start to finish, which can be computationally expensive and memory-intensive.
The authors explore the use of TroL with several state-of-the-art large-scale models, including SOLAR-107B, Collavo, and VisionLLM v2. Through extensive experiments, the authors demonstrate that TroL can significantly improve the inference efficiency of these models, reducing their computational cost and memory footprint without significantly impacting their performance on various tasks.
The paper also investigates the effects of different traversal strategies and the relationship between model size and traversal efficiency, providing valuable insights into the design and optimization of large language and vision models.
Critical Analysis
The paper presents a promising approach to improving the efficiency of large language and vision models, but it also acknowledges several limitations and areas for further research. For example, the authors note that the effectiveness of TroL may depend on the specific model architecture and the task at hand, and they encourage further exploration of the trade-offs between inference efficiency and model performance.
Additionally, while the paper demonstrates the benefits of TroL on several large-scale models, it would be valuable to see how the technique performs on an even broader range of models and tasks, including real-world applications. Further research could also investigate the interpretability and explainability of the TroL approach, which could be important for building trust and understanding in these complex AI systems.
Overall, the paper introduces an interesting and potentially impactful technique for enhancing the efficiency of large language and vision models, and it lays the groundwork for further advancements in this area of research.
Conclusion
The TroL paper presents a novel traversal technique that enables efficient access to different layers of large language and vision models. By selectively activating only the necessary layers, TroL can significantly improve the inference speed and memory usage of these complex AI systems without significantly impacting their performance.
The authors demonstrate the effectiveness of TroL on several state-of-the-art models, including SOLAR-107B, Collavo, and VisionLLM v2. This work has the potential to unlock new applications and use cases for large language and vision models by making them more efficient and accessible, ultimately contributing to the advancement of the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TroL: Traversal of Layers for Large Language and Vision Models
Byung-Kwan Lee, Sangyun Chung, Chae Won Kim, Beomchan Park, Yong Man Ro
Large language and vision models (LLVMs) have been driven by the generalization power of large language models (LLMs) and the advent of visual instruction tuning. Along with scaling them up directly, these models enable LLVMs to showcase powerful vision language (VL) performances by covering diverse tasks via natural language instructions. However, existing open-source LLVMs that perform comparably to closed-source LLVMs such as GPT-4V are often considered too large (e.g., 26B, 34B, and 110B parameters), having a larger number of layers. These large models demand costly, high-end resources for both training and inference. To address this issue, we present a new efficient LLVM family with 1.8B, 3.8B, and 7B LLM model sizes, Traversal of Layers (TroL), which enables the reuse of layers in a token-wise manner. This layer traversing technique simulates the effect of looking back and retracing the answering stream while increasing the number of forward propagation layers without physically adding more layers. We demonstrate that TroL employs a simple layer traversing approach yet efficiently outperforms the open-source LLVMs with larger model sizes and rivals the performances of the closed-source LLVMs with substantial sizes.
Read more6/21/2024

0
DLO: Dynamic Layer Operation for Efficient Vertical Scaling of LLMs
Zhen Tan, Daize Dong, Xinyu Zhao, Jie Peng, Yu Cheng, Tianlong Chen
In this paper, we introduce Dynamic Layer Operations (DLO), a novel approach for vertically scaling transformer-based Large Language Models (LLMs) by dynamically expanding, activating, or skipping layers using a sophisticated routing policy based on layerwise feature similarity. Unlike traditional Mixture-of-Experts (MoE) methods that focus on extending the model width, our approach targets model depth, addressing the redundancy observed across layer representations for various input samples. Our framework is integrated with the Supervised Fine-Tuning (SFT) stage, eliminating the need for resource-intensive Continual Pre-Training (CPT). Experimental results demonstrate that DLO not only outperforms the original unscaled models but also achieves comparable results to densely expanded models with significantly improved efficiency. Our work offers a promising direction for building efficient yet powerful LLMs. We will release our implementation and model weights upon acceptance.
Read more7/17/2024

0
A Single Transformer for Scalable Vision-Language Modeling
Yangyi Chen, Xingyao Wang, Hao Peng, Heng Ji
We present SOLO, a single transformer for Scalable visiOn-Language mOdeling. Current large vision-language models (LVLMs) such as LLaVA mostly employ heterogeneous architectures that connect pre-trained visual encoders with large language models (LLMs) to facilitate visual recognition and complex reasoning. Although achieving remarkable performance with relatively lightweight training, we identify four primary scalability limitations: (1) The visual capacity is constrained by pre-trained visual encoders, which are typically an order of magnitude smaller than LLMs. (2) The heterogeneous architecture complicates the use of established hardware and software infrastructure. (3) Study of scaling laws on such architecture must consider three separate components - visual encoder, connector, and LLMs, which complicates the analysis. (4) The use of existing visual encoders typically requires following a pre-defined specification of image inputs pre-processing, for example, by reshaping inputs to fixed-resolution square images, which presents difficulties in processing and training on high-resolution images or those with unusual aspect ratio. A unified single Transformer architecture, like SOLO, effectively addresses these scalability concerns in LVLMs; however, its limited adoption in the modern context likely stems from the absence of reliable training recipes that balance both modalities and ensure stable training for billion-scale models. In this paper, we introduce the first open-source training recipe for developing SOLO, an open-source 7B LVLM using moderate academic resources. The training recipe involves initializing from LLMs, sequential pre-training on ImageNet and web-scale data, and instruction fine-tuning on our curated high-quality datasets. On extensive evaluation, SOLO demonstrates performance comparable to LLaVA-v1.5-7B, particularly excelling in visual mathematical reasoning.
Read more7/10/2024

0
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
Byung-Kwan Lee, Chae Won Kim, Beomchan Park, Yong Man Ro
The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs. These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions. Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities. To embed lengthy rationales containing abundant information, we employ the Mamba architecture, capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale. Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.
Read more5/28/2024