DocSynthv2: A Practical Autoregressive Modeling for Document Generation

0

Sign in to get full access
Overview
- The paper presents DocSynthv2, a practical autoregressive model for generating diverse and realistic documents.
- It builds upon previous work on autoregressive modeling for speech generation and accelerated generation techniques for large language models.
- The proposed model can be used to generate synthetic medical documents, which can be valuable for enhancing clinical documentation and leveraging synthetic data.
Plain English Explanation
The paper describes a new way to automatically generate text documents, similar to how SketchGPT can generate sketches or how Arrange, Inpaint, Refine can generate music. The model, called DocSynthv2, is able to create diverse and realistic-looking documents, such as medical reports, by learning patterns from existing documents.
This is useful because sometimes there isn't enough real data available, so generating synthetic data can help train other AI systems. For example, in healthcare, having a large dataset of realistic medical documents can help improve automated document analysis and generation tools. The key innovation of DocSynthv2 is that it can generate more natural and varied documents compared to previous approaches.
Technical Explanation
DocSynthv2 is an autoregressive model that generates documents by predicting the next word or token based on the previous ones. It builds on prior work in autoregressive modeling for speech generation and accelerated generation techniques for large language models.
The model is trained on a large corpus of existing documents, which allows it to learn the statistical patterns and structure of real documents. During generation, it iteratively predicts the next token, conditioning on the previously generated text, to produce a full document.
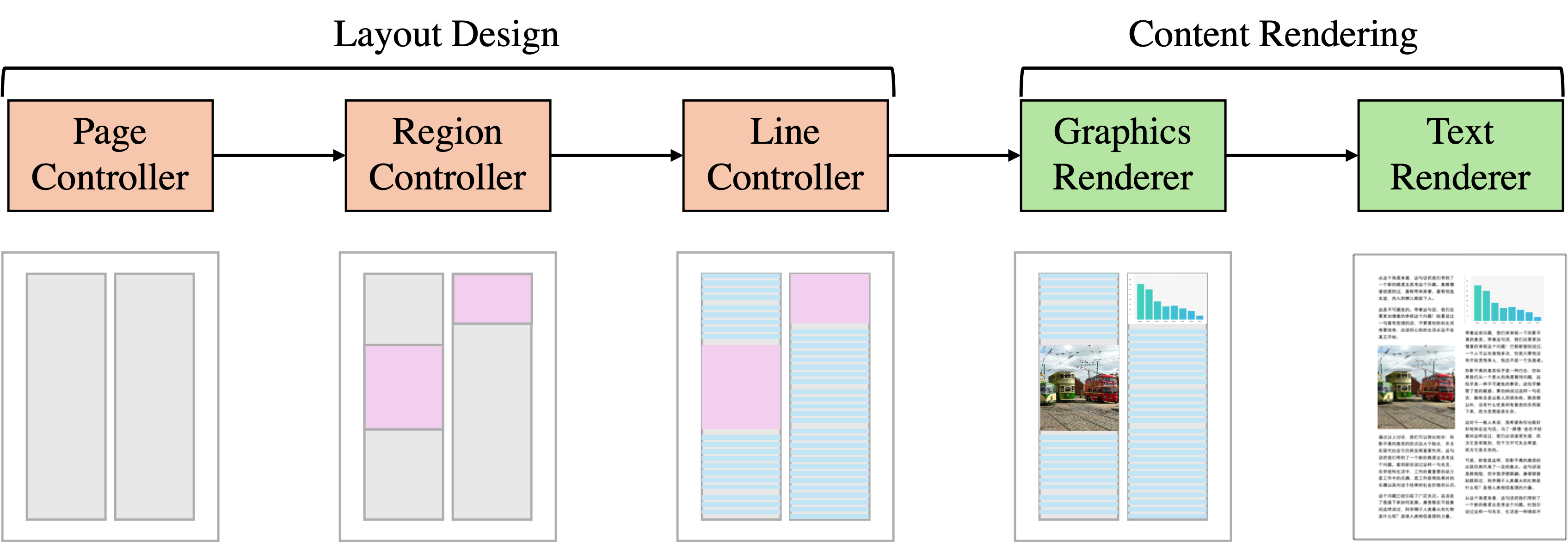
Key architectural features include:
- Hierarchical Generation: The model generates documents at multiple levels of granularity, from high-level document structure to low-level word choices.
- Diverse Sampling: The model uses advanced sampling techniques to generate a diverse set of documents, rather than just producing similar outputs.
- Controllable Generation: Users can provide prompts or constraints to guide the generation process towards specific document styles or content.
Experiments show that DocSynthv2 can generate high-quality synthetic documents that are difficult to distinguish from real ones, while offering significantly more diversity compared to previous approaches.
Critical Analysis
The paper provides a thorough evaluation of DocSynthv2, including comparisons to baseline models and human assessments of the generated documents. However, the authors acknowledge some limitations:
- The model is still prone to generating occasional incoherent or factually incorrect content, which needs to be addressed.
- The diversity of generated documents, while improved, could potentially be further enhanced through more advanced sampling techniques or architectural changes.
- The model's performance may be sensitive to the quality and characteristics of the training data, which could limit its applicability to diverse document types.
Further research could explore ways to improve the model's robustness, flexibility, and faithfulness to real-world document structures and content. Additionally, investigating the ethical implications of large-scale document generation, particularly in sensitive domains like healthcare, would be an important next step.
Conclusion
The DocSynthv2 model represents a significant advancement in the field of autoregressive document generation. By leveraging hierarchical generation, diverse sampling, and controllable techniques, the model can produce high-quality synthetic documents that are difficult to distinguish from real ones.
This technology has the potential to benefit a wide range of applications, from enhancing clinical documentation through synthetic data generation to accelerating the development of other AI systems that rely on large, diverse text corpora. As the research in this area continues to evolve, it will be crucial to address the remaining challenges and consider the ethical implications of such powerful document generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DocSynthv2: A Practical Autoregressive Modeling for Document Generation
Sanket Biswas, Rajiv Jain, Vlad I. Morariu, Jiuxiang Gu, Puneet Mathur, Curtis Wigington, Tong Sun, Josep Llad'os
While the generation of document layouts has been extensively explored, comprehensive document generation encompassing both layout and content presents a more complex challenge. This paper delves into this advanced domain, proposing a novel approach called DocSynthv2 through the development of a simple yet effective autoregressive structured model. Our model, distinct in its integration of both layout and textual cues, marks a step beyond existing layout-generation approaches. By focusing on the relationship between the structural elements and the textual content within documents, we aim to generate cohesive and contextually relevant documents without any reliance on visual components. Through experimental studies on our curated benchmark for the new task, we demonstrate the ability of our model combining layout and textual information in enhancing the generation quality and relevance of documents, opening new pathways for research in document creation and automated design. Our findings emphasize the effectiveness of autoregressive models in handling complex document generation tasks.
Read more6/13/2024
🎯
0
Enhancing Clinical Documentation with Synthetic Data: Leveraging Generative Models for Improved Accuracy
Anjanava Biswas, Wrick Talukdar
Accurate and comprehensive clinical documentation is crucial for delivering high-quality healthcare, facilitating effective communication among providers, and ensuring compliance with regulatory requirements. However, manual transcription and data entry processes can be time-consuming, error-prone, and susceptible to inconsistencies, leading to incomplete or inaccurate medical records. This paper proposes a novel approach to augment clinical documentation by leveraging synthetic data generation techniques to generate realistic and diverse clinical transcripts. We present a methodology that combines state-of-the-art generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), with real-world clinical transcript and other forms of clinical data to generate synthetic transcripts. These synthetic transcripts can then be used to supplement existing documentation workflows, providing additional training data for natural language processing models and enabling more accurate and efficient transcription processes. Through extensive experiments on a large dataset of anonymized clinical transcripts, we demonstrate the effectiveness of our approach in generating high-quality synthetic transcripts that closely resemble real-world data. Quantitative evaluation metrics, including perplexity scores and BLEU scores, as well as qualitative assessments by domain experts, validate the fidelity and utility of the generated synthetic transcripts. Our findings highlight synthetic data generation's potential to address clinical documentation challenges, improving patient care, reducing administrative burdens, and enhancing healthcare system efficiency.
Read more6/12/2024
0
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Chuanghao Ding, Xuejing Liu, Wei Tang, Juan Li, Xiaoliang Wang, Rui Zhao, Cam-Tu Nguyen, Fei Tan
This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Read more8/28/2024
🗣️
0
Parallel Synthesis for Autoregressive Speech Generation
Po-chun Hsu, Da-rong Liu, Andy T. Liu, Hung-yi Lee
Autoregressive neural vocoders have achieved outstanding performance in speech synthesis tasks such as text-to-speech and voice conversion. An autoregressive vocoder predicts a sample at some time step conditioned on those at previous time steps. Though it synthesizes natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance length, leading to low efficiency. Many works were dedicated to generating the whole speech sequence in parallel and proposed GAN-based, flow-based, and score-based vocoders. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is split into frequency subbands, and a subband is generated conditioned on the previously generated one. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance length but to the number of subbands/bits, significantly increasing inference efficiency. Besides, a post-filter is employed to sample signals from output posteriors; its training objective is designed based on the characteristics of the proposed methods. Experimental results show that the proposed model can synthesize speech faster than real-time without GPU acceleration. Compared with baseline vocoders, the proposed model achieves better MUSHRA results and shows good generalization ability for unseen speakers and 44 kHz speech.
Read more6/6/2024