Do LLMs Play Dice? Exploring Probability Distribution Sampling in Large Language Models for Behavioral Simulation
2404.09043
0
0
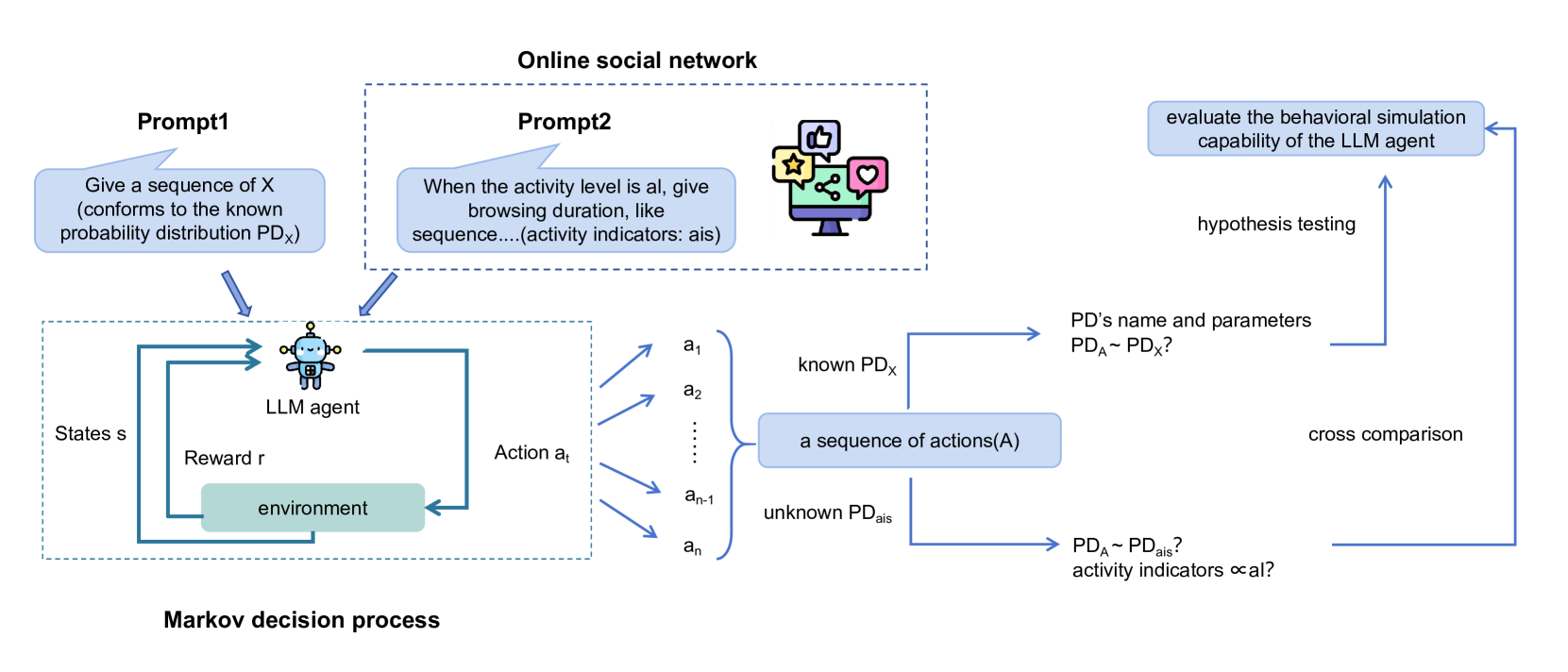
Abstract
With the rapid advancement of large language models (LLMs) for handling complex language tasks, an increasing number of studies are employing LLMs as agents to emulate the sequential decision-making processes of humans often represented as Markov decision-making processes (MDPs). The actions in MDPs adhere to specific probability distributions and require iterative sampling. This arouses curiosity regarding the capacity of LLM agents to comprehend probability distributions, thereby guiding the agent's behavioral decision-making through probabilistic sampling and generating behavioral sequences. To answer the above question, we divide the problem into two main aspects: sequence simulation with known probability distribution and sequence simulation with unknown probability distribution. Our analysis indicates that LLM agents can understand probabilities, but they struggle with probability sampling. Their ability to perform probabilistic sampling can be improved to some extent by integrating coding tools, but this level of sampling precision still makes it difficult to simulate human behavior as agents.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) handle probability distribution sampling, which is an important aspect of their ability to simulate human-like behavior.
- The researchers investigate whether LLMs are truly "playing dice" by analyzing their ability to sample from probability distributions in a way that mimics human decision-making.
- The findings have implications for the development of LLM-based agents that can engage in realistic behavioral simulations, such as in gaming, robotics, and decision-making scenarios.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text. Researchers are interested in understanding how these models work under the hood, especially when it comes to simulating human-like behavior. One key aspect of this is how LLMs handle probability distributions, which are mathematical representations of the likelihood of different outcomes.
In this paper, the researchers explored whether LLMs are truly "playing dice" - that is, whether they are able to sample from probability distributions in a way that mimics how humans make decisions. This is important because LLMs are increasingly being used to create virtual agents that can engage in realistic behavioral simulations, such as in video games, robotics, and decision-making scenarios.
By analyzing the way LLMs handle probability distributions, the researchers aimed to gain insights into the inner workings of these models and assess their potential for creating more human-like agents. The findings could have implications for the development of LLM-based systems that can better capture the nuances of human behavior.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to sample from probability distributions, which is a crucial component of their capacity to simulate human-like behavior. The researchers analyzed the distributions of the logits (or unnormalized log-probabilities) produced by LLMs when generating text, and compared them to the distributions observed in human decision-making data.
The study used several LLM architectures, including GPT-3, LaMDA, and PaLM, and evaluated their performance across a range of tasks, such as text generation, decision-making, and behavioral simulation. The researchers employed various statistical techniques, including hypothesis testing and model fitting, to assess the similarities and differences between the LLM-generated distributions and the human-derived distributions.
The key findings suggest that LLMs do not always faithfully reproduce the probability distributions observed in human behavior, particularly in more complex decision-making scenarios. The researchers identified systematic biases and deviations in the LLMs' sampling behavior, which could have implications for their use in applications that require human-like decision-making or behavioral simulation.
Critical Analysis
The paper provides a valuable contribution to the understanding of the inner workings of large language models and their potential limitations when it comes to simulating human-like behavior. The researchers' focus on probability distribution sampling is an important and often overlooked aspect of LLM behavior, and the findings suggest that there is still work to be done to bridge the gap between the models' capabilities and human decision-making.
One potential limitation of the study is the reliance on a relatively narrow set of tasks and datasets, which may not fully capture the diversity of human decision-making scenarios. Additionally, the paper does not delve deeply into the potential underlying causes of the observed biases and deviations in the LLMs' sampling behavior, which could be an area for further investigation.
It would also be interesting to see how the findings might apply to more advanced LLM architectures or techniques, such as those that incorporate additional mechanisms for uncertainty modeling or causal reasoning. Exploring the importance of uncertainty in decision-making for large language models could be a relevant area of research in this context.
Overall, the paper raises important questions about the limitations of current LLM approaches and the need for further research to develop more human-like decision-making and behavioral simulation capabilities in these models. Probing large language models from a human behavioral perspective and exploring the use of LLMs in game agents and autonomous agents could be fruitful avenues for future work in this area.
Conclusion
This paper presents a thought-provoking exploration of the ability of large language models to simulate human-like decision-making and behavior through the lens of probability distribution sampling. The findings suggest that while LLMs have made significant strides in generating human-like text, they still face challenges in faithfully reproducing the nuances of human decision-making, particularly in more complex scenarios.
The insights gained from this research could have important implications for the development of LLM-based agents and systems that aim to engage in realistic behavioral simulations, such as in gaming, robotics, and decision-support applications. By better understanding the limitations and biases of these models, researchers and developers can work towards creating more human-like and trustworthy AI systems that can more accurately capture the complexities of human behavior.
Exploring the use of large language models in causal decision-making and surveying the broader landscape of LLM-based autonomous agents could be fruitful next steps in this line of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
Akshay Paruchuri, Jake Garrison, Shun Liao, John Hernandez, Jacob Sunshine, Tim Althoff, Xin Liu, Daniel McDuff
0
0
Language models (LM) are capable of remarkably complex linguistic tasks; however, numerical reasoning is an area in which they frequently struggle. An important but rarely evaluated form of reasoning is understanding probability distributions. In this paper, we focus on evaluating the probabilistic reasoning capabilities of LMs using idealized and real-world statistical distributions. We perform a systematic evaluation of state-of-the-art LMs on three tasks: estimating percentiles, drawing samples, and calculating probabilities. We evaluate three ways to provide context to LMs 1) anchoring examples from within a distribution or family of distributions, 2) real-world context, 3) summary statistics on which to base a Normal approximation. Models can make inferences about distributions, and can be further aided by the incorporation of real-world context, example shots and simplified assumptions, even if these assumptions are incorrect or misspecified. To conduct this work, we developed a comprehensive benchmark distribution dataset with associated question-answer pairs that we will release publicly.
6/19/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
0
0
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 60.5. Moreover, Gemini-1.0-Pro and GPT-3.5 (0613, 1106, 0125) demonstrate similar intelligence on GAMA-Bench. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
4/26/2024
🤿
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
0
0
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
6/14/2024