Zyda: A 1.3T Dataset for Open Language Modeling
2406.01981
0
0
Abstract
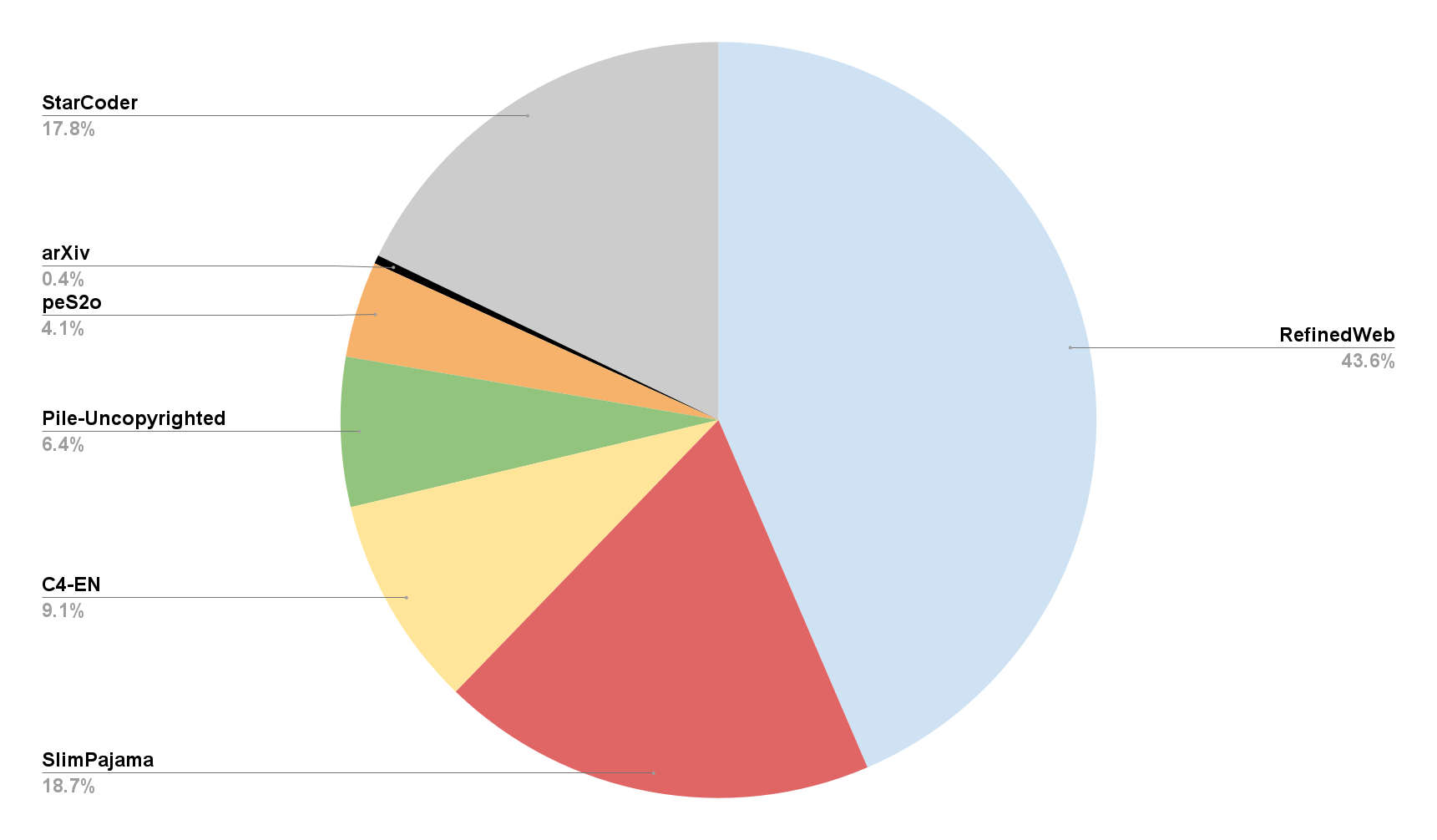
The size of large language models (LLMs) has scaled dramatically in recent years and their computational and data requirements have surged correspondingly. State-of-the-art language models, even at relatively smaller sizes, typically require training on at least a trillion tokens. This rapid advancement has eclipsed the growth of open-source datasets available for large-scale LLM pretraining. In this paper, we introduce Zyda (Zyphra Dataset), a dataset under a permissive license comprising 1.3 trillion tokens, assembled by integrating several major respected open-source datasets into a single, high-quality corpus. We apply rigorous filtering and deduplication processes, both within and across datasets, to maintain and enhance the quality derived from the original datasets. Our evaluations show that Zyda not only competes favorably with other open datasets like Dolma, FineWeb, and RefinedWeb, but also substantially improves the performance of comparable models from the Pythia suite. Our rigorous data processing methods significantly enhance Zyda's effectiveness, outperforming even the best of its constituent datasets when used independently.
Create account to get full access
Overview
- This paper introduces Zyda, a 1.3 trillion token dataset for training large language models (LLMs).
- Zyda is designed to support open-ended language modeling tasks, going beyond the narrow domain of traditional language modeling datasets.
- The dataset covers a diverse range of topics and genres, including web pages, books, academic papers, and social media.
- The authors argue that Zyda enables the development of more capable and robust LLMs that can handle a wide variety of real-world language tasks.
Plain English Explanation
The researchers who created the Zyda dataset wanted to build better language models that could understand and generate human language in a more natural and flexible way. Existing language modeling datasets tend to be narrow in scope, focusing on specific domains like news articles or social media posts. In contrast, Zyda: A 1.3T Dataset for Open Language Modeling is a much larger and more diverse dataset, with over 1.3 trillion tokens (units of text) from a wide range of sources, including websites, books, academic papers, and social media.
The goal of the Zyda dataset is to support the development of advanced language models that can handle open-ended tasks, like answering questions, summarizing text, or generating coherent stories. By exposing these models to such a large and varied corpus of language data, the researchers hope to create systems that are more capable, flexible, and robust than those trained on more limited datasets.
Technical Explanation
The Zyda dataset was constructed by aggregating text from a variety of web-based sources, including websites, books, academic papers, and social media. The dataset covers a broad range of topics, from science and technology to arts and culture, and includes both formal and informal language styles.
To process the raw text data, the researchers employed various techniques, such as language detection, deduplication, and content filtering, to ensure the quality and consistency of the dataset. The final Zyda dataset contains over 1.3 trillion tokens, making it one of the largest publicly available language modeling datasets to date.
The authors argue that the size and diversity of Zyda will enable the development of more capable and robust large language models (LLMs) that can handle a wide variety of real-world language tasks. They provide several use cases, such as question answering, text summarization, and open-ended story generation, to demonstrate the potential of their dataset.
Critical Analysis
The Zyda dataset represents a significant contribution to the field of language modeling, as it provides a large and diverse corpus of text data to train advanced LLMs. The authors have made a convincing case for the importance of developing models that can handle open-ended language tasks, as opposed to the more narrow domains covered by many existing datasets.
However, the paper does not delve into potential limitations or caveats of the Zyda dataset. For example, it would be valuable to understand the representational biases that may be present in the dataset, as well as any ethical considerations around the use of web-scraped data. Additionally, the authors could have provided more details on the specific techniques used for data processing and cleaning, which would allow for a more comprehensive evaluation of the dataset's quality and suitability for different use cases.
Nonetheless, the Zyda dataset is a valuable resource for the research community, and the authors' focus on open-ended language modeling is a promising direction for the field. As LLMs continue to advance, it will be important to carefully consider the limitations and potential risks of these systems, while also leveraging datasets like Zyda to push the boundaries of what is possible.
Conclusion
The Zyda dataset represents a significant advance in the field of language modeling, providing a large and diverse corpus of text data to support the development of more capable and robust large language models. By focusing on open-ended language tasks, the researchers behind Zyda are working to create systems that can better understand and generate human language in a natural and flexible way.
While the paper does not address all potential limitations or concerns, the Zyda dataset is a valuable resource that will undoubtedly contribute to the ongoing progress in natural language processing and generation. As the field continues to evolve, it will be important to carefully consider the ethical and societal implications of these powerful language models, while also harnessing their potential to tackle a wide range of real-world language challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A. Smith, Hannaneh Hajishirzi, Iz Beltagy, Dirk Groeneveld, Jesse Dodge, Kyle Lo
0
0
Information about pretraining corpora used to train the current best-performing language models is seldom discussed: commercial models rarely detail their data, and even open models are often released without accompanying training data or recipes to reproduce them. As a result, it is challenging to conduct and advance scientific research on language modeling, such as understanding how training data impacts model capabilities and limitations. To facilitate scientific research on language model pretraining, we curate and release Dolma, a three-trillion-token English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. We extensively document Dolma, including its design principles, details about its construction, and a summary of its contents. We present analyses and experimental results on intermediate states of Dolma to share what we have learned about important data curation practices. Finally, we open-source our data curation toolkit to enable reproduction of our work as well as support further research in large-scale data curation.
6/10/2024

New!YuLan: An Open-source Large Language Model
Yutao Zhu, Kun Zhou, Kelong Mao, Wentong Chen, Yiding Sun, Zhipeng Chen, Qian Cao, Yihan Wu, Yushuo Chen, Feng Wang, Lei Zhang, Junyi Li, Xiaolei Wang, Lei Wang, Beichen Zhang, Zican Dong, Xiaoxue Cheng, Yuhan Chen, Xinyu Tang, Yupeng Hou, Qiangqiang Ren, Xincheng Pang, Shufang Xie, Wayne Xin Zhao, Zhicheng Dou, Jiaxin Mao, Yankai Lin, Ruihua Song, Jun Xu, Xu Chen, Rui Yan, Zhewei Wei, Di Hu, Wenbing Huang, Ze-Feng Gao, Yueguo Chen, Weizheng Lu, Ji-Rong Wen
0
0
Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
7/1/2024
💬
EDA Corpus: A Large Language Model Dataset for Enhanced Interaction with OpenROAD
Bing-Yue Wu, Utsav Sharma, Sai Rahul Dhanvi Kankipati, Ajay Yadav, Bintu Kappil George, Sai Ritish Guntupalli, Austin Rovinski, Vidya A. Chhabria
0
0
Large language models (LLMs) serve as powerful tools for design, providing capabilities for both task automation and design assistance. Recent advancements have shown tremendous potential for facilitating LLM integration into the chip design process; however, many of these works rely on data that are not publicly available and/or not permissively licensed for use in LLM training and distribution. In this paper, we present a solution aimed at bridging this gap by introducing an open-source dataset tailored for OpenROAD, a widely adopted open-source EDA toolchain. The dataset features over 1000 data points and is structured in two formats: (i) a pairwise set comprised of question prompts with prose answers, and (ii) a pairwise set comprised of code prompts and their corresponding OpenROAD scripts. By providing this dataset, we aim to facilitate LLM-focused research within the EDA domain. The dataset is available at https://github.com/OpenROAD-Assistant/EDA-Corpus.
5/14/2024
🖼️
Tagengo: A Multilingual Chat Dataset
Peter Devine
0
0
Open source large language models (LLMs) have shown great improvements in recent times. However, many of these models are focused solely on popular spoken languages. We present a high quality dataset of more than 70k prompt-response pairs in 74 languages which consist of human generated prompts and synthetic responses. We use this dataset to train a state-of-the-art open source English LLM to chat multilingually. We evaluate our model on MT-Bench chat benchmarks in 6 languages, finding that our multilingual model outperforms previous state-of-the-art open source LLMs across each language. We further find that training on more multilingual data is beneficial to the performance in a chosen target language (Japanese) compared to simply training on only data in that language. These results indicate the necessity of training on large amounts of high quality multilingual data to make a more accessible LLM.
5/22/2024