Do We Trust What They Say or What They Do? A Multimodal User Embedding Provides Personalized Explanations

0
Sign in to get full access
Overview
- The paper proposes a multimodal user embedding approach that combines linguistic, behavioral, and visual signals to provide personalized explanations.
- This approach aims to better understand user preferences and behaviors beyond just what they say, by also considering their actions and visual attributes.
- The authors demonstrate the effectiveness of their method on several tasks, including user preference prediction and personalized recommendation.
Plain English Explanation
The paper argues that to truly understand users, we need to look beyond just what they say and also consider what they do and how they look. The researchers developed a new way to create user profiles that combines information from a person's language, behavior, and visual appearance.
This multimodal user embedding approach allows systems to get a more well-rounded understanding of each individual user. Rather than just relying on what users explicitly tell the system, it also considers their actions and physical characteristics to infer their preferences and personality.
The authors show that this more comprehensive user profile leads to better performance on tasks like predicting user preferences and providing personalized recommendations. By incorporating these different signals, the system can make more accurate and tailored decisions for each user.
Technical Explanation
The core of the paper is a multimodal user embedding model that learns a joint representation of a user's linguistic, behavioral, and visual attributes. The linguistic features are extracted from the user's text, the behavioral features come from their interactions and actions, and the visual features are derived from their profile image.
These three modalities are then combined using a neural network architecture to produce a single, unified user embedding. The authors experiment with different fusion strategies, including concatenation, attention, and graph neural networks, to determine the most effective way to integrate the multimodal signals.
The resulting user embeddings are evaluated on two main tasks: user preference prediction and personalized recommendation. The preference prediction task involves forecasting a user's rating or preference for an item based on their profile. The personalized recommendation task aims to suggest items that are well-matched to the user's interests and characteristics.
Experiments on several real-world datasets demonstrate the advantages of the multimodal approach over unimodal baselines that only consider one type of user information. The multimodal embeddings consistently outperform these alternatives, highlighting the value of combining linguistic, behavioral, and visual signals to build a more comprehensive user model.
Critical Analysis
The paper makes a compelling case for going beyond simplistic user representations based on just text or just behavior. By incorporating multimodal information, the authors are able to capture richer and more nuanced user profiles.
However, a potential limitation is that the user images used in the study may not always be representative or informative. People often carefully curate their profile photos, which may not accurately reflect their true appearance or personality. Relying too heavily on visual signals could therefore introduce biases.
Additionally, the paper does not explore how the multimodal user embeddings might evolve over time as the user's behavior and appearance change. A static snapshot may not be sufficient, and a more dynamic user modeling approach may be necessary.
Further research could also investigate the interpretability and explainability of the multimodal embeddings. While the personalized predictions are shown to be more accurate, it's unclear how the system arrives at those recommendations and whether users will find the explanations transparent and trustworthy.
Conclusion
This paper presents a promising step towards building more comprehensive and personalized user models by fusing linguistic, behavioral, and visual signals. By considering the full scope of how users express themselves, the multimodal approach can lead to improved performance on tasks like preference prediction and recommendation.
While there are some potential limitations to the current implementation, the core ideas highlight the value of combining different modalities to gain a deeper understanding of individual users. As AI systems become more integrated into our daily lives, developing such multifaceted user representations will be crucial for delivering truly personalized and trustworthy experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do We Trust What They Say or What They Do? A Multimodal User Embedding Provides Personalized Explanations
Zhicheng Ren, Zhiping Xiao, Yizhou Sun
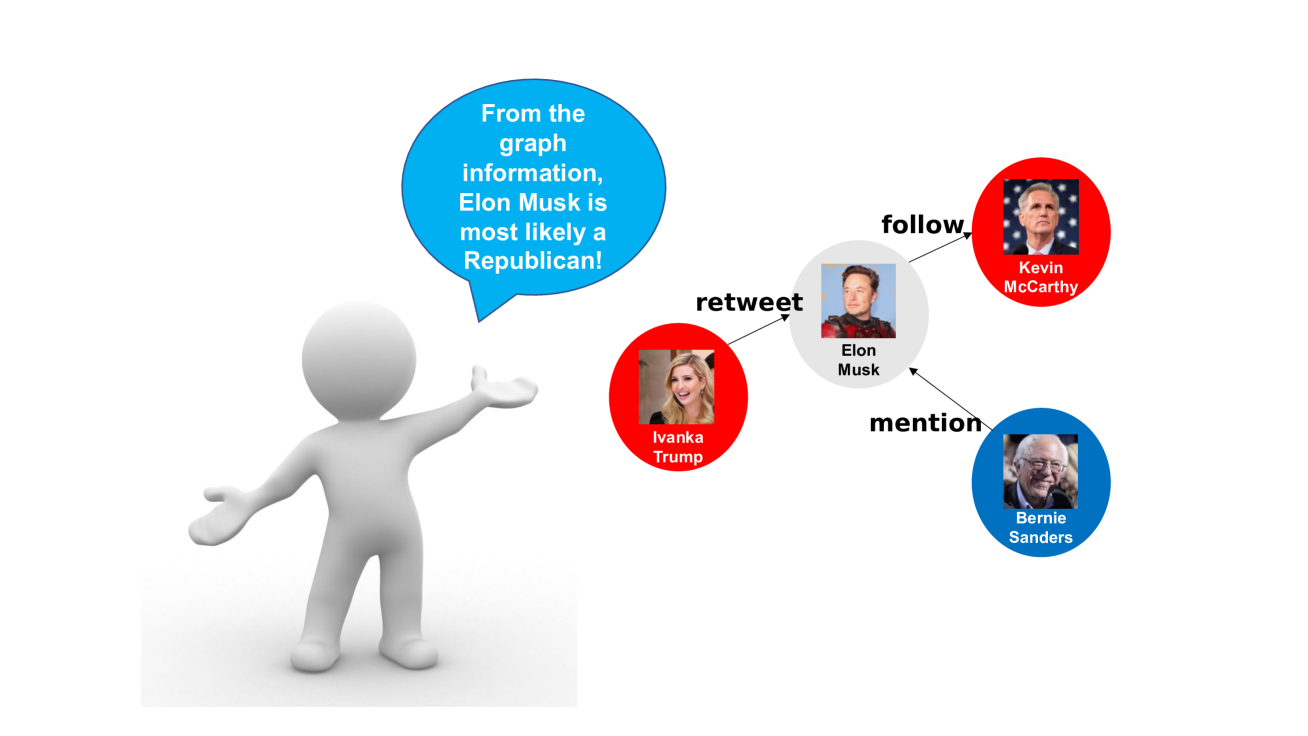
With the rapid development of social media, the importance of analyzing social network user data has also been put on the agenda. User representation learning in social media is a critical area of research, based on which we can conduct personalized content delivery, or detect malicious actors. Being more complicated than many other types of data, social network user data has inherent multimodal nature. Various multimodal approaches have been proposed to harness both text (i.e. post content) and relation (i.e. inter-user interaction) information to learn user embeddings of higher quality. The advent of Graph Neural Network models enables more end-to-end integration of user text embeddings and user interaction graphs in social networks. However, most of those approaches do not adequately elucidate which aspects of the data - text or graph structure information - are more helpful for predicting each specific user under a particular task, putting some burden on personalized downstream analysis and untrustworthy information filtering. We propose a simple yet effective framework called Contribution-Aware Multimodal User Embedding (CAMUE) for social networks. We have demonstrated with empirical evidence, that our approach can provide personalized explainable predictions, automatically mitigating the impact of unreliable information. We also conducted case studies to show how reasonable our results are. We observe that for most users, graph structure information is more trustworthy than text information, but there are some reasonable cases where text helps more. Our work paves the way for more explainable, reliable, and effective social media user embedding which allows for better personalized content delivery.
Read more9/6/2024
🔄
0
Enhancing Social Media Personalization: Dynamic User Profile Embeddings and Multimodal Contextual Analysis Using Transformer Models
Pranav Vachharajani
This study investigates the impact of dynamic user profile embedding on personalized context-aware experiences in social networks. A comparative analysis of multilingual and English transformer models was performed on a dataset of over twenty million data points. The analysis included a wide range of metrics and performance indicators to compare dynamic profile embeddings versus non-embeddings (effectively static profile embeddings). A comparative study using degradation functions was conducted. Extensive testing and research confirmed that dynamic embedding successfully tracks users' changing tastes and preferences, providing more accurate recommendations and higher user engagement. These results are important for social media platforms aiming to improve user experience through relevant features and sophisticated recommendation engines.
Read more7/12/2024
0
Joint Embeddings for Graph Instruction Tuning
Aaron Haag, Vlad Argatu, Oliver Lohse
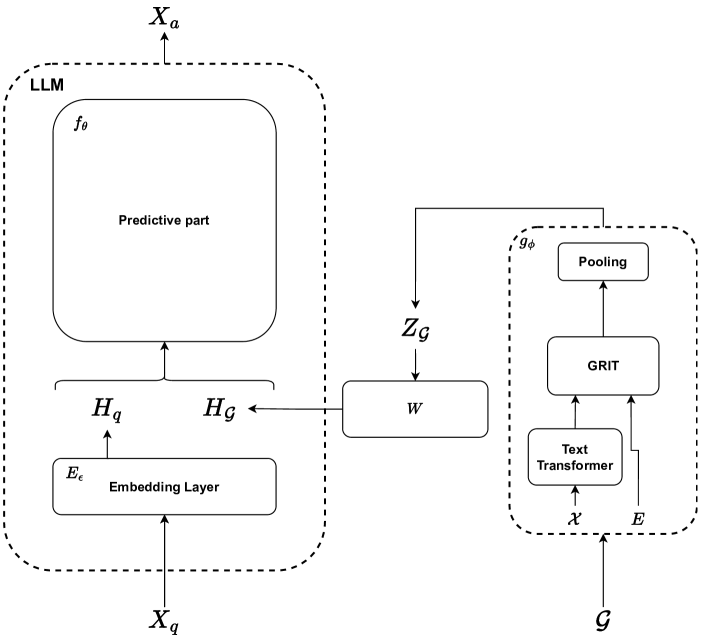
Large Language Models (LLMs) have achieved impressive performance in text understanding and have become an essential tool for building smart assistants. Originally focusing on text, they have been enhanced with multimodal capabilities in recent works that successfully built visual instruction following assistants. As far as the graph modality goes, however, no such assistants have yet been developed. Graph structures are complex in that they represent relation between different features and are permutation invariant. Moreover, representing them in purely textual form does not always lead to good LLM performance even for finetuned models. As a result, there is a need to develop a new method to integrate graphs in LLMs for general graph understanding. This work explores the integration of the graph modality in LLM for general graph instruction following tasks. It aims at producing a deep learning model that enhances an underlying LLM with graph embeddings and trains it to understand them and to produce, given an instruction, an answer grounded in the graph representation. The approach performs significantly better than a graph to text approach and remains consistent even for larger graphs.
Read more9/11/2024

0
Enhancing Apparent Personality Trait Analysis with Cross-Modal Embeddings
'Ad'am Fodor, Rachid R. Saboundji, Andr'as LH{o}rincz
Automatic personality trait assessment is essential for high-quality human-machine interactions. Systems capable of human behavior analysis could be used for self-driving cars, medical research, and surveillance, among many others. We present a multimodal deep neural network with a Siamese extension for apparent personality trait prediction trained on short video recordings and exploiting modality invariant embeddings. Acoustic, visual, and textual information are utilized to reach high-performance solutions in this task. Due to the highly centralized target distribution of the analyzed dataset, the changes in the third digit are relevant. Our proposed method addresses the challenge of under-represented extreme values, achieves 0.0033 MAE average improvement, and shows a clear advantage over the baseline multimodal DNN without the introduced module.
Read more5/8/2024