Domain adaptation in small-scale and heterogeneous biological datasets

0
🔍
Sign in to get full access
Overview
- Machine learning is becoming increasingly important in biology, used for building predictive models, discovering patterns, and investigating biological problems.
- However, models trained on one dataset often do not generalize well to other datasets due to differences in statistical properties, which can stem from technical or biological differences between the populations studied.
- Domain adaptation, a type of transfer learning, can help align the statistical distributions of features and samples across different datasets so that similar models can be applied.
- Most state-of-the-art domain adaptation methods are designed for large-scale data like text and images, while biological datasets often have small sample sizes and highly heterogeneous feature spaces.
Plain English Explanation
Machine learning is a powerful tool that is becoming increasingly important in biology. Researchers use machine learning techniques to build predictive models, uncover patterns, and investigate various biological problems. However, there's a catch - models trained on one dataset often don't work well when applied to a different dataset, even if the data is related.
This can happen because the datasets may have different statistical properties, which can be due to technical differences in how the data was collected or relevant biological differences between the populations being studied. For example, a model trained on data from one lab might not perform well on data from a different lab, even if they're studying the same biological system.
Domain adaptation is a type of transfer learning that can help address this issue. The idea is to align the statistical distributions of the features and samples across the different datasets, so that a similar model can be applied successfully. This helps the model "adapt" to the new dataset, even if it has different statistical properties.
However, most state-of-the-art domain adaptation methods are designed to work with large-scale datasets, like text and images. Biological datasets, on the other hand, often have relatively small sample sizes and highly complex, heterogeneous feature spaces. This presents some unique challenges that the current domain adaptation techniques may not be well-equipped to handle.
Technical Explanation
The paper reviews the application of domain adaptation techniques in the context of small-scale and highly heterogeneous biological data. Domain adaptation is a type of transfer learning that aims to align the statistical distributions of features and samples across different datasets, enabling the application of similar models despite differences in the underlying data.
While domain adaptation methods have seen success in large-scale domains like text and images, biological datasets often pose unique challenges. These datasets typically have small sample sizes and highly complex, heterogeneous feature spaces, which can be difficult for many state-of-the-art domain adaptation approaches to handle effectively.
The paper discusses the benefits and challenges of using domain adaptation in biological research, and critically examines some key representative methodologies. For example, Vision Transformers for Domain Adaptation and Generalization explores the use of vision transformers for domain adaptation in the context of image classification. Overcoming Negative Transfer by Online Selection of Distant Domains proposes a technique for selecting relevant distant domains to mitigate negative transfer in domain adaptation.
Additionally, the paper highlights the need for more customized domain adaptation approaches that can effectively handle the unique characteristics of biological datasets. Domain Generalization through Meta-Learning and Domain Adaptation for Intent Classification Systems are discussed as potential avenues for developing more specialized domain adaptation techniques for biological applications.
Critical Analysis
The paper rightly identifies the challenges posed by the unique characteristics of biological datasets, such as small sample sizes and high feature heterogeneity, which can limit the effectiveness of many existing domain adaptation methods. The authors emphasize the need for more customized approaches that can better handle these complexities.
One potential limitation of the review is that it does not delve deeply into the specific technical details of the representative domain adaptation methodologies discussed. A more thorough examination of the strengths, weaknesses, and underlying principles of these methods could provide readers with a more comprehensive understanding of the current state of the art.
Additionally, the paper does not explore potential synergies between domain adaptation and other emerging techniques in computational biology, such as meta-learning or few-shot learning. Investigating how these complementary approaches could be combined to address the challenges of small-scale, heterogeneous biological data could be a fruitful area for future research.
Overall, the paper makes a compelling case for the incorporation of domain adaptation techniques into the computational biologist's toolkit, while also highlighting the need for further development of customized approaches tailored to the unique characteristics of biological datasets.
Conclusion
This review paper highlights the growing importance of machine learning in modern biology and the challenges posed by the lack of generalizability of models trained on one dataset to other datasets. The authors discuss how domain adaptation, a type of transfer learning, can help align the statistical distributions across different datasets, enabling the application of similar models despite differences in the underlying data.
However, the authors argue that most state-of-the-art domain adaptation methods are designed for large-scale data, while biological datasets often have small sample sizes and highly heterogeneous feature spaces. The paper critically examines some key representative domain adaptation methodologies and advocates for the development of more customized approaches that can effectively handle the unique characteristics of biological data.
By incorporating domain adaptation techniques into the computational biologist's toolkit, researchers may be able to build more robust and generalizable models, leading to new insights and advancements in the field of biology. The authors encourage further research in this direction, with the goal of bridging the gap between the unique challenges of biological data and the capabilities of modern machine learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Domain adaptation in small-scale and heterogeneous biological datasets
Seyedmehdi Orouji, Martin C. Liu, Tal Korem, Megan A. K. Peters
Machine learning techniques are steadily becoming more important in modern biology, and are used to build predictive models, discover patterns, and investigate biological problems. However, models trained on one dataset are often not generalizable to other datasets from different cohorts or laboratories, due to differences in the statistical properties of these datasets. These could stem from technical differences, such as the measurement technique used, or from relevant biological differences between the populations studied. Domain adaptation, a type of transfer learning, can alleviate this problem by aligning the statistical distributions of features and samples among different datasets so that similar models can be applied across them. However, a majority of state-of-the-art domain adaptation methods are designed to work with large-scale data, mostly text and images, while biological datasets often suffer from small sample sizes, and possess complexities such as heterogeneity of the feature space. This Review aims to synthetically discuss domain adaptation methods in the context of small-scale and highly heterogeneous biological data. We describe the benefits and challenges of domain adaptation in biological research and critically discuss some of its objectives, strengths, and weaknesses through key representative methodologies. We argue for the incorporation of domain adaptation techniques to the computational biologist's toolkit, with further development of customized approaches.
Read more5/30/2024
🤿
0
More is Better: Deep Domain Adaptation with Multiple Sources
Sicheng Zhao, Hui Chen, Hu Huang, Pengfei Xu, Guiguang Ding
In many practical applications, it is often difficult and expensive to obtain large-scale labeled data to train state-of-the-art deep neural networks. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) aims to address this problem by aligning the distributions between the source and target domains. Multi-source domain adaptation (MDA) is a powerful and practical extension in which the labeled data may be collected from multiple sources with different distributions. In this survey, we first define various MDA strategies. Then we systematically summarize and compare modern MDA methods in the deep learning era from different perspectives, followed by commonly used datasets and a brief benchmark. Finally, we discuss future research directions for MDA that are worth investigating.
Read more5/3/2024
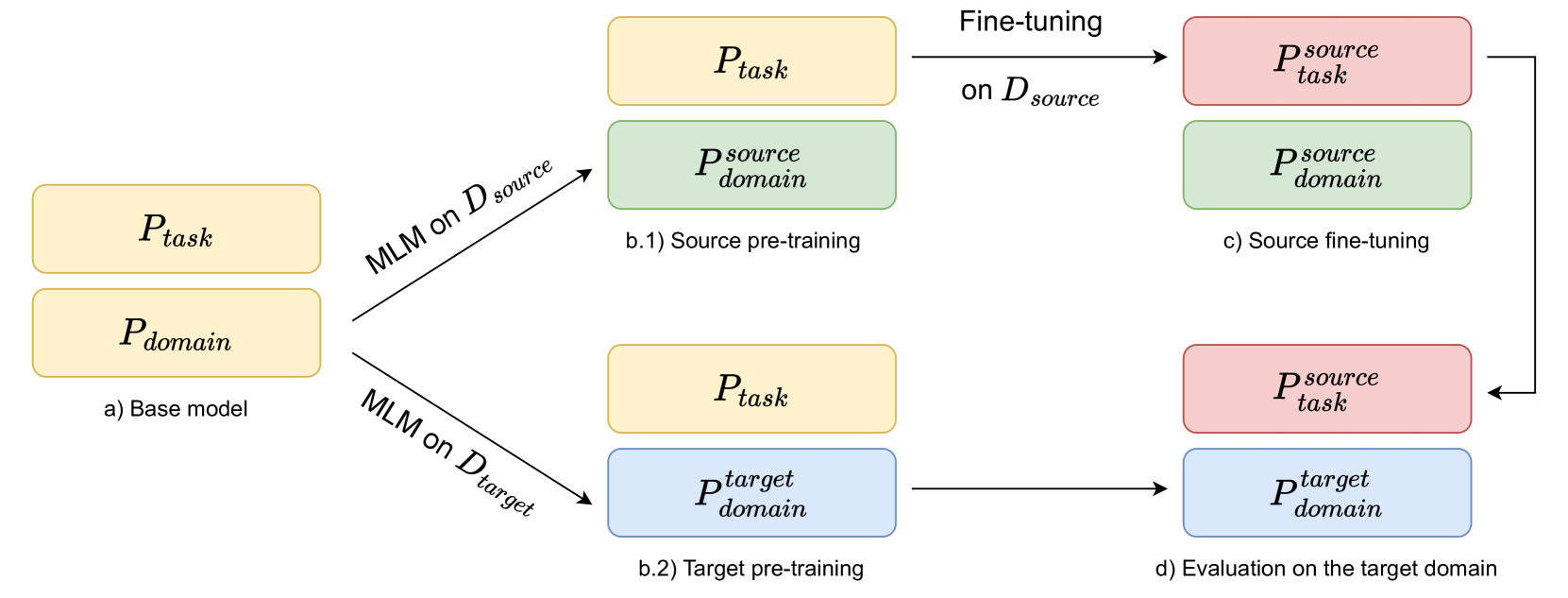
0
Simple Domain Adaptation for Sparse Retrievers
Mathias Vast, Yuxuan Zong, Basile Van Cooten, Benjamin Piwowarski, Laure Soulier
In Information Retrieval, and more generally in Natural Language Processing, adapting models to specific domains is conducted through fine-tuning. Despite the successes achieved by this method and its versatility, the need for human-curated and labeled data makes it impractical to transfer to new tasks, domains, and/or languages when training data doesn't exist. Using the model without training (zero-shot) is another option that however suffers an effectiveness cost, especially in the case of first-stage retrievers. Numerous research directions have emerged to tackle these issues, most of them in the context of adapting to a task or a language. However, the literature is scarcer for domain (or topic) adaptation. In this paper, we address this issue of cross-topic discrepancy for a sparse first-stage retriever by transposing a method initially designed for language adaptation. By leveraging pre-training on the target data to learn domain-specific knowledge, this technique alleviates the need for annotated data and expands the scope of domain adaptation. Despite their relatively good generalization ability, we show that even sparse retrievers can benefit from our simple domain adaptation method.
Read more7/8/2024
🔄
0
A Recent Survey of Heterogeneous Transfer Learning
Runxue Bao, Yiming Sun, Yuhe Gao, Jindong Wang, Qiang Yang, Zhi-Hong Mao, Ye Ye
The application of transfer learning, leveraging knowledge from source domains to enhance model performance in a target domain, has significantly grown, supporting diverse real-world applications. Its success often relies on shared knowledge between domains, typically required in these methodologies. Commonly, methods assume identical feature and label spaces in both domains, known as homogeneous transfer learning. However, this is often impractical as source and target domains usually differ in these spaces, making precise data matching challenging and costly. Consequently, heterogeneous transfer learning (HTL), which addresses these disparities, has become a vital strategy in various tasks. In this paper, we offer an extensive review of over 60 HTL methods, covering both data-based and model-based approaches. We describe the key assumptions and algorithms of these methods and systematically categorize them into instance-based, feature representation-based, parameter regularization, and parameter tuning techniques. Additionally, we explore applications in natural language processing, computer vision, multimodal learning, and biomedicine, aiming to deepen understanding and stimulate further research in these areas. Our paper includes recent advancements in HTL, such as the introduction of transformer-based models and multimodal learning techniques, ensuring the review captures the latest developments in the field. We identify key limitations in current HTL studies and offer systematic guidance for future research, highlighting areas needing further exploration and suggesting potential directions for advancing the field.
Read more7/19/2024