Scalable Multitask Learning Using Gradient-based Estimation of Task Affinity

0
Sign in to get full access
Overview
- The paper proposes a scalable multitask learning approach that uses gradient-based estimation of task affinity.
- It aims to overcome the limitations of existing multitask learning methods by automatically discovering task relationships and grouping related tasks.
- The method is designed to be efficient and scalable, making it suitable for real-world applications with a large number of tasks.
Plain English Explanation
The paper presents a new way to tackle the problem of multitask learning. Multitask learning is when a machine learning model is trained to perform multiple related tasks simultaneously, rather than just one.
The key idea is to estimate the affinity between tasks - how closely related the tasks are to each other. This is done by looking at the gradients, or the direction of change, in the model's parameters as it learns each task.
By understanding the relationships between tasks, the model can group related tasks together and learn them more efficiently. This is important because real-world applications often involve a large number of tasks, and traditional multitask learning methods can become inefficient and difficult to scale.
The proposed approach is designed to be scalable and efficient, making it suitable for practical applications with many tasks. It can automatically discover the relationships between tasks and group them accordingly, without requiring manual task grouping or extensive hyperparameter tuning.
Technical Explanation
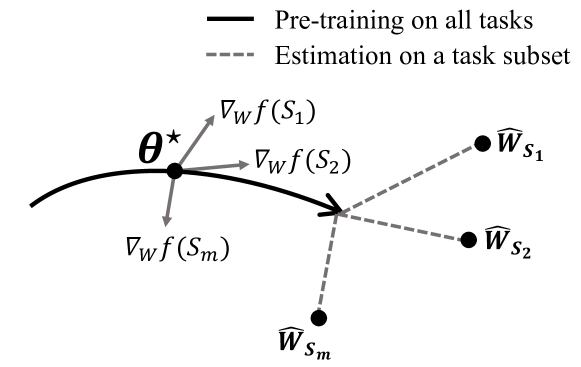
The paper introduces a scalable multitask learning approach that uses gradient-based estimation of task affinity. The core idea is to leverage the gradients of the model parameters with respect to each task to estimate the affinity between tasks.
The method consists of three main steps:
- Task Affinity Estimation: The model calculates the gradient similarity between tasks, which serves as a proxy for task affinity.
- Task Grouping: The tasks are then automatically grouped based on their affinities, allowing the model to learn related tasks more efficiently.
- Multitask Learning: The model is trained on the grouped tasks using a gradient-based optimization procedure.
The paper provides theoretical analysis and extensive experiments to demonstrate the effectiveness and scalability of the proposed approach, as well as its ability to outperform existing multitask learning methods.
Critical Analysis
The paper presents a novel and promising approach to multitask learning. The gradient-based task affinity estimation is a clever idea that allows the model to automatically discover task relationships without the need for manual task grouping or extensive hyperparameter tuning.
However, the paper does not address potential limitations or caveats of the proposed method. For example, it is unclear how the method would perform in scenarios with conflicting or unrelated tasks, which could pose challenges for the task grouping process.
Additionally, the paper does not discuss potential real-world applications or the practical implications of the proposed approach. Further research could explore the suitability of this method for specific domains and use cases.
Conclusion
The paper presents a scalable multitask learning approach that uses gradient-based estimation of task affinity to automatically discover and group related tasks. This allows the model to learn multiple tasks efficiently, making it suitable for real-world applications with a large number of tasks.
While the paper provides a solid technical foundation and promising experimental results, further research is needed to address potential limitations and explore the practical implications of this approach. Overall, the proposed method represents an interesting and scalable contribution to the field of multitask learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scalable Multitask Learning Using Gradient-based Estimation of Task Affinity
Dongyue Li, Aneesh Sharma, Hongyang R. Zhang
Multitask learning is a widely used paradigm for training models on diverse tasks, with applications ranging from graph neural networks to language model fine-tuning. Since tasks may interfere with each other, a key notion for modeling their relationships is task affinity. This includes pairwise task affinity, computed among pairs of tasks, and higher-order affinity, computed among subsets of tasks. Naively computing either of them requires repeatedly training on data from various task combinations, which is computationally intensive. We present a new algorithm Grad-TAG that can estimate task affinities without this repeated training. The key idea of Grad-TAG is to train a base model for all tasks and then use a linearization technique to estimate the loss of the model for a specific task combination. The linearization works by computing a gradient-based approximation of the loss, using low-dimensional projections of gradients as features in a logistic regression to predict labels for the task combination. We show that the linearized model can provably approximate the loss when the gradient-based approximation is accurate, and also empirically verify that on several large models. Then, given the estimated task affinity, we design a semi-definite program for clustering similar tasks by maximizing the average density of clusters. We evaluate Grad-TAG's performance across seven datasets, including multi-label classification on graphs, and instruction fine-tuning of language models. Our task affinity estimates are within 2.7% distance to the true affinities while needing only 3% of FLOPs in full training. On our largest graph with 21M edges and 500 labeling tasks, our algorithm delivers estimates within 5% distance to the true affinities, using only 112 GPU hours. Our results show that Grad-TAG achieves excellent performance and runtime tradeoffs compared to existing approaches.
Read more9/11/2024

0
DMTG: One-Shot Differentiable Multi-Task Grouping
Yuan Gao, Shuguo Jiang, Moran Li, Jin-Gang Yu, Gui-Song Xia
We aim to address Multi-Task Learning (MTL) with a large number of tasks by Multi-Task Grouping (MTG). Given N tasks, we propose to simultaneously identify the best task groups from 2^N candidates and train the model weights simultaneously in one-shot, with the high-order task-affinity fully exploited. This is distinct from the pioneering methods which sequentially identify the groups and train the model weights, where the group identification often relies on heuristics. As a result, our method not only improves the training efficiency, but also mitigates the objective bias introduced by the sequential procedures that potentially lead to a suboptimal solution. Specifically, we formulate MTG as a fully differentiable pruning problem on an adaptive network architecture determined by an underlying Categorical distribution. To categorize N tasks into K groups (represented by K encoder branches), we initially set up KN task heads, where each branch connects to all N task heads to exploit the high-order task-affinity. Then, we gradually prune the KN heads down to N by learning a relaxed differentiable Categorical distribution, ensuring that each task is exclusively and uniquely categorized into only one branch. Extensive experiments on CelebA and Taskonomy datasets with detailed ablations show the promising performance and efficiency of our method. The codes are available at https://github.com/ethanygao/DMTG.
Read more7/9/2024
🏷️
0
Bayesian Uncertainty for Gradient Aggregation in Multi-Task Learning
Idan Achituve, Idit Diamant, Arnon Netzer, Gal Chechik, Ethan Fetaya
As machine learning becomes more prominent there is a growing demand to perform several inference tasks in parallel. Running a dedicated model for each task is computationally expensive and therefore there is a great interest in multi-task learning (MTL). MTL aims at learning a single model that solves several tasks efficiently. Optimizing MTL models is often achieved by computing a single gradient per task and aggregating them for obtaining a combined update direction. However, these approaches do not consider an important aspect, the sensitivity in the gradient dimensions. Here, we introduce a novel gradient aggregation approach using Bayesian inference. We place a probability distribution over the task-specific parameters, which in turn induce a distribution over the gradients of the tasks. This additional valuable information allows us to quantify the uncertainty in each of the gradients dimensions, which can then be factored in when aggregating them. We empirically demonstrate the benefits of our approach in a variety of datasets, achieving state-of-the-art performance.
Read more5/14/2024

0
Task Weighting through Gradient Projection for Multitask Learning
Christian Bohn, Ido Freeman, Hasan Tercan, Tobias Meisen
In multitask learning, conflicts between task gradients are a frequent issue degrading a model's training performance. This is commonly addressed by using the Gradient Projection algorithm PCGrad that often leads to faster convergence and improved performance metrics. In this work, we present a method to adapt this algorithm to simultaneously also perform task prioritization. Our approach differs from traditional task weighting performed by scaling task losses in that our weighting scheme applies only in cases where tasks are in conflict, but lets the training proceed unhindered otherwise. We replace task weighting factors by a probability distribution that determines which task gradients get projected in conflict cases. Our experiments on the nuScenes, CIFAR-100, and CelebA datasets confirm that our approach is a practical method for task weighting. Paired with multiple different task weighting schemes, we observe a significant improvement in the performance metrics of most tasks compared to Gradient Projection with uniform projection probabilities.
Read more9/4/2024