Domain adaptive pose estimation via multi-level alignment

0
🤔
Sign in to get full access
Overview
- The paper proposes a multi-level domain adaptation approach to enable deep models trained on synthetic datasets to perform well on real-world datasets for pose estimation tasks.
- The key idea is to align the source and target domains at the image, feature, and pose levels, addressing the domain gap from multiple perspectives.
- Experimental results show significant improvements in human and animal pose estimation compared to previous state-of-the-art methods.
Plain English Explanation
Pose estimation is the task of predicting the positions of body parts, such as joints, in an image. This is an important problem in computer vision with applications in areas like human-computer interaction and robotics. However, training deep learning models for pose estimation can be challenging because they often require large amounts of labeled, real-world data, which can be expensive to collect.
To address this, researchers have explored
In this paper, the authors propose a
The experimental results show that this multi-level alignment strategy leads to significant improvements in both human and animal pose estimation, outperforming previous state-of-the-art methods by up to 2.4% and 3.1%, respectively. This suggests that tackling the domain gap from multiple perspectives can be an effective way to enable models trained on synthetic data to perform well in the real world.
Technical Explanation
The core idea of the proposed approach is to align the source (synthetic) and target (real-world) domains at multiple levels: image, feature, and pose.
At the
At the
Finally, at the
The authors evaluate their approach on both human and animal pose estimation tasks. For human pose estimation, they use the MPII and COCO datasets, and for animal pose estimation, they use datasets for dogs and sheep. The experimental results show that the proposed multi-level alignment strategy outperforms previous state-of-the-art methods by up to 2.4% for human pose and up to 3.1% for animal pose.
Critical Analysis
The authors have provided a comprehensive and technically sound approach to address the domain gap in pose estimation tasks. By aligning the source and target domains at multiple levels, they have been able to achieve significant performance improvements over previous methods.
One potential limitation of the study is that it only evaluates the approach on a limited set of datasets and tasks. It would be interesting to see how the multi-level alignment strategy performs on a wider range of pose estimation problems, such as 3D pose estimation or multi-person pose estimation.
Additionally, the paper does not provide much analysis on the relative importance of the different alignment levels (image, feature, and pose). It would be useful to understand which components contribute the most to the overall performance improvement and whether certain levels are more critical than others in different scenarios.
Despite these minor limitations, the paper presents a well-designed and effective approach to tackle the domain adaptation problem in pose estimation. The multi-level alignment strategy is a promising direction for future research and could have significant implications for enabling the deployment of pose estimation models in real-world applications.
Conclusion
This paper proposes a novel multi-level domain adaptation approach for pose estimation, which aligns the source and target domains at the image, feature, and pose levels. By addressing the domain gap from multiple perspectives, the authors are able to significantly improve the performance of deep learning models trained on synthetic data when applied to real-world datasets.
The experimental results demonstrate the effectiveness of this strategy, with improvements of up to 2.4% for human pose estimation and up to 3.1% for animal pose estimation compared to previous state-of-the-art methods. This work highlights the importance of considering domain adaptation at multiple levels to enable the successful deployment of computer vision models in practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Domain adaptive pose estimation via multi-level alignment
Yugan Chen, Lin Zhao, Yalong Xu, Honglei Zu, Xiaoqi An, Guangyu Li
Domain adaptive pose estimation aims to enable deep models trained on source domain (synthesized) datasets produce similar results on the target domain (real-world) datasets. The existing methods have made significant progress by conducting image-level or feature-level alignment. However, only aligning at a single level is not sufficient to fully bridge the domain gap and achieve excellent domain adaptive results. In this paper, we propose a multi-level domain adaptation aproach, which aligns different domains at the image, feature, and pose levels. Specifically, we first utilize image style transer to ensure that images from the source and target domains have a similar distribution. Subsequently, at the feature level, we employ adversarial training to make the features from the source and target domains preserve domain-invariant characeristics as much as possible. Finally, at the pose level, a self-supervised approach is utilized to enable the model to learn diverse knowledge, implicitly addressing the domain gap. Experimental results demonstrate that significant imrovement can be achieved by the proposed multi-level alignment method in pose estimation, which outperforms previous state-of-the-art in human pose by up to 2.4% and animal pose estimation by up to 3.1% for dogs and 1.4% for sheep.
Read more4/26/2024
✨
0
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
Jiawei Qin, Takuru Shimoyama, Xucong Zhang, Yusuke Sugano
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play significant roles in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, it shows that the model using only our synthetic training data can perform comparably to real data extended with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at https://github.com/ut-vision/AdaptiveGaze.
Read more7/9/2024
✨
0
RADA: Robust and Accurate Feature Learning with Domain Adaptation
Jingtai He, Gehao Zhang, Tingting Liu, Songlin Du
Recent advancements in keypoint detection and descriptor extraction have shown impressive performance in local feature learning tasks. However, existing methods generally exhibit suboptimal performance under extreme conditions such as significant appearance changes and domain shifts. In this study, we introduce a multi-level feature aggregation network that incorporates two pivotal components to facilitate the learning of robust and accurate features with domain adaptation. First, we employ domain adaptation supervision to align high-level feature distributions across different domains to achieve invariant domain representations. Second, we propose a Transformer-based booster that enhances descriptor robustness by integrating visual and geometric information through wave position encoding concepts, effectively handling complex conditions. To ensure the accuracy and robustness of features, we adopt a hierarchical architecture to capture comprehensive information and apply meticulous targeted supervision to keypoint detection, descriptor extraction, and their coupled processing. Extensive experiments demonstrate that our method, RADA, achieves excellent results in image matching, camera pose estimation, and visual localization tasks.
Read more7/23/2024
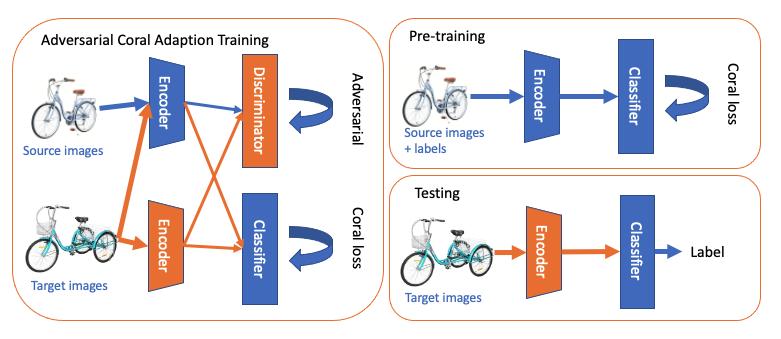
0
AD-Aligning: Emulating Human-like Generalization for Cognitive Domain Adaptation in Deep Learning
Zhuoying Li, Bohua Wan, Cong Mu, Ruzhang Zhao, Shushan Qiu, Chao Yan
Domain adaptation is pivotal for enabling deep learning models to generalize across diverse domains, a task complicated by variations in presentation and cognitive nuances. In this paper, we introduce AD-Aligning, a novel approach that combines adversarial training with source-target domain alignment to enhance generalization capabilities. By pretraining with Coral loss and standard loss, AD-Aligning aligns target domain statistics with those of the pretrained encoder, preserving robustness while accommodating domain shifts. Through extensive experiments on diverse datasets and domain shift scenarios, including noise-induced shifts and cognitive domain adaptation tasks, we demonstrate AD-Aligning's superior performance compared to existing methods such as Deep Coral and ADDA. Our findings highlight AD-Aligning's ability to emulate the nuanced cognitive processes inherent in human perception, making it a promising solution for real-world applications requiring adaptable and robust domain adaptation strategies.
Read more5/24/2024