DMTG: One-Shot Differentiable Multi-Task Grouping

0

Sign in to get full access
Overview
- This paper introduces a new method called DMTG (One-Shot Differentiable Multi-Task Grouping) that aims to improve the efficiency and flexibility of multi-task learning.
- The key idea is to automatically group related tasks together in a differentiable way, allowing the model to learn shared representations and efficiently leverage cross-task knowledge.
- The proposed DMTG approach is designed to be "one-shot", meaning it can group tasks on-the-fly without requiring pre-training or additional optimization steps.
Plain English Explanation
When working on multiple related tasks, such as image recognition, text summarization, and language translation, it can be beneficial to share knowledge and learn common underlying representations. Multi-task learning is a machine learning technique that tries to do this, but it can be challenging to determine which tasks should be grouped together.
The DMTG method presented in this paper aims to automatically figure out how to group related tasks in a way that improves overall performance. Imagine you have a toolbox with different tools (tasks), and you want to organize them in a way that makes it easy to find the ones you need. DMTG is like a smart algorithm that can automatically sort the tools into drawers (task groups) based on how they are used together, without you having to manually decide how to organize everything.
This "one-shot" capability means DMTG can group tasks on the fly, without requiring a lot of pre-training or extra optimization steps. The key innovation is that DMTG uses a differentiable approach, which allows the grouping process to be seamlessly integrated into the overall model training. This makes the whole system more efficient and flexible compared to previous multi-task learning methods.
Technical Explanation
The DMTG method introduced in this paper works by learning a set of "group embeddings" that represent different task groupings. These embeddings are then used to weight the contributions of each task during training, allowing the model to automatically discover the optimal task groupings.
The DMTG architecture consists of a shared backbone network, task-specific heads, and a differentiable grouping module. The grouping module takes the task-specific features as input and outputs a set of group assignment probabilities, which are used to compute a weighted average of the task-specific outputs.
This approach has several advantages over previous multi-task learning methods:
- Flexibility: DMTG can dynamically adapt the task groupings during training, unlike static task groupings used in many existing approaches.
- Efficiency: The one-shot nature of DMTG avoids the need for expensive pre-training or iterative optimization of task groupings.
- Scalability: DMTG can handle a large number of tasks, as the grouping module scales linearly with the number of tasks.
The authors evaluate DMTG on a range of multi-task learning benchmarks, including computer vision and natural language processing tasks. The results show that DMTG can outperform both single-task learning and previous multi-task learning methods, demonstrating the benefits of its automated and differentiable task grouping approach.
Critical Analysis
The DMTG paper makes a valuable contribution to the field of multi-task learning by introducing a novel and flexible approach for task grouping. However, there are a few potential limitations and areas for further research:
-
Task Heterogeneity: The paper focuses on homogeneous task settings, where all tasks are of the same type (e.g., all classification tasks). It would be interesting to see how DMTG performs on more heterogeneous task mixtures, such as combining vision, language, and structured prediction tasks.
-
Interpretability: While the automated task grouping is a key advantage of DMTG, the learned groupings may not be easily interpretable. Providing more insights into the grouping process and the relationships between tasks could enhance the practical usability of the method.
-
Scalability Limits: The authors note that the DMTG grouping module scales linearly with the number of tasks, but there may be practical limits to the number of tasks that can be effectively handled, especially as task complexity increases. Exploring ways to further improve the scalability would be a valuable direction for future research.
-
Task Dependencies: The current DMTG formulation assumes that tasks are independent and can be grouped freely. However, in some real-world scenarios, there may be inherent dependencies or constraints between tasks that should be considered during the grouping process.
Despite these potential areas for improvement, the DMTG method represents an important step forward in the field of multi-task learning, demonstrating the benefits of automated and differentiable task grouping. As the complexity and scale of machine learning applications continue to grow, techniques like DMTG will likely play an increasingly important role in enabling efficient and flexible multi-task learning systems.
Conclusion
The DMTG paper presents a novel approach for multi-task learning that automatically groups related tasks in a differentiable and efficient manner. By learning task groupings on-the-fly, DMTG can effectively leverage cross-task knowledge and improve overall performance, without the need for expensive pre-training or iterative optimization steps.
The promising results on various benchmarks suggest that DMTG could be a valuable tool for building more scalable and flexible multi-task learning systems, which are increasingly important in the era of growing machine learning complexity and diverse application domains. While the method has some potential limitations, the core ideas and innovations introduced in this paper represent an important contribution to the field of multi-task learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DMTG: One-Shot Differentiable Multi-Task Grouping
Yuan Gao, Shuguo Jiang, Moran Li, Jin-Gang Yu, Gui-Song Xia
We aim to address Multi-Task Learning (MTL) with a large number of tasks by Multi-Task Grouping (MTG). Given N tasks, we propose to simultaneously identify the best task groups from 2^N candidates and train the model weights simultaneously in one-shot, with the high-order task-affinity fully exploited. This is distinct from the pioneering methods which sequentially identify the groups and train the model weights, where the group identification often relies on heuristics. As a result, our method not only improves the training efficiency, but also mitigates the objective bias introduced by the sequential procedures that potentially lead to a suboptimal solution. Specifically, we formulate MTG as a fully differentiable pruning problem on an adaptive network architecture determined by an underlying Categorical distribution. To categorize N tasks into K groups (represented by K encoder branches), we initially set up KN task heads, where each branch connects to all N task heads to exploit the high-order task-affinity. Then, we gradually prune the KN heads down to N by learning a relaxed differentiable Categorical distribution, ensuring that each task is exclusively and uniquely categorized into only one branch. Extensive experiments on CelebA and Taskonomy datasets with detailed ablations show the promising performance and efficiency of our method. The codes are available at https://github.com/ethanygao/DMTG.
Read more7/9/2024
0
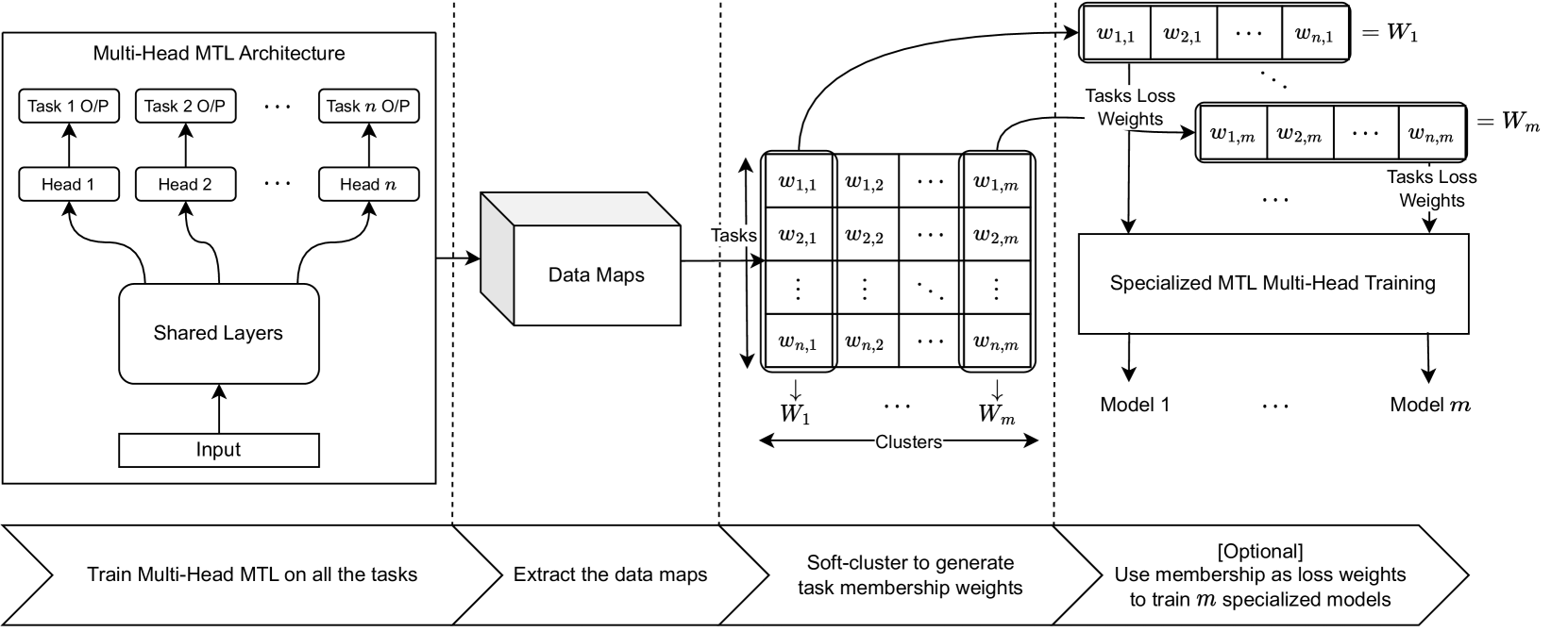
STG-MTL: Scalable Task Grouping for Multi-Task Learning Using Data Map
Ammar Sherif, Abubakar Abid, Mustafa Elattar, Mohamed ElHelw
Multi-Task Learning (MTL) is a powerful technique that has gained popularity due to its performance improvement over traditional Single-Task Learning (STL). However, MTL is often challenging because there is an exponential number of possible task groupings, which can make it difficult to choose the best one because some groupings might produce performance degradation due to negative interference between tasks. That is why existing solutions are severely suffering from scalability issues, limiting any practical application. In our paper, we propose a new data-driven method that addresses these challenges and provides a scalable and modular solution for classification task grouping based on a re-proposed data-driven features, Data Maps, which capture the training dynamics for each classification task during the MTL training. Through a theoretical comparison with other techniques, we manage to show that our approach has the superior scalability. Our experiments show a better performance and verify the method's effectiveness, even on an unprecedented number of tasks (up to 100 tasks on CIFAR100). Being the first to work on such number of tasks, our comparisons on the resulting grouping shows similar grouping to the mentioned in the dataset, CIFAR100. Finally, we provide a modular implementation for easier integration and testing, with examples from multiple datasets and tasks.
Read more5/28/2024
0
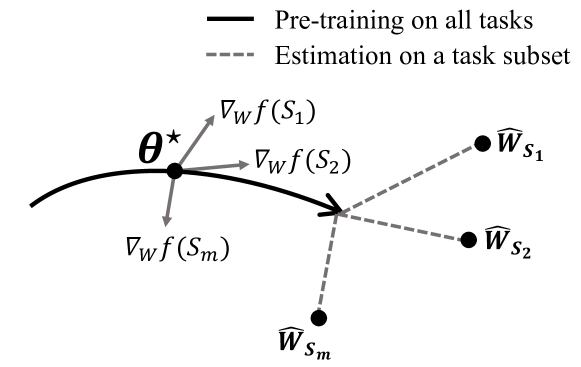
Scalable Multitask Learning Using Gradient-based Estimation of Task Affinity
Dongyue Li, Aneesh Sharma, Hongyang R. Zhang
Multitask learning is a widely used paradigm for training models on diverse tasks, with applications ranging from graph neural networks to language model fine-tuning. Since tasks may interfere with each other, a key notion for modeling their relationships is task affinity. This includes pairwise task affinity, computed among pairs of tasks, and higher-order affinity, computed among subsets of tasks. Naively computing either of them requires repeatedly training on data from various task combinations, which is computationally intensive. We present a new algorithm Grad-TAG that can estimate task affinities without this repeated training. The key idea of Grad-TAG is to train a base model for all tasks and then use a linearization technique to estimate the loss of the model for a specific task combination. The linearization works by computing a gradient-based approximation of the loss, using low-dimensional projections of gradients as features in a logistic regression to predict labels for the task combination. We show that the linearized model can provably approximate the loss when the gradient-based approximation is accurate, and also empirically verify that on several large models. Then, given the estimated task affinity, we design a semi-definite program for clustering similar tasks by maximizing the average density of clusters. We evaluate Grad-TAG's performance across seven datasets, including multi-label classification on graphs, and instruction fine-tuning of language models. Our task affinity estimates are within 2.7% distance to the true affinities while needing only 3% of FLOPs in full training. On our largest graph with 21M edges and 500 labeling tasks, our algorithm delivers estimates within 5% distance to the true affinities, using only 112 GPU hours. Our results show that Grad-TAG achieves excellent performance and runtime tradeoffs compared to existing approaches.
Read more9/11/2024
0
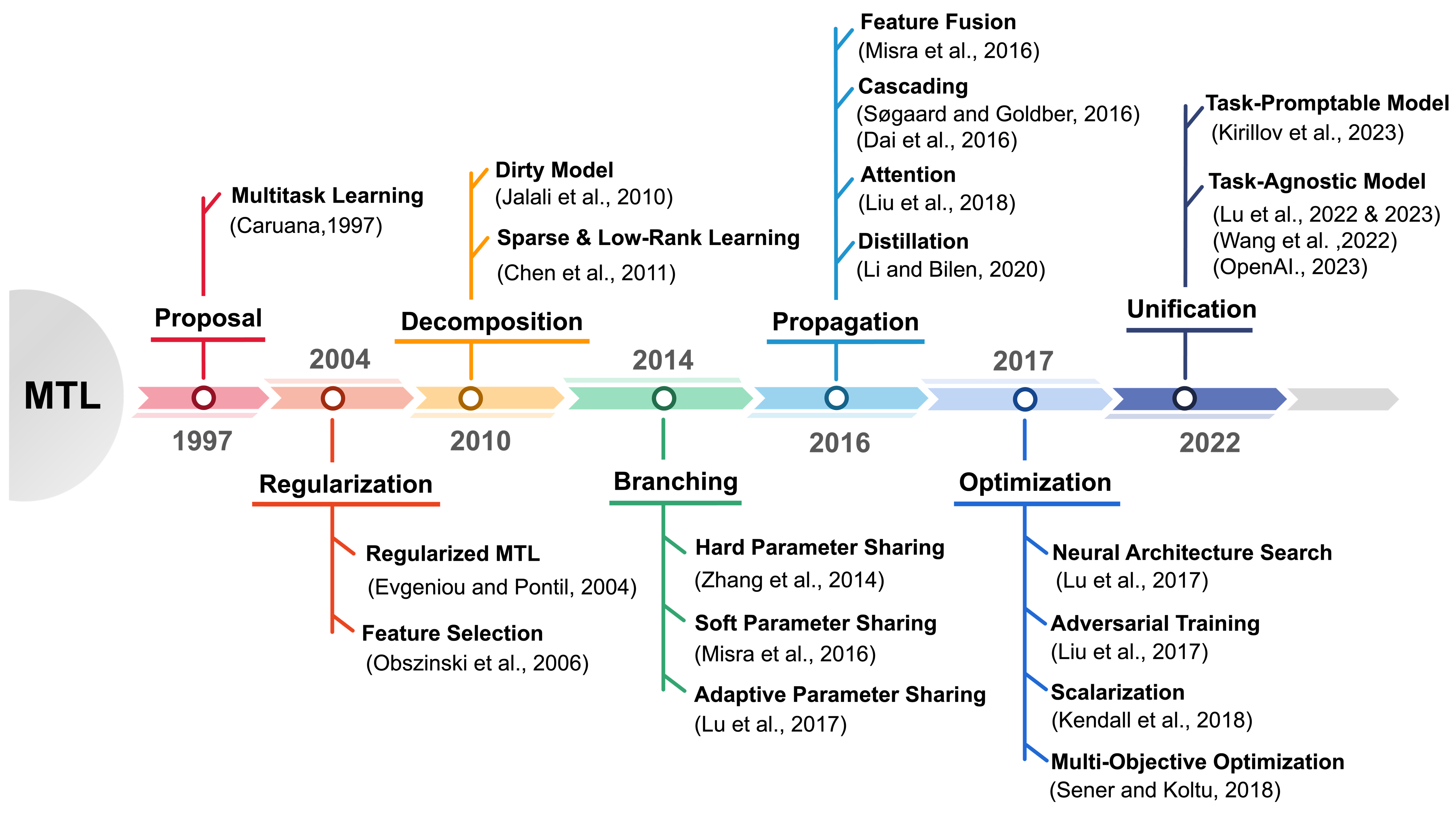
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Read more5/1/2024