Do Llamas Work in English? On the Latent Language of Multilingual Transformers
2402.10588
1
0
💬
Abstract
We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language models function and the origins of linguistic bias. Focusing on the Llama-2 family of transformer models, our study uses carefully constructed non-English prompts with a unique correct single-token continuation. From layer to layer, transformers gradually map an input embedding of the final prompt token to an output embedding from which next-token probabilities are computed. Tracking intermediate embeddings through their high-dimensional space reveals three distinct phases, whereby intermediate embeddings (1) start far away from output token embeddings; (2) already allow for decoding a semantically correct next token in the middle layers, but give higher probability to its version in English than in the input language; (3) finally move into an input-language-specific region of the embedding space. We cast these results into a conceptual model where the three phases operate in input space, concept space, and output space, respectively. Crucially, our evidence suggests that the abstract concept space lies closer to English than to other languages, which may have important consequences regarding the biases held by multilingual language models.
Create account to get full access
Overview
- This paper investigates whether multilingual language models rely on English as an internal "pivot" language when processing other languages.
- The researchers focus on the LLaMA-2 family of transformer models and use carefully designed prompts in non-English languages to track how the model's internal representations evolve.
- The study reveals three distinct phases in how the model processes the input and generates the output, shedding light on the origins of linguistic bias in these models.
Plain English Explanation
The researchers wanted to understand how multilingual language models, which are trained on a mix of languages but tend to be dominated by English, process and generate text in different languages. Do these models use English as an internal "pivot" language, relying on English-centric representations even when working with other languages?
To investigate this, the researchers focused on the LLaMA-2 family of transformer models. They created special prompts in non-English languages that had a single, clear correct answer. By tracking how the model's internal representations evolved as it processed these prompts, they could see if the model was consistently mapping the input to an English-centric "concept space" before generating the output.
The researchers found that the model's internal representations went through three distinct phases:
- The initial input embedding was far from the final output embedding, suggesting the model had to do significant translation work.
- In the middle layers, the model was able to identify the semantically correct next token, but still gave higher probability to the English version of that token.
- Finally, the representations moved into a language-specific region of the embedding space, producing the correct output.
This suggests that the model's "concept space" - the abstract representations it uses to understand the meaning of the text - is closer to English than to other languages. This could help explain the linguistic biases often observed in these types of multilingual models.
Technical Explanation
The researchers used carefully constructed prompts in non-English languages to probe how multilingual language models, specifically the LLaMA-2 family of transformer models, process and generate text across different languages. By tracking the model's internal representations as it processed these prompts, they were able to uncover three distinct phases in the model's behavior:
-
Input Space: The initial input embedding of the final prompt token is far away from the output embedding of the correct next token. This suggests the model has to do significant "translation" work to map the input to the correct output.
-
Concept Space: In the middle layers, the model is already able to identify the semantically correct next token, but still gives higher probability to the English version of that token rather than the version in the input language. This indicates the model's "concept space" - the abstract representations it uses to understand the meaning of the text - is closer to English than to other languages.
-
Output Space: Finally, the representations move into a language-specific region of the embedding space, producing the correct output token in the input language.
These results shed light on the origins of linguistic bias in multilingual language models, suggesting that the internal "concept space" used by these models is more aligned with English than with other languages. This has important implications for understanding how large language models (LLMs) function and handle multilingualism (https://aimodels.fyi/papers/arxiv/how-do-large-language-models-handle-multilingualism).
Critical Analysis
The researchers provide a compelling analysis of how multilingual language models like LLaMA-2 process and generate text across different languages. Their careful experimental design and insightful tracking of the model's internal representations offer valuable insights into the origins of linguistic bias in these models.
One potential limitation of the study is that it focuses on a single family of models (LLaMA-2) and a limited set of non-English languages. It would be interesting to see if the same patterns hold true for other multilingual models and a more diverse set of languages (https://aimodels.fyi/papers/arxiv/language-specific-neurons-key-to-multilingual-capabilities).
Additionally, the paper does not delve into the potential implications of these findings for practical applications of multilingual language models (https://aimodels.fyi/papers/arxiv/could-we-have-had-better-multilingual-llms). Further research could explore how these insights could inform the development of more equitable and inclusive language models.
Overall, this study provides valuable insights into the inner workings of multilingual language models and highlights the importance of understanding and addressing linguistic biases in these powerful AI systems.
Conclusion
This paper offers a fascinating glimpse into the inner workings of multilingual language models, revealing that they tend to rely on English as an internal "pivot" language when processing and generating text in other languages. The researchers' careful experimental design and analysis of the model's internal representations shed light on the origins of linguistic bias in these models, which have important implications for their practical applications and the development of more equitable and inclusive language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
0
0
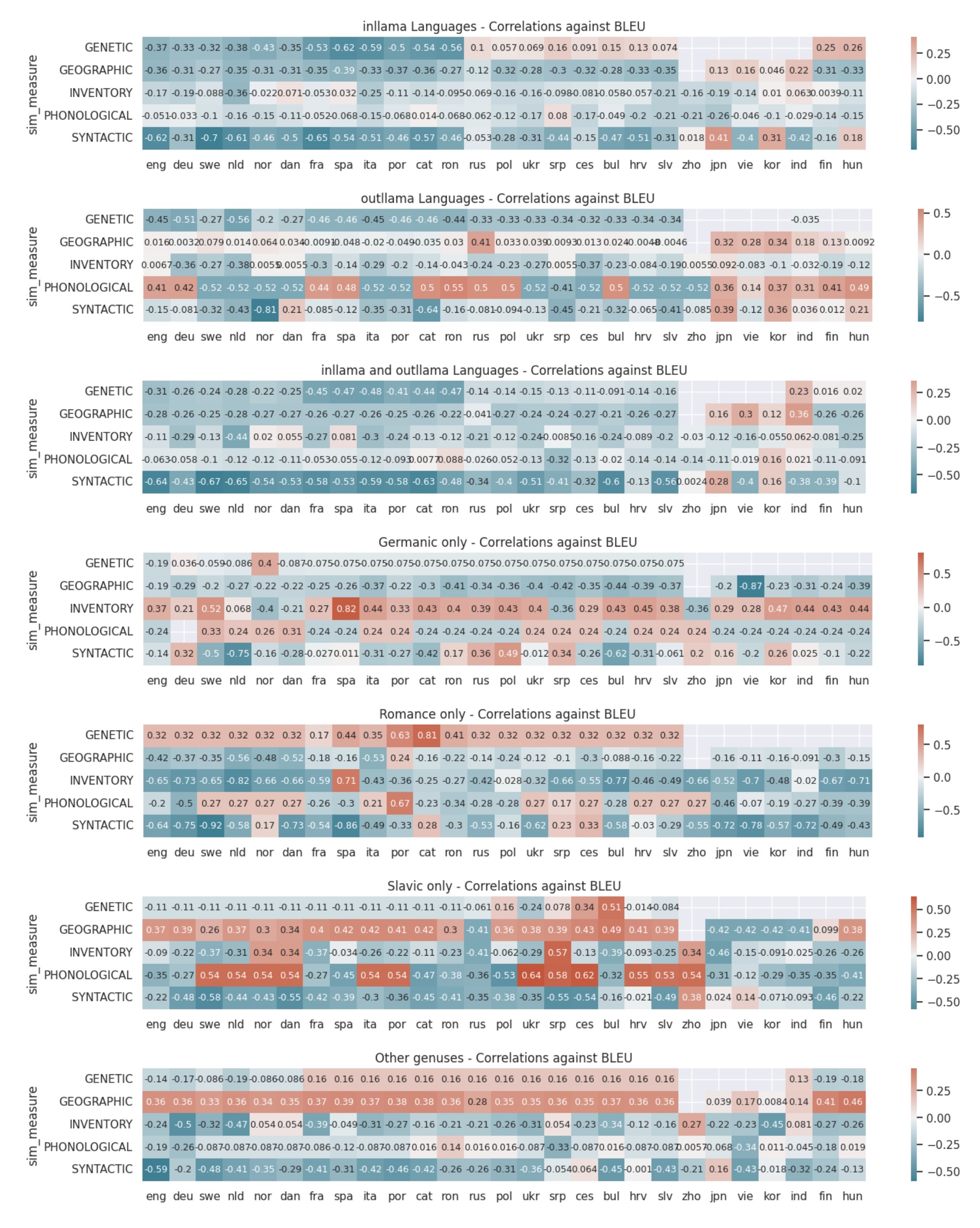
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
4/8/2024
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
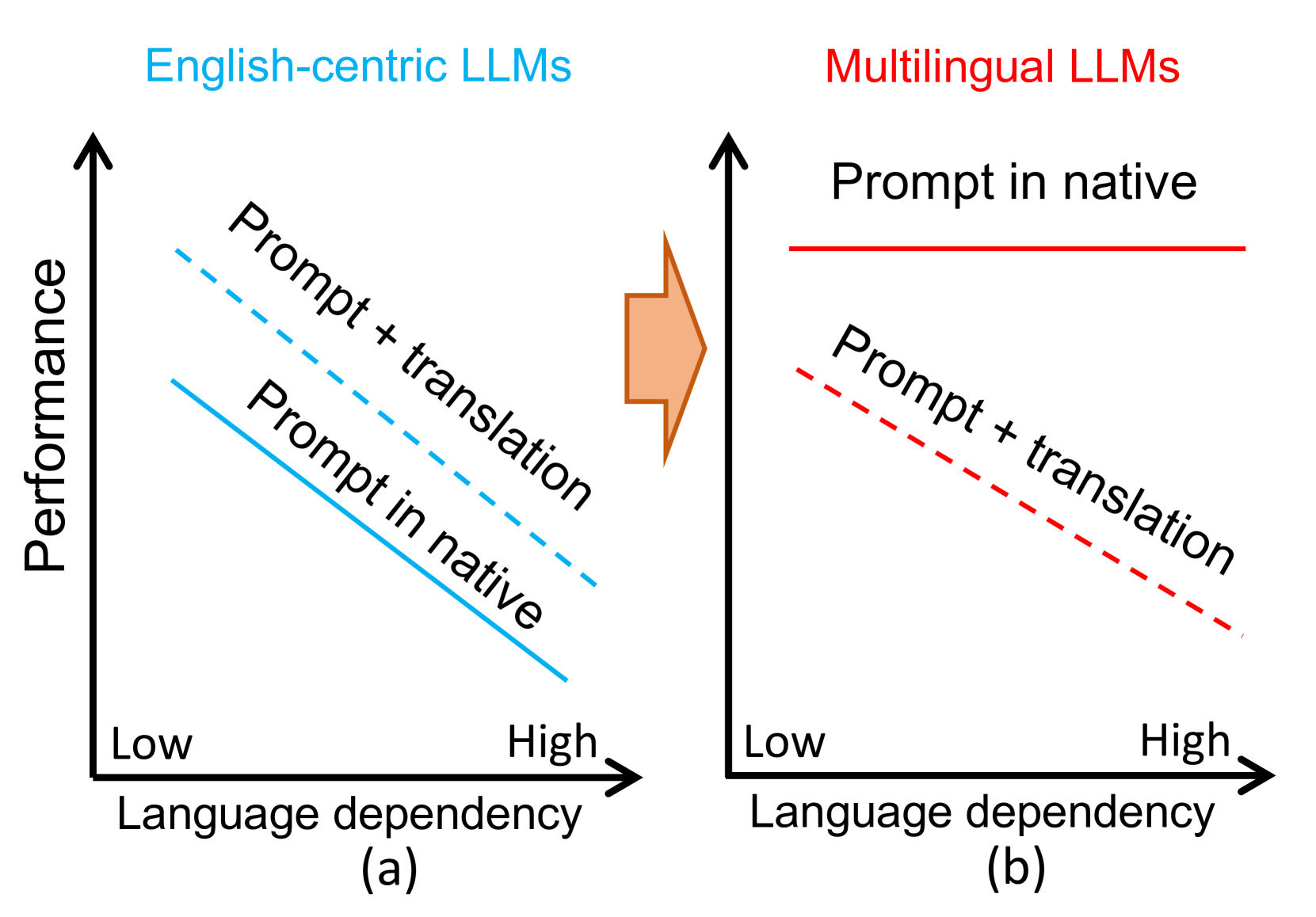
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024
How do Large Language Models Handle Multilingualism?
Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, Lidong Bing
0
0
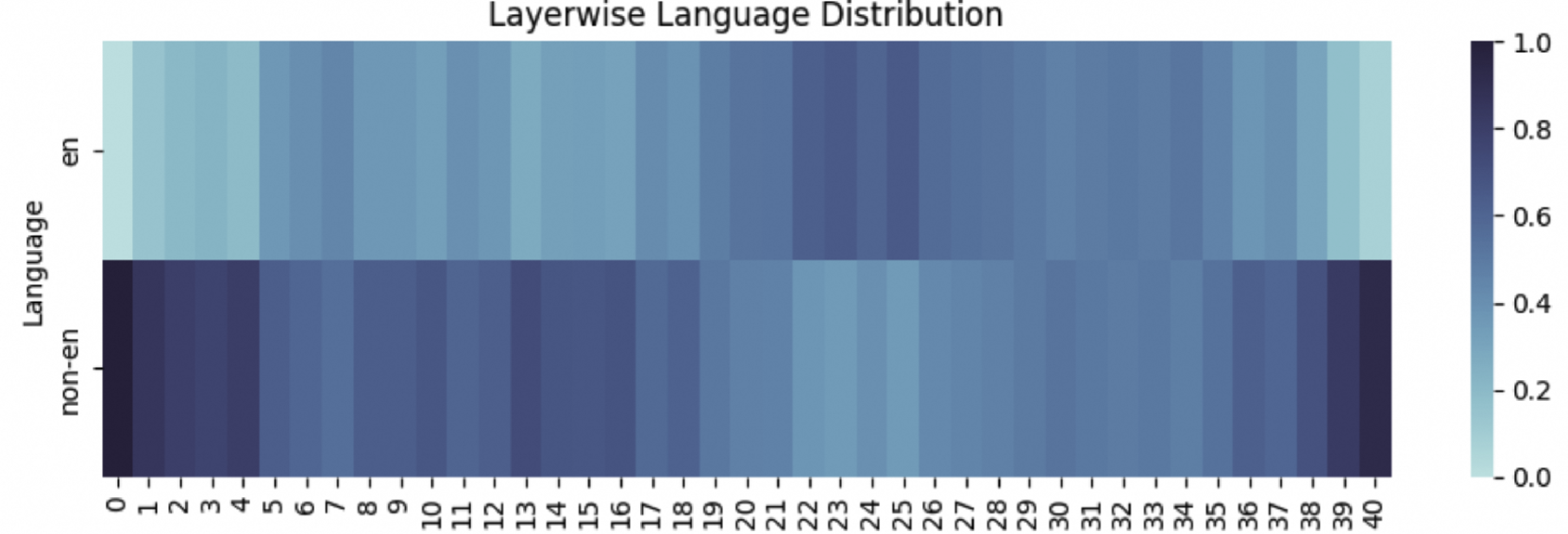
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
5/27/2024
💬
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
0
0
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
6/14/2024