What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
2406.12830
0
0
💬
Abstract
Language models (LM) are capable of remarkably complex linguistic tasks; however, numerical reasoning is an area in which they frequently struggle. An important but rarely evaluated form of reasoning is understanding probability distributions. In this paper, we focus on evaluating the probabilistic reasoning capabilities of LMs using idealized and real-world statistical distributions. We perform a systematic evaluation of state-of-the-art LMs on three tasks: estimating percentiles, drawing samples, and calculating probabilities. We evaluate three ways to provide context to LMs 1) anchoring examples from within a distribution or family of distributions, 2) real-world context, 3) summary statistics on which to base a Normal approximation. Models can make inferences about distributions, and can be further aided by the incorporation of real-world context, example shots and simplified assumptions, even if these assumptions are incorrect or misspecified. To conduct this work, we developed a comprehensive benchmark distribution dataset with associated question-answer pairs that we will release publicly.
Create account to get full access
Overview
- This paper evaluates the probabilistic reasoning capabilities of large language models (LLMs) across three key tasks: estimating percentiles, drawing samples, and calculating probabilities.
- The researchers developed a comprehensive benchmark dataset with statistical distributions and associated question-answer pairs to systematically assess LLM performance on these tasks.
- The paper explores how providing different types of context, such as anchoring examples or real-world information, can aid LLMs in making inferences about probability distributions, even when the underlying assumptions are imperfect.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become remarkably adept at various language tasks, from generating human-like text to answering questions. However, one area where they often struggle is numerical reasoning, including understanding probability distributions.
In this paper, the researchers set out to evaluate how well LLMs can reason about probability distributions. They focused on three key tasks: estimating percentiles (e.g., what value represents the 80th percentile of a distribution?), drawing samples (e.g., generating random numbers that follow a particular distribution), and calculating probabilities (e.g., what is the probability of a value falling within a certain range?).
To conduct this evaluation, the researchers developed a comprehensive dataset of statistical distributions, both idealized (like the normal distribution) and real-world (like the height distribution of adults). They then created question-answer pairs related to these distributions, which they used to test the LLMs.
The researchers found that LLMs can make inferences about probability distributions, but their performance can be improved by providing different types of context. For example, giving the LLM examples from within a distribution or real-world information about the distribution can help the model better understand the underlying statistical concepts.
Even when the provided context is not entirely accurate or complete, the LLMs are still able to use it to make reasonable inferences. This suggests that LLMs can be further developed to become more adept at numerical and probabilistic reasoning, which could have important applications in areas like statistical modeling and data analysis.
Technical Explanation
The researchers conducted a systematic evaluation of state-of-the-art large language models (LLMs) on three tasks related to probabilistic reasoning:
- Estimating Percentiles: Given a probability distribution, the models were asked to estimate specific percentile values (e.g., the 80th percentile).
- Drawing Samples: The models were tasked with generating random samples that follow a specified probability distribution.
- Calculating Probabilities: The models were asked to calculate the probability of a value falling within a certain range of a distribution.
To facilitate this evaluation, the researchers developed a comprehensive benchmark dataset of statistical distributions, including both idealized distributions (e.g., normal, exponential) and real-world distributions (e.g., height, income). They then created question-answer pairs related to these distributions, which they used to test the LLMs.
The researchers explored three ways of providing context to the LLMs to aid their probabilistic reasoning:
- Anchoring Examples: Providing the LLMs with example values drawn from within the distribution or family of distributions.
- Real-World Context: Giving the LLMs information about the real-world meaning and application of the distribution (e.g., the height distribution of adults).
- Summary Statistics: Providing the LLMs with summary statistics about the distribution, such as the mean and standard deviation, to serve as a basis for a normal approximation.
The results showed that LLMs can make inferences about probability distributions, and their performance can be improved by the incorporation of real-world context, example shots, and simplified assumptions, even if these assumptions are not entirely accurate or complete.
Critical Analysis
The paper presents a comprehensive and rigorous evaluation of LLM capabilities in the domain of probabilistic reasoning, which is an important but often overlooked aspect of these models' performance.
One limitation of the study is that it focuses primarily on evaluating LLM performance on three specific tasks: estimating percentiles, drawing samples, and calculating probabilities. While these tasks are important, there may be other forms of probabilistic reasoning that the models struggle with, which are not explored in this paper.
Additionally, the researchers acknowledge that the provided context, even when imperfect, can still aid the LLMs in making reasonable inferences. This suggests that the models may be relying more on the contextual information than on their own inherent probabilistic reasoning abilities. Further research is needed to fully understand the models' capabilities in this domain.
Another potential concern is the use of a custom dataset, which may limit the generalizability of the findings. While the researchers made efforts to include both idealized and real-world distributions, the dataset may not capture the full complexity of the probability distributions encountered in real-world scenarios.
Despite these limitations, the paper makes a valuable contribution by highlighting the importance of evaluating LLM capabilities in numerical and probabilistic reasoning, and providing a framework for systematic assessment in this area. The insights gained from this research could inform the development of more robust and capable LLMs, with applications in fields such as Bayesian statistical modeling.
Conclusion
This paper presents a comprehensive evaluation of the probabilistic reasoning capabilities of large language models (LLMs), focusing on three key tasks: estimating percentiles, drawing samples, and calculating probabilities. The researchers developed a benchmark dataset of statistical distributions, both idealized and real-world, and used it to systematically assess LLM performance.
The results show that LLMs can make inferences about probability distributions, and their performance can be enhanced by providing different types of contextual information, such as anchoring examples, real-world context, and summary statistics. Even when the provided context is not entirely accurate or complete, the LLMs are still able to use it to make reasonable inferences.
This research highlights the importance of evaluating LLM capabilities in numerical and probabilistic reasoning, which are essential for many real-world applications. The insights gained from this study could inform the development of more robust and capable LLMs, with the potential to contribute to fields like statistical modeling, data analysis, and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
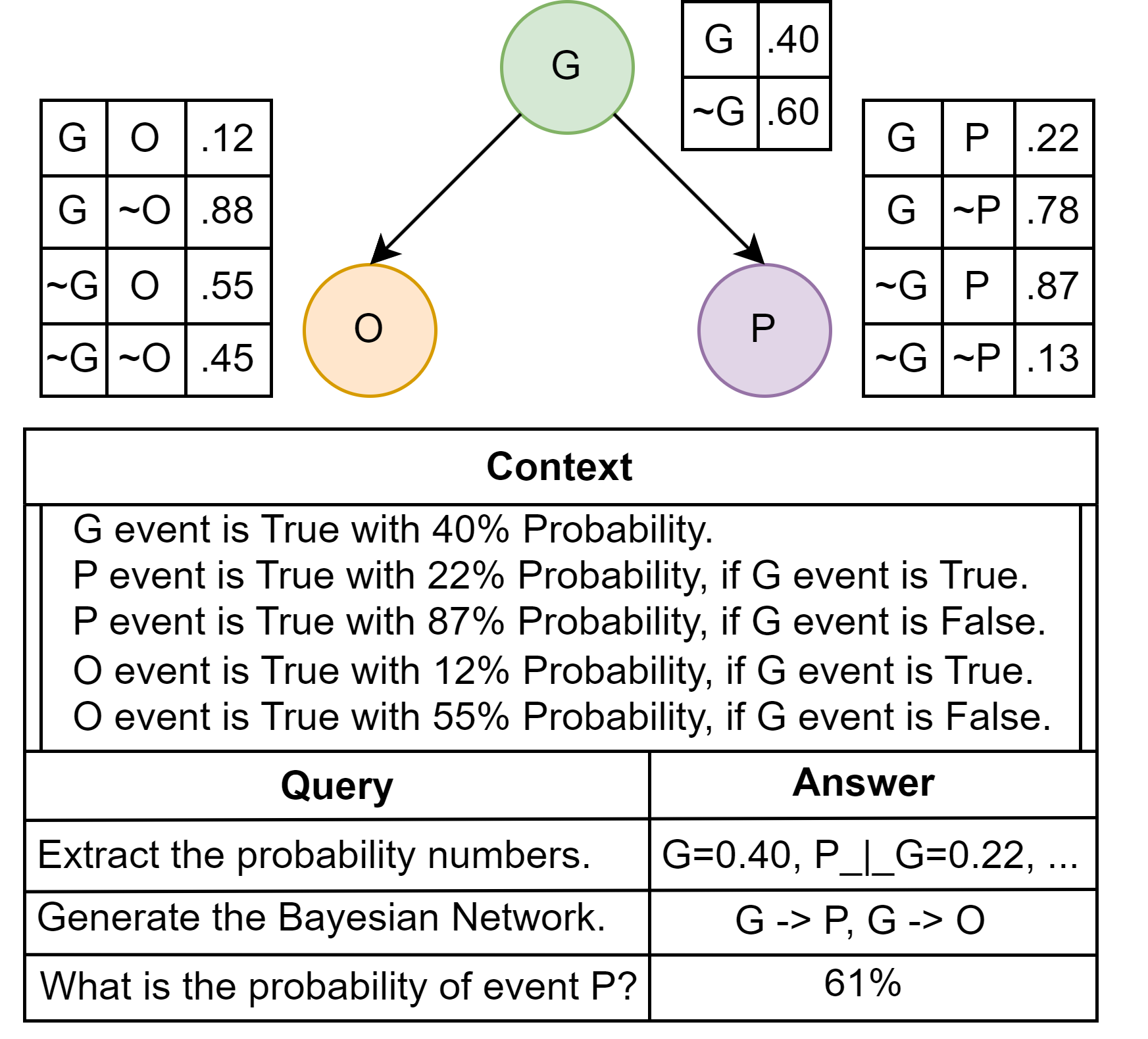
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
0
0
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
6/18/2024
🌿
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
James Requeima, John Bronskill, Dami Choi, Richard E. Turner, David Duvenaud
0
0
Machine learning practitioners often face significant challenges in formally integrating their prior knowledge and beliefs into predictive models, limiting the potential for nuanced and context-aware analyses. Moreover, the expertise needed to integrate this prior knowledge into probabilistic modeling typically limits the application of these models to specialists. Our goal is to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge. Large Language Models (LLMs) provide a useful starting point for designing such a tool since they 1) provide an interface where users can incorporate expert insights in natural language and 2) provide an opportunity for leveraging latent problem-relevant knowledge encoded in LLMs that users may not have themselves. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions, improving predictive performance and giving quantitative structure that reflects qualitative descriptions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode.
5/28/2024
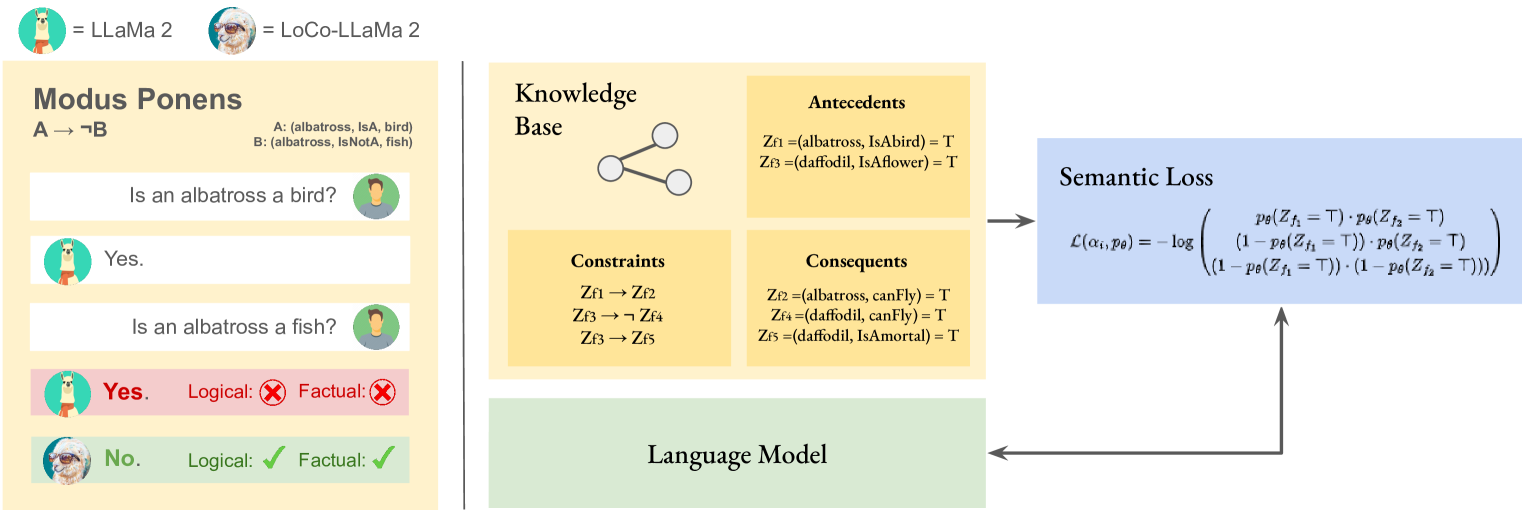
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024
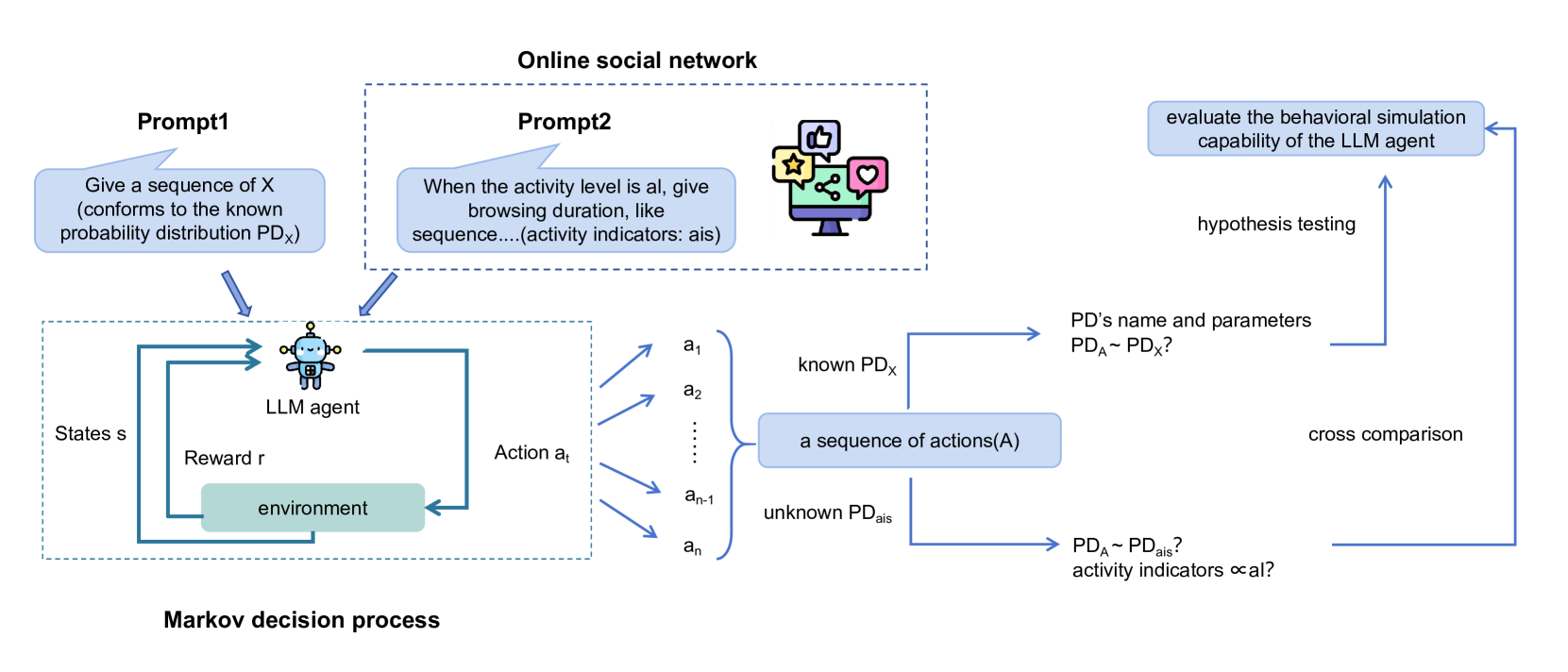
Do LLMs Play Dice? Exploring Probability Distribution Sampling in Large Language Models for Behavioral Simulation
Jia Gu, Liang Pang, Huawei Shen, Xueqi Cheng
0
0
With the rapid advancement of large language models (LLMs) for handling complex language tasks, an increasing number of studies are employing LLMs as agents to emulate the sequential decision-making processes of humans often represented as Markov decision-making processes (MDPs). The actions in MDPs adhere to specific probability distributions and require iterative sampling. This arouses curiosity regarding the capacity of LLM agents to comprehend probability distributions, thereby guiding the agent's behavioral decision-making through probabilistic sampling and generating behavioral sequences. To answer the above question, we divide the problem into two main aspects: sequence simulation with known probability distribution and sequence simulation with unknown probability distribution. Our analysis indicates that LLM agents can understand probabilities, but they struggle with probability sampling. Their ability to perform probabilistic sampling can be improved to some extent by integrating coding tools, but this level of sampling precision still makes it difficult to simulate human behavior as agents.
6/19/2024