Do Deep Neural Network Solutions Form a Star Domain?

0

Sign in to get full access
Overview
- This paper explores the "star domain conjecture" in the context of neural network optimization and landscape analysis.
- The star domain conjecture suggests that the optimization landscape of neural networks has a "star-shaped" structure, which could have important implications for understanding and improving training dynamics.
- The paper presents theoretical and empirical analysis to better understand the properties of the neural network optimization landscape.
Plain English Explanation
The researchers in this paper are investigating an idea called the "star domain conjecture" as it relates to how neural networks are trained. Neural networks are a type of machine learning model that can learn to perform complex tasks by analyzing large amounts of data.
The star domain conjecture suggests that the "landscape" of a neural network's optimization process has a particular shape - it's like a star, with the arms of the star representing different parts of the optimization process. If this is true, it could help us understand why neural networks are able to be trained effectively, even though they have a very high-dimensional and complex optimization landscape.
The researchers explore this idea both theoretically, by analyzing the mathematical properties of the neural network landscape, and empirically, by running experiments to see if the star-shaped structure actually exists in real neural networks. By better understanding the shape of the neural network optimization landscape, the researchers hope to gain insights that could lead to improvements in how these powerful models are trained and optimized.
Technical Explanation
The paper investigates the "star domain conjecture" as it relates to the optimization landscape of neural networks. This conjecture suggests that the loss function of a neural network has a "star-shaped" structure, meaning it can be viewed as a collection of "arms" or subspaces radiating out from a central point.
The authors first provide background on the "convexity conjecture" - the idea that neural network optimization landscapes may be convex or near-convex, which could explain their trainability. They then introduce the star domain conjecture as a potentially stronger property that could further elucidate the structure of these landscapes.
Through theoretical analysis and empirical experiments, the researchers explore key properties of the star domain, such as link to "Simultaneous Linear Connectivity of Neural Networks Modulo Permutation" and link to "Does SGD Really Happen in a Tiny Subspace?". They also investigate how link to "Stochastic Collapse: How Gradient Noise Attracts SGD" and other training dynamics may be impacted by the star-shaped geometry.
Overall, the paper provides a detailed analysis of the star domain conjecture and its implications for understanding the optimization landscape of neural networks and improving training algorithms like link to "Scalable Bayesian Inference in the Era of Deep Learning: From Markov Chain Monte Carlo to Variational Inference and Beyond".
Critical Analysis
The paper provides a rigorous theoretical and empirical investigation of the star domain conjecture, exploring its implications for neural network optimization and training dynamics. The authors acknowledge that while the star domain structure appears to hold in many cases, there may be exceptions or limitations to this property.
One potential concern raised is that the star domain structure may be sensitive to network initialization, architecture, or training procedure. The authors note that further research is needed to understand the generality and robustness of the star domain across different neural network models and settings.
Additionally, while the star domain conjecture offers insights into the overall shape of the optimization landscape, it does not fully capture the high-dimensional and complex nature of neural network loss functions. Other complementary perspectives, such as the link to "Exploring Neural Network Landscape" framework, may be necessary to develop a more comprehensive understanding of these landscapes.
Overall, the paper makes a valuable contribution by shedding light on the structural properties of neural network optimization landscapes and opening up new avenues for improving training algorithms and optimization techniques. However, as with any research, further validation and exploration of the star domain conjecture's implications will be important for advancing the field.
Conclusion
This paper presents a detailed investigation of the "star domain conjecture" and its relevance to understanding the optimization landscape of neural networks. Through theoretical analysis and empirical experiments, the researchers provide evidence for the star-shaped structure of these landscapes and explore its potential implications for neural network training dynamics.
By elucidating the geometric properties of the optimization landscape, the star domain conjecture offers a promising framework for improving our understanding of why neural networks are so effectively trainable, despite their high-dimensional and complex nature. This work lays the groundwork for further research into the structural characteristics of neural network loss functions and how they can be leveraged to develop more efficient and robust training algorithms.
Overall, this paper contributes valuable insights to the ongoing effort to unravel the mysteries of neural network optimization and paves the way for future advancements in the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do Deep Neural Network Solutions Form a Star Domain?
Ankit Sonthalia, Alexander Rubinstein, Ehsan Abbasnejad, Seong Joon Oh
It has recently been conjectured that neural network solution sets reachable via stochastic gradient descent (SGD) are convex, considering permutation invariances (Entezari et al., 2022). This means that a linear path can connect two independent solutions with low loss, given the weights of one of the models are appropriately permuted. However, current methods to test this theory often require very wide networks to succeed. In this work, we conjecture that more generally, the SGD solution set is a star domain that contains a star model that is linearly connected to all the other solutions via paths with low loss values, modulo permutations. We propose the Starlight algorithm that finds a star model of a given learning task. We validate our claim by showing that this star model is linearly connected with other independently found solutions. As an additional benefit of our study, we demonstrate better uncertainty estimates on the Bayesian Model Averaging over the obtained star domain. Further, we demonstrate star models as potential substitutes for model ensembles. Our code is available at https://github.com/aktsonthalia/starlight.
Read more6/11/2024
0
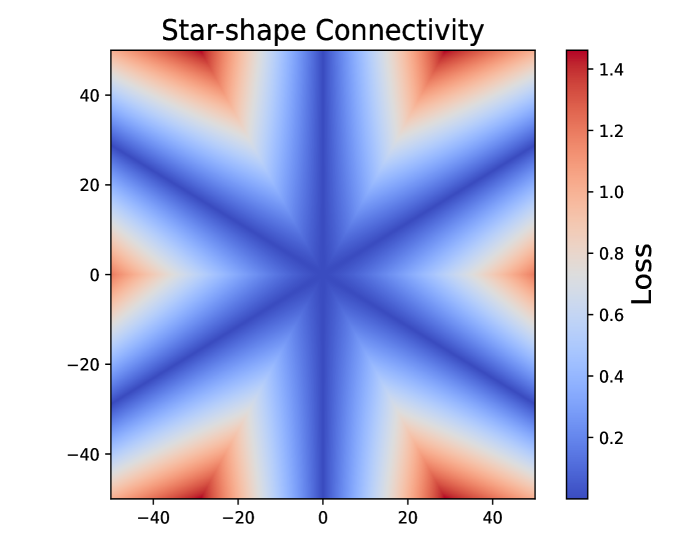
Exploring Neural Network Landscapes: Star-Shaped and Geodesic Connectivity
Zhanran Lin, Puheng Li, Lei Wu
One of the most intriguing findings in the structure of neural network landscape is the phenomenon of mode connectivity: For two typical global minima, there exists a path connecting them without barrier. This concept of mode connectivity has played a crucial role in understanding important phenomena in deep learning. In this paper, we conduct a fine-grained analysis of this connectivity phenomenon. First, we demonstrate that in the overparameterized case, the connecting path can be as simple as a two-piece linear path, and the path length can be nearly equal to the Euclidean distance. This finding suggests that the landscape should be nearly convex in a certain sense. Second, we uncover a surprising star-shaped connectivity: For a finite number of typical minima, there exists a center on minima manifold that connects all of them simultaneously via linear paths. These results are provably valid for linear networks and two-layer ReLU networks under a teacher-student setup, and are empirically supported by models trained on MNIST and CIFAR-10.
Read more4/10/2024
🗣️
0
There is a Singularity in the Loss Landscape
Mark Lowell
Despite the widespread adoption of neural networks, their training dynamics remain poorly understood. We show experimentally that as the size of the dataset increases, a point forms where the magnitude of the gradient of the loss becomes unbounded. Gradient descent rapidly brings the network close to this singularity in parameter space, and further training takes place near it. This singularity explains a variety of phenomena recently observed in the Hessian of neural network loss functions, such as training on the edge of stability and the concentration of the gradient in a top subspace. Once the network approaches the singularity, the top subspace contributes little to learning, even though it constitutes the majority of the gradient.
Read more7/23/2024
🔗
0
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Feng Chen, Daniel Kunin, Atsushi Yamamura, Surya Ganguli
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
Read more5/30/2024