$T^2$ of Thoughts: Temperature Tree Elicits Reasoning in Large Language Models
2405.14075
0
0
💬
Abstract
Large Language Models (LLMs) have emerged as powerful tools in artificial intelligence, especially in complex decision-making scenarios, but their static problem-solving strategies often limit their adaptability to dynamic environments. We explore the enhancement of reasoning capabilities in LLMs through Temperature Tree ($T^2$) prompting via Particle Swarm Optimization, termed as $T^2$ of Thoughts ($T^2oT$). The primary focus is on enhancing decision-making processes by dynamically adjusting search parameters, especially temperature, to improve accuracy without increasing computational demands. We empirically validate that our hybrid $T^2oT$ approach yields enhancements in, single-solution accuracy, multi-solution generation and text generation quality. Our findings suggest that while dynamic search depth adjustments based on temperature can yield mixed results, a fixed search depth, when coupled with adaptive capabilities of $T^2oT$, provides a more reliable and versatile problem-solving strategy. This work highlights the potential for future explorations in optimizing algorithmic interactions with foundational language models, particularly illustrated by our development for the Game of 24 and Creative Writing tasks.
Create account to get full access
Overview
- Large Language Models (LLMs) are powerful AI tools, but their static problem-solving strategies limit their adaptability to dynamic environments.
- The researchers explore enhancing LLM reasoning capabilities through a technique called Temperature Tree ($T^2$) Prompting via Particle Swarm Optimization, termed as $T^2$ of Thoughts ($T^2oT$).
- The focus is on improving decision-making by dynamically adjusting search parameters, especially temperature, to enhance accuracy without increasing computational demands.
- The researchers validate that their hybrid $T^2oT$ approach yields enhancements in single-solution accuracy, multi-solution generation, and text generation quality.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence (AI) tools that can tackle complex problems. However, these models often use static problem-solving strategies, which can limit their ability to adapt to changing environments. To address this, the researchers explored a technique called Temperature Tree ($T^2$) Prompting via Particle Swarm Optimization, or $T^2$ of Thoughts ($T^2oT$), to enhance the reasoning capabilities of LLMs.
The key idea is to dynamically adjust the search parameters, especially the temperature, to improve the accuracy of the LLM's decision-making without increasing the computational demands. Temperature is a parameter that affects the exploration-exploitation balance in the LLM's search process. By dynamically adjusting the temperature, the researchers aimed to find the right balance between exploring new possibilities and exploiting the most promising solutions.
The researchers empirically validated that their hybrid $T^2oT$ approach led to improvements in three areas: single-solution accuracy, multi-solution generation, and text generation quality. This suggests that while dynamic adjustments to search depth based on temperature can produce mixed results, a fixed search depth combined with the adaptive capabilities of $T^2oT$ provides a more reliable and versatile problem-solving strategy.
This work highlights the potential for future research in optimizing the interactions between algorithms and foundational language models, as demonstrated by the researchers' developments for the Game of 24 and Creative Writing tasks.
Technical Explanation
The researchers explore the enhancement of reasoning capabilities in large language models (LLMs) through a technique called Temperature Tree ($T^2$) Prompting via Particle Swarm Optimization, which they term as $T^2$ of Thoughts ($T^2oT$). The primary focus is on improving decision-making processes by dynamically adjusting search parameters, especially temperature, to enhance accuracy without increasing computational demands.
The $T^2oT$ approach involves using particle swarm optimization (PSO) to dynamically adjust the temperature parameter in the LLM's search process. Temperature is a key parameter that affects the exploration-exploitation balance, with higher temperatures promoting exploration and lower temperatures favoring exploitation. By dynamically adjusting the temperature, the researchers aim to find the right balance to improve the LLM's decision-making accuracy.
The researchers empirically validate their $T^2oT$ approach on two tasks: the Game of 24 and Creative Writing. For the Game of 24 task, the LLM is required to find a sequence of arithmetic operations that will transform a set of four numbers into the target number 24. For the Creative Writing task, the LLM is tasked with generating high-quality creative text.
The results show that the $T^2oT$ approach yields enhancements in single-solution accuracy, multi-solution generation, and text generation quality compared to the baseline LLM. Interestingly, the researchers found that while dynamic adjustments to search depth based on temperature can produce mixed results, a fixed search depth combined with the adaptive capabilities of $T^2oT$ provides a more reliable and versatile problem-solving strategy.
Critical Analysis
The researchers provide a thoughtful exploration of enhancing reasoning capabilities in large language models (LLMs) through their $T^2$ of Thoughts ($T^2oT$) approach. The focus on dynamically adjusting search parameters, particularly temperature, to improve decision-making accuracy without increasing computational demands is a valuable contribution.
One potential limitation of the study is the specific tasks used for evaluation, the Game of 24 and Creative Writing. While these tasks provide a good starting point, it would be helpful to see the $T^2oT$ approach evaluated on a broader range of tasks to assess its generalizability.
Additionally, the researchers mention that dynamic adjustments to search depth based on temperature can yield mixed results, but a fixed search depth coupled with the adaptive capabilities of $T^2oT$ provides a more reliable and versatile problem-solving strategy. It would be interesting to explore the reasoning behind this finding and investigate the tradeoffs between dynamic and fixed search depth adjustments in more detail.
[Further research could also explore the interplay between the $T^2oT$ approach and other techniques for improving LLM reasoning, such as temporal reasoning or multi-step reasoning across languages.] Additionally, investigating the role of temperature as a creativity parameter in large language models could provide valuable insights.
Overall, the researchers have presented a promising approach for enhancing LLM reasoning capabilities, and their findings highlight the potential for further exploration in optimizing algorithmic interactions with foundational language models, as demonstrated by their work on the Game of 24 and Creative Writing tasks.
Conclusion
The researchers have explored the enhancement of reasoning capabilities in large language models (LLMs) through a technique called Temperature Tree ($T^2$) Prompting via Particle Swarm Optimization, termed as $T^2$ of Thoughts ($T^2oT$). Their key focus was on improving decision-making by dynamically adjusting search parameters, especially temperature, to enhance accuracy without increasing computational demands.
The empirical validation of the $T^2oT$ approach showed enhancements in single-solution accuracy, multi-solution generation, and text generation quality, suggesting that while dynamic search depth adjustments based on temperature can yield mixed results, a fixed search depth combined with the adaptive capabilities of $T^2oT$ provides a more reliable and versatile problem-solving strategy.
This work highlights the potential for future explorations in optimizing algorithmic interactions with foundational language models, particularly illustrated by the researchers' developments for the Game of 24 and Creative Writing tasks. As the field of AI continues to advance, techniques like $T^2oT$ could play a significant role in enhancing the reasoning capabilities of large language models and expanding their applications in complex decision-making scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Synergy-of-Thoughts: Eliciting Efficient Reasoning in Hybrid Language Models
Yu Shang, Yu Li, Fengli Xu, Yong Li
0
0
Large language models (LLMs) have shown impressive emergent abilities in a wide range of tasks, but still face challenges in handling complex reasoning problems. Previous works like chain-of-thought (CoT) and tree-of-thoughts (ToT) have predominately focused on enhancing accuracy, but overlook the rapidly increasing token cost, which could be particularly problematic for open-ended real-world tasks with huge solution spaces. Motivated by the dual process theory of human cognition, we propose Synergy of Thoughts (SoT) to unleash the synergistic potential of hybrid LLMs for efficient reasoning. By default, SoT uses smaller-scale language models to generate multiple low-cost reasoning thoughts, which resembles the parallel intuitions produced by System 1. If these intuitions exhibit conflicts, SoT will invoke the reflective reasoning of scaled-up language models to emulate the intervention of System 2, which will override the intuitive thoughts and rectify the reasoning process. This framework is model-agnostic and training-free, which can be flexibly implemented with various off-the-shelf LLMs. Experiments on six representative reasoning tasks show that SoT substantially reduces the token cost by 38.3%-75.1%, and simultaneously achieves state-of-the-art reasoning accuracy and solution diversity. Notably, the average token cost reduction on open-ended tasks reaches up to 69.1%. Code repo with all prompts will be released upon publication.
5/24/2024
🎯
Can Github issues be solved with Tree Of Thoughts?
Ricardo La Rosa, Corey Hulse, Bangdi Liu
0
0
While there have been extensive studies in code generation by large language models (LLM), where benchmarks like HumanEval have been surpassed with an impressive 96.3% success rate, these benchmarks predominantly judge a model's performance on basic function-level code generation and lack the critical thinking and concept of scope required of real-world scenarios such as solving GitHub issues. This research introduces the application of the Tree of Thoughts (ToT) language model reasoning framework for enhancing the decision-making and problem-solving abilities of LLMs for this complex task. Compared to traditional input-output (IO) prompting and Retrieval Augmented Generation (RAG) techniques, ToT is designed to improve performance by facilitating a structured exploration of multiple reasoning trajectories and enabling self-assessment of potential solutions. We experimentally deploy ToT in tackling a Github issue contained within an instance of the SWE-bench. However, our results reveal that the ToT framework alone is not enough to give LLMs the critical reasoning capabilities to outperform existing methods. In this paper we analyze the potential causes of these shortcomings and identify key areas for improvement such as deepening the thought process and introducing agentic capabilities. The insights of this research are aimed at informing future directions for refining the application of ToT and better harnessing the potential of LLMs in real-world problem-solving scenarios.
5/24/2024
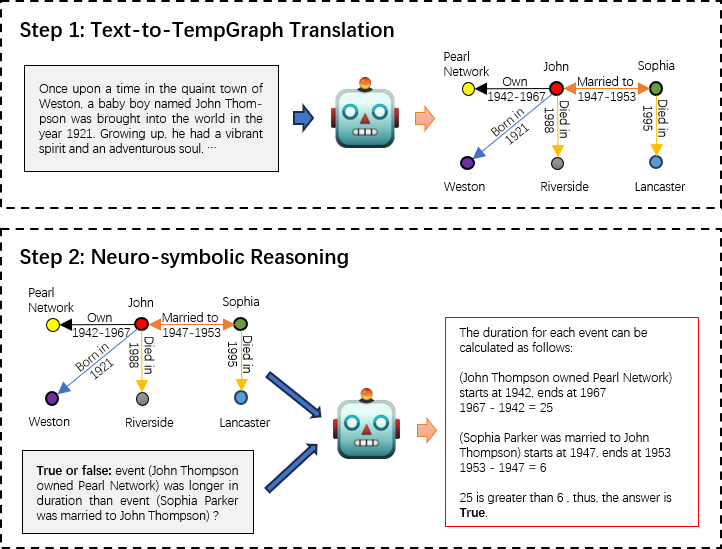
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
6/12/2024
📊
Empowering Multi-step Reasoning across Languages via Tree-of-Thoughts
Leonardo Ranaldi, Giulia Pucci, Federico Ranaldi, Elena Sofia Ruzzetti, Fabio Massimo Zanzotto
0
0
Reasoning methods, best exemplified by the well-known Chain-of-Thought (CoT), empower the reasoning abilities of Large Language Models (LLMs) by eliciting them to solve complex tasks in a step-by-step manner. Although they are achieving significant success, the ability to deliver multi-step reasoning remains limited to English because of the imbalance in the distribution of pre-training data, which makes other languages a barrier. In this paper, we propose Cross-lingual Tree-of-Thoughts (Cross-ToT), a method for aligning Cross-lingual CoT reasoning across languages. The proposed method, through a self-consistent cross-lingual prompting mechanism inspired by the Tree-of-Thoughts approach, provides multi-step reasoning paths in different languages that, during the steps, lead to the final solution. Experimental evaluations show that our method significantly outperforms existing prompting methods by reducing the number of interactions and achieving state-of-the-art performance.
6/24/2024