Document-level Claim Extraction and Decontextualisation for Fact-Checking

0

Sign in to get full access
Overview
- This paper presents a document-level claim extraction and decontextualization approach for fact-checking.
- The goal is to automatically extract claims from documents and remove the context to facilitate fact-checking.
- The authors introduce a novel document-level claim extraction model and a decontextualization module to address the challenges of fact-checking.
Plain English Explanation
The paper focuses on improving the process of fact-checking by developing techniques to automatically extract claims from documents and present them in a simplified, decontextualized form. Fact-checking is the process of verifying the accuracy of statements, but it can be challenging when the claims are buried within lengthy documents or surrounded by additional context.
The researchers propose a two-step approach to address this problem. First, they develop a machine learning model to identify claims at the document level. This means the model can scan an entire document and extract the key claims, rather than just looking at individual sentences. Second, they create a decontextualization module that removes the surrounding context from the extracted claims, making them more concise and easier to fact-check.
By automating these steps, the researchers aim to make the fact-checking process more efficient and scalable, as humans can spend less time sifting through documents and more time verifying the accuracy of the extracted claims. This could be particularly useful for fact-checking efforts focused on online misinformation, where the volume of content can be overwhelming.
Technical Explanation
The paper introduces a document-level claim extraction and decontextualization approach for fact-checking. The authors first develop a novel document-level claim extraction model that can identify claims within an entire document, rather than just at the sentence level. This is an important advancement over previous claim detection methods that focused on individual sentences.
The document-level claim extraction model is trained using a combination of supervised and unsupervised learning techniques. It leverages various linguistic and structural features to identify claims, taking into account the overall context and organization of the document. The extracted claims are then passed through a decontextualization module, which removes surrounding details and presents the claims in a more concise, standalone form.
The decontextualized claims can then be more easily verified through fact-checking processes, as the relevant information is distilled and separated from extraneous details. This approach aims to improve the efficiency and scalability of fact-checking, which is particularly important in the context of online misinformation.
Critical Analysis
The paper presents a promising approach to addressing the challenges of fact-checking, but it also acknowledges several limitations and areas for further research.
One key limitation is the reliance on supervised learning for the claim extraction model, which requires a substantial amount of labeled training data. The authors note that obtaining high-quality annotations for factual claims can be a significant challenge.
Additionally, the decontextualization module may not always be able to capture the nuances and subtleties of a claim, as some context may be necessary to fully understand its meaning and implications. Further research could explore more sophisticated techniques for preserving relevant contextual information while still simplifying the claims.
Another area for improvement is the evaluation of the system's performance. The authors use standard metrics like precision and recall, but it would be valuable to also assess the system's impact on the overall fact-checking process, such as the time and effort saved by human fact-checkers.
Despite these limitations, the document-level claim extraction and decontextualization approach represents an important step forward in automating and streamlining the fact-checking process. As the volume of information continues to grow, especially online, developing efficient and scalable tools for verifying the accuracy of claims will become increasingly crucial.
Conclusion
This paper introduces a novel approach to facilitating fact-checking by automating the extraction of claims from documents and presenting them in a decontextualized form. The key innovations are the document-level claim extraction model and the decontextualization module, which work together to distill the essential information needed for effective fact-checking.
While the approach has some limitations, it represents a significant advancement in the field of automated fact-checking. By reducing the burden on human fact-checkers and enabling them to focus on the verification process rather than information retrieval, this technology has the potential to enhance the reliability and scalability of fact-checking efforts, particularly in the context of online misinformation. Further research and refinement of the techniques could lead to even more impactful applications in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Document-level Claim Extraction and Decontextualisation for Fact-Checking
Zhenyun Deng, Michael Schlichtkrull, Andreas Vlachos
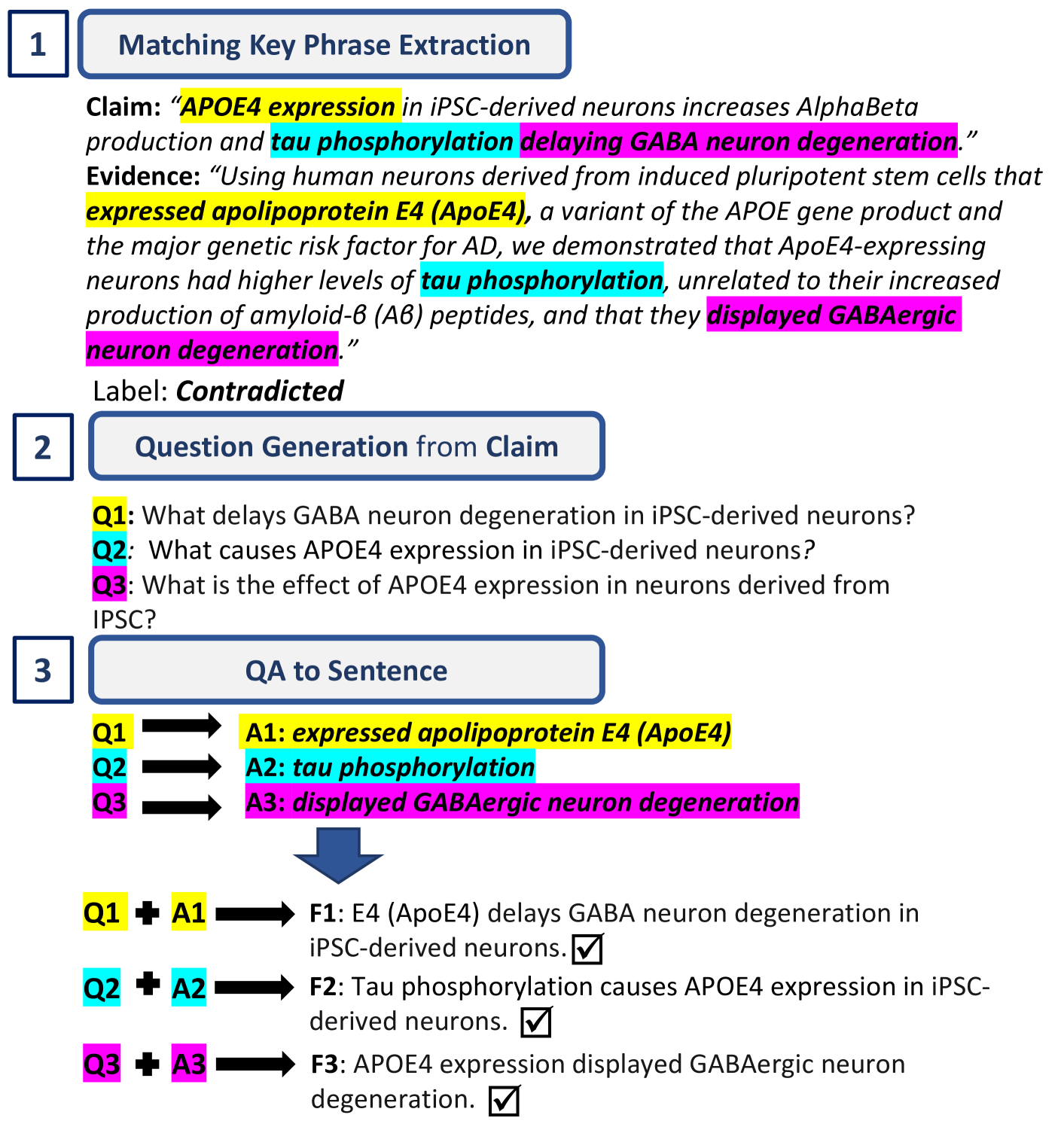
Selecting which claims to check is a time-consuming task for human fact-checkers, especially from documents consisting of multiple sentences and containing multiple claims. However, existing claim extraction approaches focus more on identifying and extracting claims from individual sentences, e.g., identifying whether a sentence contains a claim or the exact boundaries of the claim within a sentence. In this paper, we propose a method for document-level claim extraction for fact-checking, which aims to extract check-worthy claims from documents and decontextualise them so that they can be understood out of context. Specifically, we first recast claim extraction as extractive summarization in order to identify central sentences from documents, then rewrite them to include necessary context from the originating document through sentence decontextualisation. Evaluation with both automatic metrics and a fact-checking professional shows that our method is able to extract check-worthy claims from documents more accurately than previous work, while also improving evidence retrieval.
Read more6/13/2024
0
Robust Claim Verification Through Fact Detection
Nazanin Jafari, James Allan
Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.
Read more7/29/2024
🌐
0
Complex Claim Verification with Evidence Retrieved in the Wild
Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, Eunsol Choi
Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.
Read more6/18/2024
📈
0
A Knowledge Enhanced Learning and Semantic Composition Model for Multi-Claim Fact Checking
Shuai Wang, Penghui Wei, Qingchao Kong, Wenji Mao
To inhibit the spread of rumorous information and its severe consequences, traditional fact checking aims at retrieving relevant evidence to verify the veracity of a given claim. Fact checking methods typically use knowledge graphs (KGs) as external repositories and develop reasoning mechanism to retrieve evidence for verifying the triple claim. However, existing methods only focus on verifying a single claim. As real-world rumorous information is more complex and a textual statement is often composed of multiple clauses (i.e. represented as multiple claims instead of a single one), multiclaim fact checking is not only necessary but more important for practical applications. Although previous methods for verifying a single triple can be applied repeatedly to verify multiple triples one by one, they ignore the contextual information implied in a multi-claim statement and could not learn the rich semantic information in the statement as a whole. In this paper, we propose an end-to-end knowledge enhanced learning and verification method for multi-claim fact checking. Our method consists of two modules, KG-based learning enhancement and multi-claim semantic composition. To fully utilize the contextual information, the KG-based learning enhancement module learns the dynamic context-specific representations via selectively aggregating relevant attributes of entities. To capture the compositional semantics of multiple triples, the multi-claim semantic composition module constructs the graph structure to model claim-level interactions, and integrates global and salient local semantics with multi-head attention. Experimental results on a real-world dataset and two benchmark datasets show the effectiveness of our method for multi-claim fact checking over KG.
Read more7/30/2024