Don't throw away your value model! Generating more preferable text with Value-Guided Monte-Carlo Tree Search decoding
2309.15028
0
0
👀
Abstract
Inference-time search algorithms such as Monte-Carlo Tree Search (MCTS) may seem unnecessary when generating natural language text based on state-of-the-art reinforcement learning such as Proximal Policy Optimization (PPO). In this paper, we demonstrate that it is possible to get extra mileage out of PPO by integrating MCTS on top. The key idea is not to throw out the value network, a byproduct of PPO training for evaluating partial output sequences, when decoding text out of the policy network. More concretely, we present a novel value-guided decoding algorithm called PPO-MCTS, which can integrate the value network from PPO to work closely with the policy network during inference-time generation. Compared to prior approaches based on MCTS for controlled text generation, the key strength of our approach is to reduce the fundamental mismatch of the scoring mechanisms of the partial outputs between training and test. Evaluation on four text generation tasks demonstrate that PPO-MCTS greatly improves the preferability of generated text compared to the standard practice of using only the PPO policy. Our results demonstrate the promise of search algorithms even on top of the aligned language models from PPO, and the under-explored benefit of the value network.
Create account to get full access
Overview
- Researchers demonstrate the benefits of combining Proximal Policy Optimization (PPO), a state-of-the-art reinforcement learning technique, with Monte-Carlo Tree Search (MCTS), a powerful inference-time search algorithm.
- They present a novel decoding algorithm called PPO-MCTS that integrates the value network from PPO training to work closely with the policy network during text generation.
- Evaluation on four text generation tasks shows that PPO-MCTS greatly improves the quality of the generated text compared to using only the PPO policy.
Plain English Explanation
Generating high-quality natural language text is a complex challenge in artificial intelligence. Recent advances in reinforcement learning, like Proximal Policy Optimization (PPO), have produced powerful language models capable of generating fluent and coherent text. However, these models can still struggle to produce text that is consistently "good" according to human evaluation.
The researchers in this paper had an intuition that additional techniques beyond just the PPO model could further improve text generation. Specifically, they explored integrating a search algorithm called Monte-Carlo Tree Search (MCTS) on top of the PPO model.
MCTS is a technique that explores many possible futures or "paths" to find the most promising one. The researchers hypothesized that by combining the strengths of the PPO model (which is great at generating fluent text) with the strategic exploration of MCTS, they could produce text that is even more preferred by humans.
The key idea is to not discard the "value network" that is learned as a byproduct of PPO training. This value network can provide useful evaluations of partial text sequences, which the MCTS algorithm can leverage to intelligently explore the space of possible text continuations.
The researchers call their combined approach "PPO-MCTS", and they show through experiments on various text generation tasks that it outperforms using just the PPO model alone. Essentially, they've found a way to get "extra mileage" out of the PPO model by integrating a powerful search technique on top of it.
Technical Explanation
The core technical contribution of this paper is the PPO-MCTS decoding algorithm, which integrates MCTS on top of a PPO-trained language model.
Typically, when generating text using a PPO model, the generation process would simply use the policy network to sequentially sample the most likely next tokens. In contrast, the PPO-MCTS approach uses the MCTS algorithm to intelligently explore the space of possible text continuations.
The key insight is to leverage the "value network" that is learned during PPO training. This value network provides an estimate of the reward (or "value") of a given partial text sequence. PPO-MCTS uses this value network to guide the MCTS search, helping it focus on the most promising continuations.
Specifically, the PPO-MCTS algorithm works as follows:
- It starts with a partially generated text sequence.
- It then uses MCTS to explore many possible ways of continuing that sequence, evaluating each continuation using both the PPO policy network (to ensure fluency) and the PPO value network (to estimate the overall quality).
- After exploring these possibilities, PPO-MCTS selects the most promising next token to append to the sequence.
- This process then repeats, with the algorithm continuing to grow and refine the text sequence.
The researchers demonstrate the effectiveness of PPO-MCTS through experiments on four different text generation tasks, including open-ended story generation and controlled text generation. Across these tasks, they show that PPO-MCTS significantly outperforms using just the PPO policy network alone, as measured by human evaluations of the generated text.
Critical Analysis
The researchers present a compelling approach that demonstrates the benefits of integrating search algorithms like MCTS with state-of-the-art language models trained via reinforcement learning. However, the paper does not address some potential limitations and areas for further research.
For example, the experiments are limited to relatively short text generation tasks (up to 50 tokens). It's unclear how well the PPO-MCTS approach would scale to longer-form text generation, where the search space becomes exponentially larger. The authors acknowledge this as a potential challenge that requires further investigation.
Additionally, the paper does not provide a detailed analysis of the computational cost and runtime overhead of the PPO-MCTS algorithm compared to simpler text generation approaches. This information would be valuable for assessing the practical feasibility and deployability of the technique.
Another area for further research is the extent to which the benefits of PPO-MCTS are dependent on the specific PPO model used. The paper uses a PPO model trained on the WebText dataset, but it's unclear if the gains would generalize to PPO models trained on other datasets or with different hyperparameter settings.
Despite these limitations, the paper makes a compelling case for the potential of integrating search algorithms with powerful language models. By better leveraging the value network learned during training, the PPO-MCTS approach demonstrates meaningful improvements in the quality and preferability of generated text. This suggests there may be further untapped benefits in the value network that warrant exploration.
Conclusion
This paper presents a novel text generation algorithm called PPO-MCTS that combines the strengths of Proximal Policy Optimization (PPO) and Monte-Carlo Tree Search (MCTS). By integrating the value network learned during PPO training, PPO-MCTS is able to generate text that is significantly preferred by human evaluators compared to using the PPO policy network alone.
The key insight is that the value network, typically discarded after training, can provide valuable guidance to the MCTS search process, helping it focus on the most promising text continuations. This integration of a powerful language model (PPO) with a strategic search algorithm (MCTS) represents an important step forward in advancing the state of the art in natural language generation.
While the paper highlights some limitations that require further research, the results demonstrate the promise of such hybrid approaches that leverage the complementary strengths of different AI techniques. As language models continue to advance, finding ways to combine them with strategic search and planning algorithms may be a fruitful direction for unlocking even more impressive text generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024

Step-level Value Preference Optimization for Mathematical Reasoning
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
0
0
Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
6/18/2024
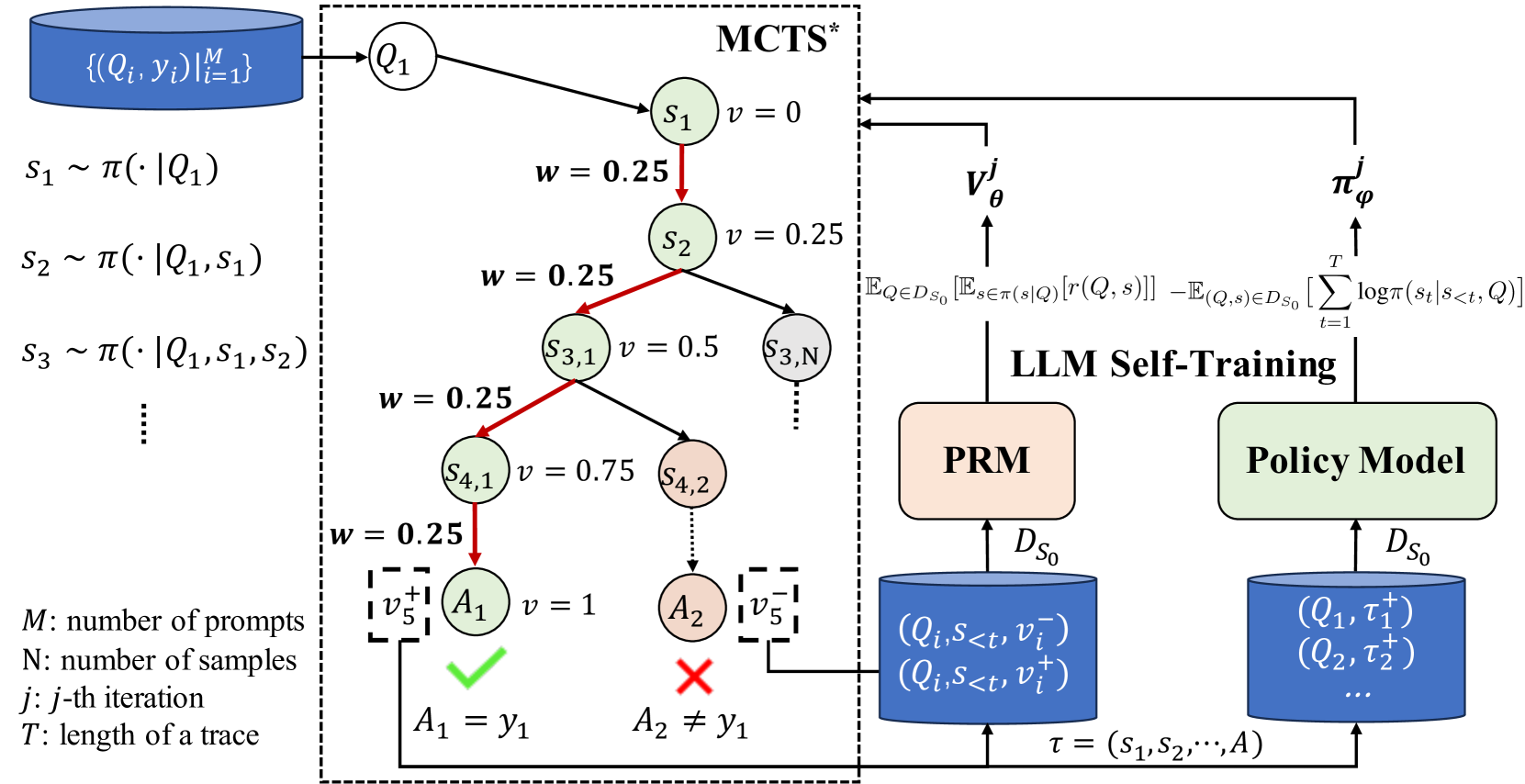
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Dan Zhang, Sining Zhoubian, Yisong Yue, Yuxiao Dong, Jie Tang
0
0
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
6/7/2024
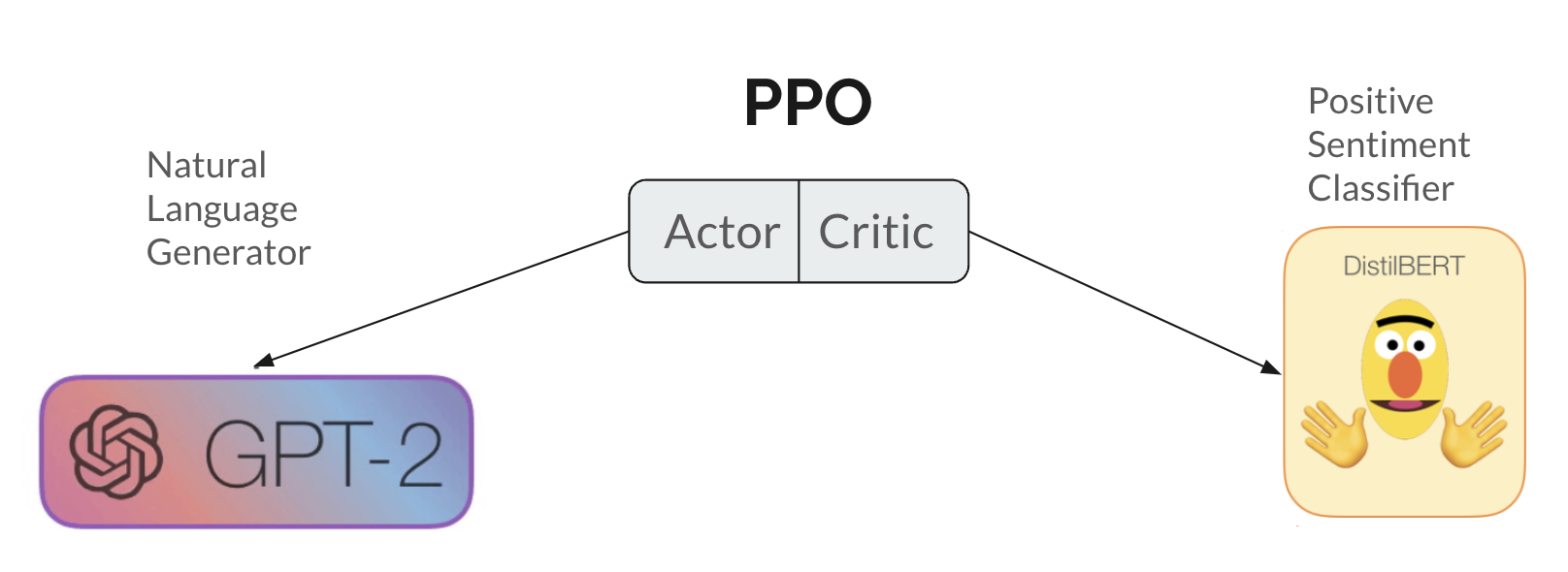
Are PPO-ed Language Models Hackable?
Suraj Anand, David Getzen
0
0
Numerous algorithms have been proposed to $textit{align}$ language models to remove undesirable behaviors. However, the challenges associated with a very large state space and creating a proper reward function often result in various jailbreaks. Our paper aims to examine this effect of reward in the controlled setting of positive sentiment language generation. Instead of online training of a reward model based on human feedback, we employ a statically learned sentiment classifier. We also consider a setting where our model's weights and activations are exposed to an end-user after training. We examine a pretrained GPT-2 through the lens of mechanistic interpretability before and after proximal policy optimization (PPO) has been applied to promote positive sentiment responses. Using these insights, we (1) attempt to hack the PPO-ed model to generate negative sentiment responses and (2) add a term to the reward function to try and alter `negative' weights.
6/6/2024